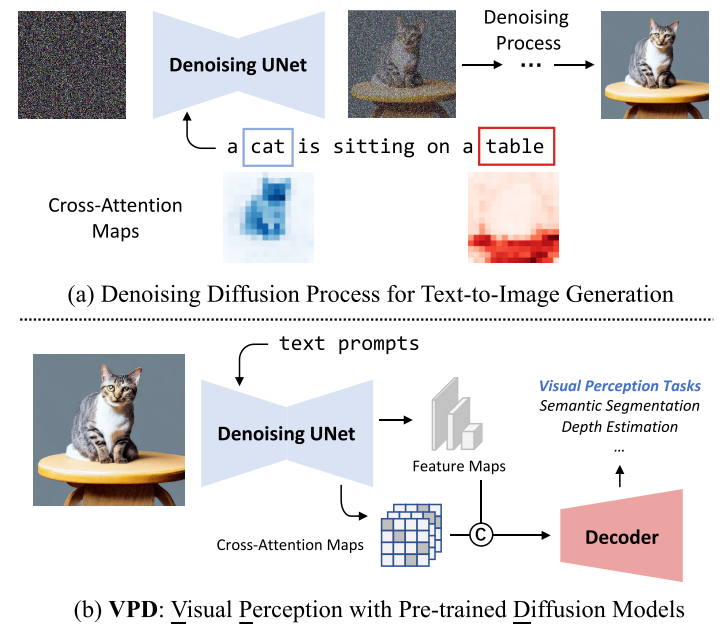
VPD (Visual Perception with a pre-trained Diffusion model)
如何利用大规模数据预训练的Diffusion model来支持下游的Visual perception 任务
Motivation
text-to-image diffusion model通过视觉语言预训练获得了更多的high-level knowledge,大规模text-to-image diffusion model能够生成纹理丰富、内容多样、结构合理的高质量图像,同时具有可组合、可编辑的语义。这一现象暗示了大规模的文本-图像扩散模型可以从大量的图像-文本对中隐式地学习高层次和低层次的视觉概念。
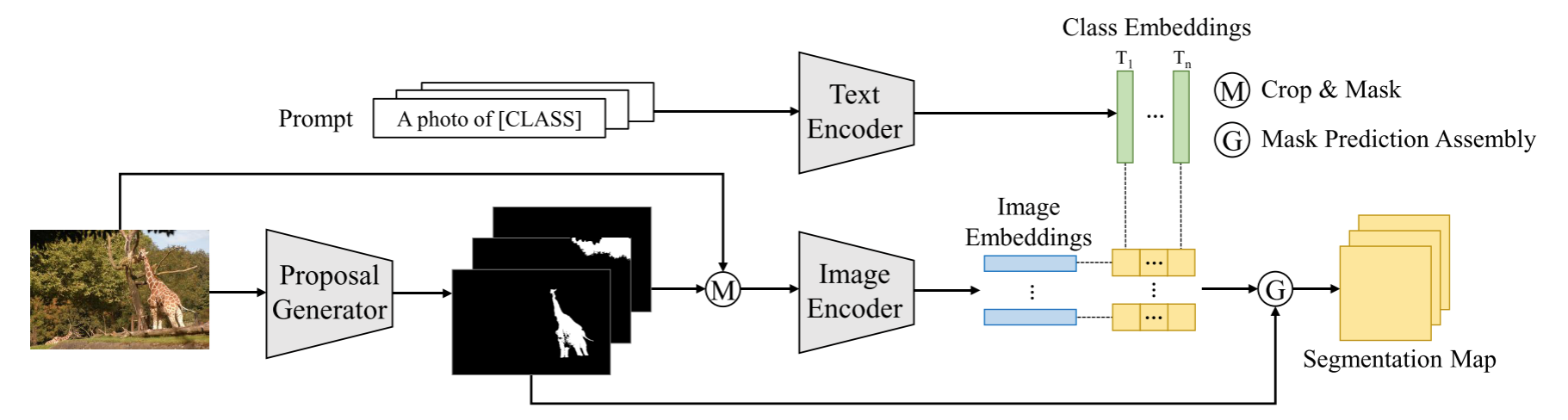
本文旨在研究提取大规模扩散模型所学习到的视觉知识来支持下游的Visual perception 任务。作者提出的VPD框架探索了如何利用pre-trained denoising UNet去为下游视觉感知任务提供语义引导。
与将知识从常规的预训练模型转移到下游视觉感知任务相比,对diffusion model进行transfer learning存在两个挑战:
- diffusion model和视觉感知任务之间的不兼容性
- UNet类扩散模型和流行视觉backbone之间的架构差异