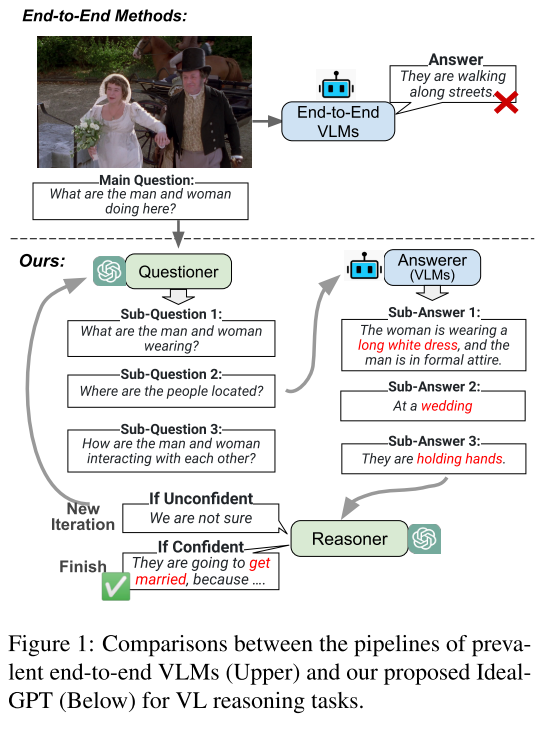
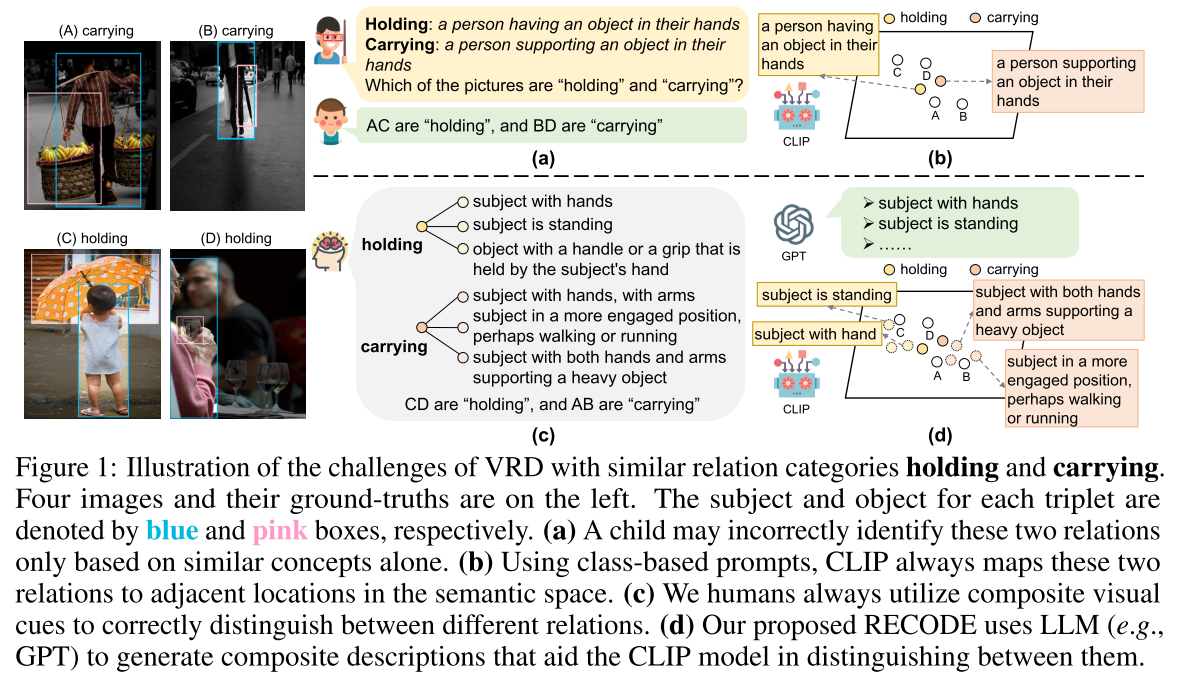
Towards Open Vocabulary Learning: A Survey
Motivation&Background
Zero-Shot Learning(ZSL)缺少对不可见对象的示例,且在训练期间会将不可见类对象视作背景对象,因此,在推理过程中,模型仅基于其预定义的词嵌入来识别新类别,从而限制了对视觉信息和那些看不见的类别的关系的挖掘。
ZSL和open vocabulary之间的关键区别在于,open vocabulary可以使用视觉相关的语言词汇比如image captions来作为辅助的监督,使用语言来作为辅助的弱监督的motivations包括:
- 相比于box和mask annotation,language data易于获取,标注成本低
- language data提供了更大的词汇量,因此可以更容易地拓展,具有更强地泛化性
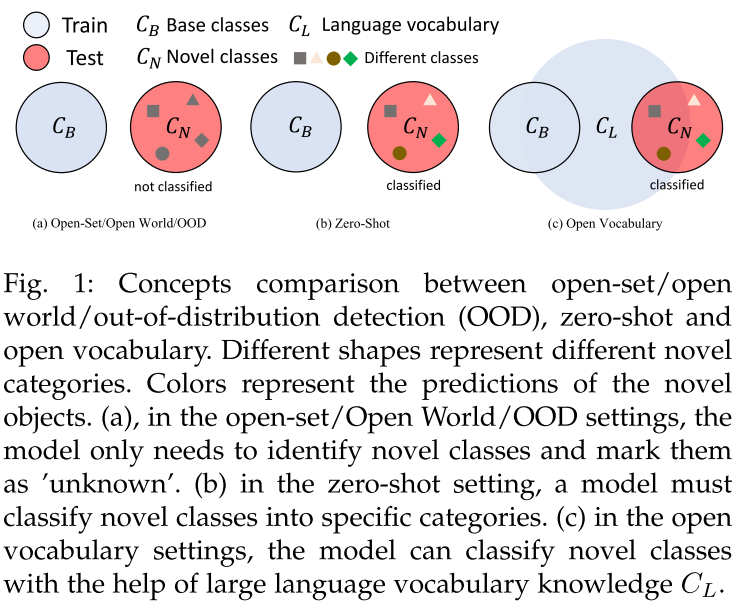
- Open-Set/Open World/OOD:只需要识别出unknown objects,而不需要将它们分到不同的具体类
- Zero-Shot Learning:模型严格在base类上进行训练,novel类在训练时是不可见的,且模型需要为novel类预测具体类别
- Open Vocabulary Learning