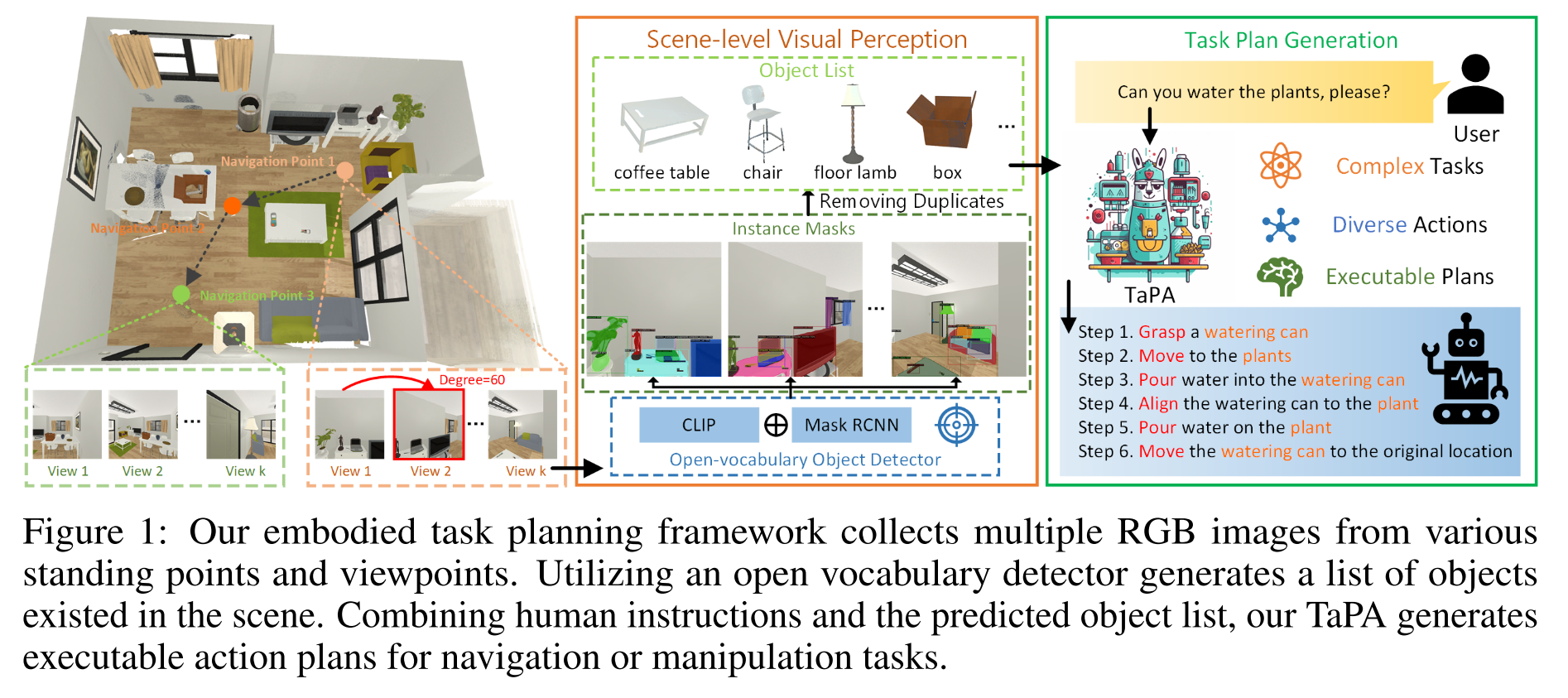
TaPA
Embodied Task Planning with Large Language Models
基于LLMs的具身任务规划
Motivation
受限于数据样本和多样的下游应用,直接在不同的应用环境训练同一个agent是不现实的。LLMs可以在复杂任务的plan generation中为agent提供丰富的语义知识,但LLMs无法感知周围环境,缺乏真实世界的信息,常常会产生无法执行的action sequences。
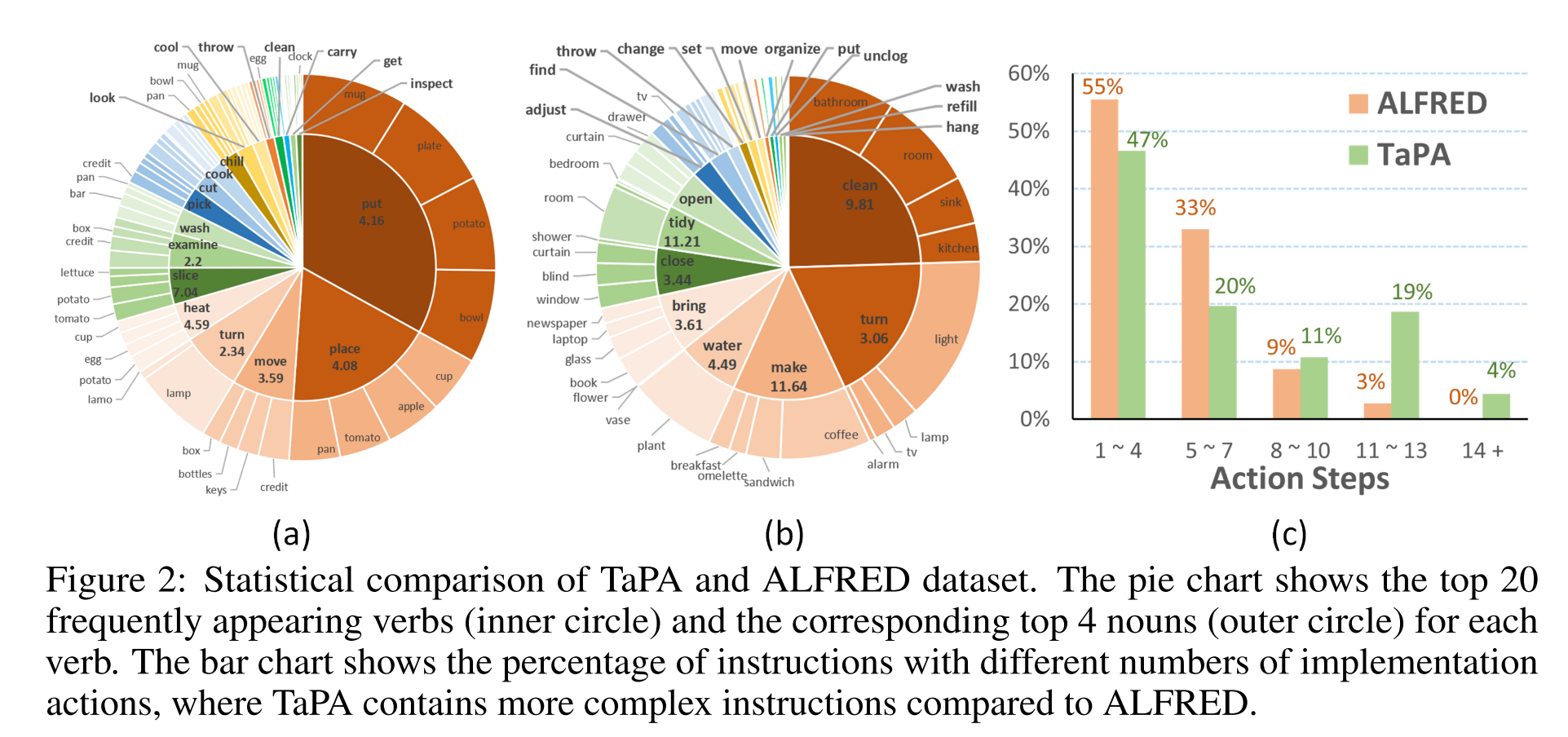
本文中关注的“不可执行的action”主要指LLMs给出的action提及了不存在的物体,比如人类指令是”Give me some wine”,GPT-3.5产生的action steps为”pouring wine from the bottle to the glass”,但实际的场景中可能并没有”glass”,只有”mug”, 实际上可以执行的指令是”pouring wine from the bottle to the mug”
- construct a multimodal dataset containing triplets of indoor scenes, instructions and action plans
- designed prompts+the list of existing objects in the scene输入到GPT3.5,得到instructions和对应的action plans
- The generated data is leveraged for grounded plan tuning of pre-trained LLMs
从周围环境接收信息
- [37] A persistent spatial semantic representation for high-level natural language instruction execution
- [38] Piglet: Language grounding through neuro-symbolic interaction in a 3d world
- [39] Grounding language to autonomously-acquired skills via goal generation
prompt engineering
设计任务指令和相应动作的简单示例来对LLMs进行提示,以产生合理的任务计划,并通过构建具有语义相似性的映射来过滤出可执行计划子集
- [40] Language models as zero-shot planners: Extracting actionable knowledge for embodied agents
根据action feedback为复杂任务生成决策
- [41] Pre-trained language models for interactive decision-making
SayCan和LLM-Planner都通过提取场景的latent features或物体名称来为LLMs提供视觉信息
SayCan只能完成在厨房场景下的任务
LLM-Planner在ALFRED simulator中实现,大部分任务都非常简单,如putting and placing
- [14] Do as i can, not as i say: Grounding language in robotic affordances
- [15] Llm-planner: Few-shot grounded planning for embodied agents with large language models
Methodology