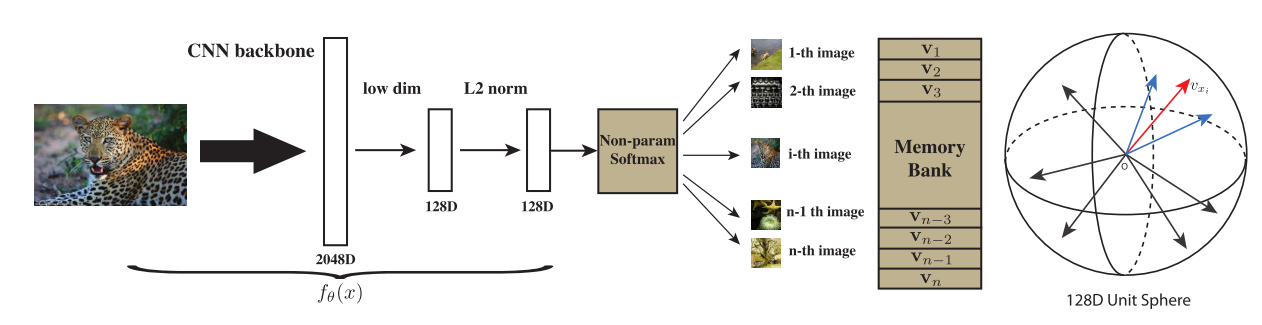
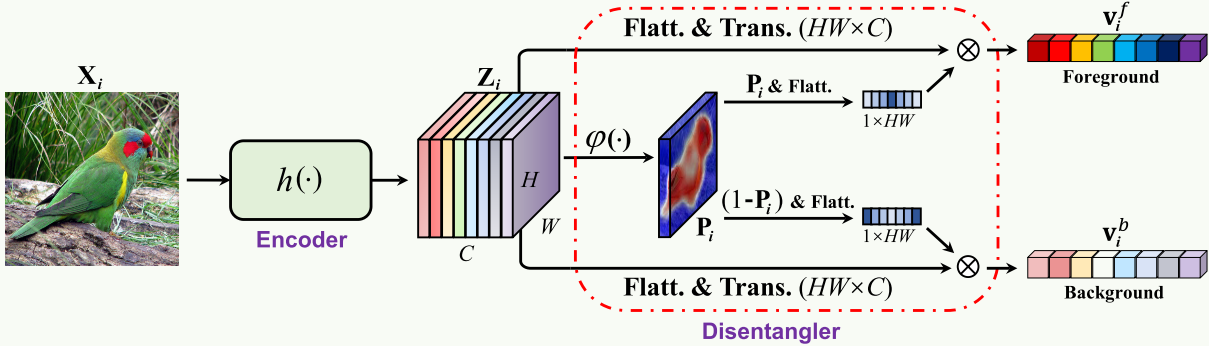
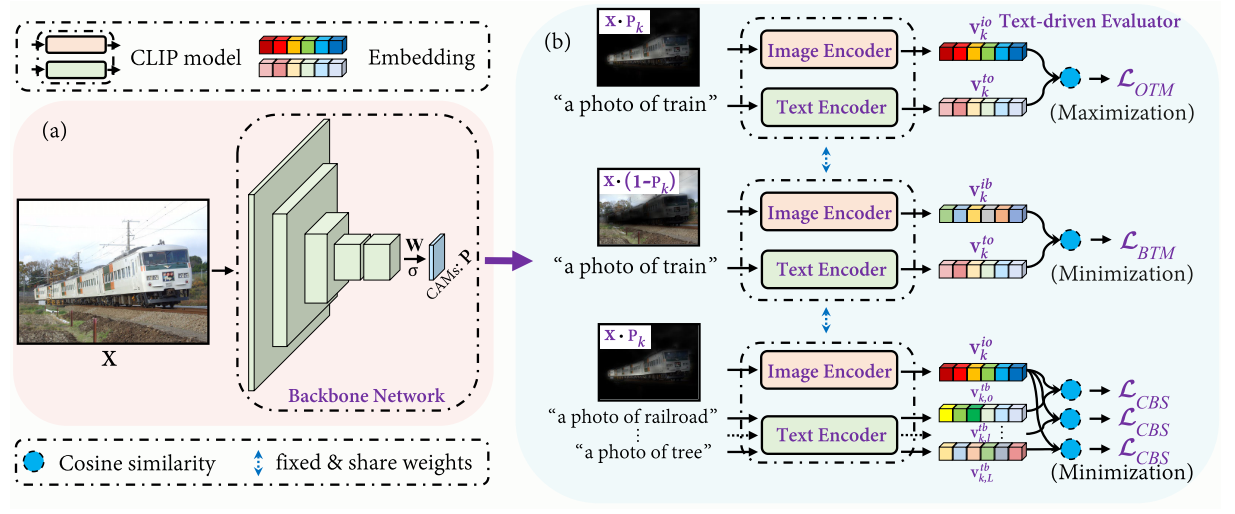
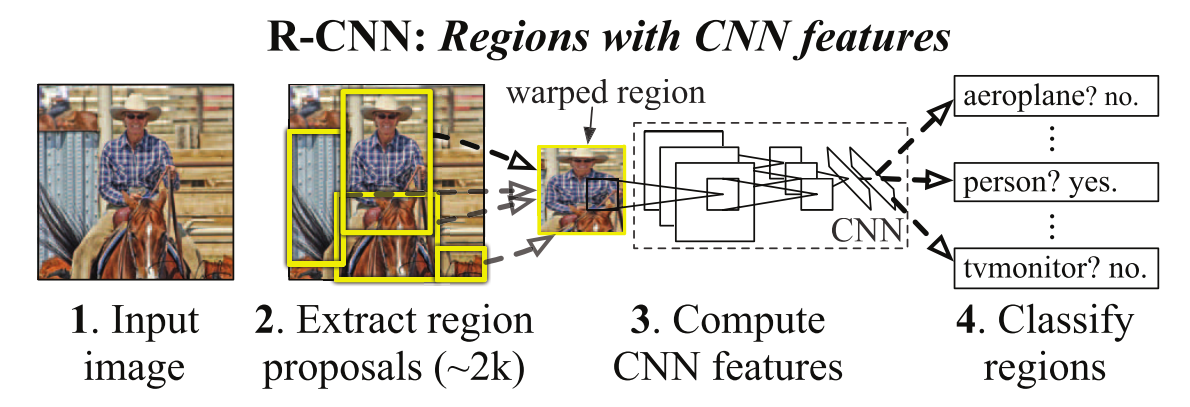
Few-Shot Learning
support set不足以训练神经网络,只是在做预测的时候提供一些额外信息。使用大的数据集来训练一个模型,训练目的是让模型知道事物的异同
小样本学习也是一种meta learning,learning to learn
与监督学习的区别:
传统的监督学习的测试样本来自于已知类别,few-shot learning的测试样本来自未知的类别
k-way n-shot:
- k-way:support set有k个类别
- n-shot:每个类别有n个样本,one-shot就是只有一张图片
与比赛不同,few shot learning中,设定query是属于surrport set的,而比赛中是需要判断是不是已知类的
siamese网络的训练:
- 使用正负对进行训练,正对(同一类别)的两个样本的相似度标记为1,负对为0.将样本对输入到同一个网络,提取特征,对特征求差值,得到的特征向量表示两个图片得到的特征向量的区别,然后再送进全连接层,得到一个标量,加上sigmoid进行归一化,得到一个表示similarity的预测值,使用预测值sim和标签(正对为1,负对为0)做crossentropy
- 使用triplet loss,训练时每次选取3个样本,一个anchor,一个positive,一个negative,让anchor和positive在特征空间的距离更近,anchor和negative在特征空间的距离更远