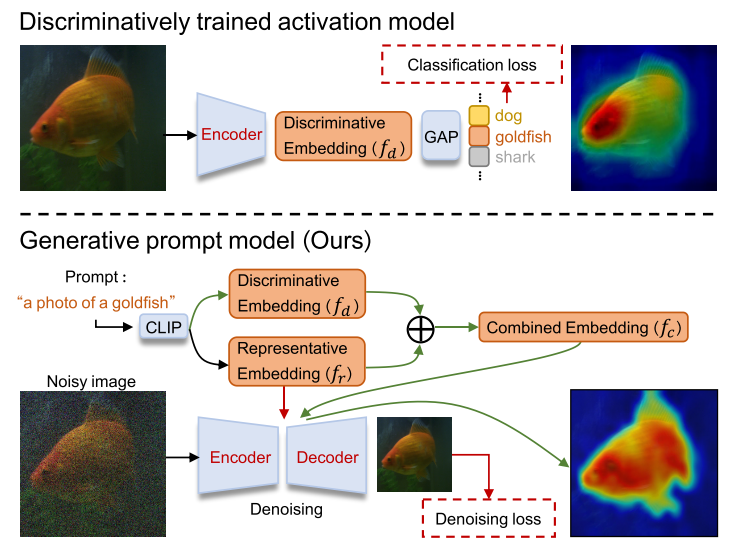
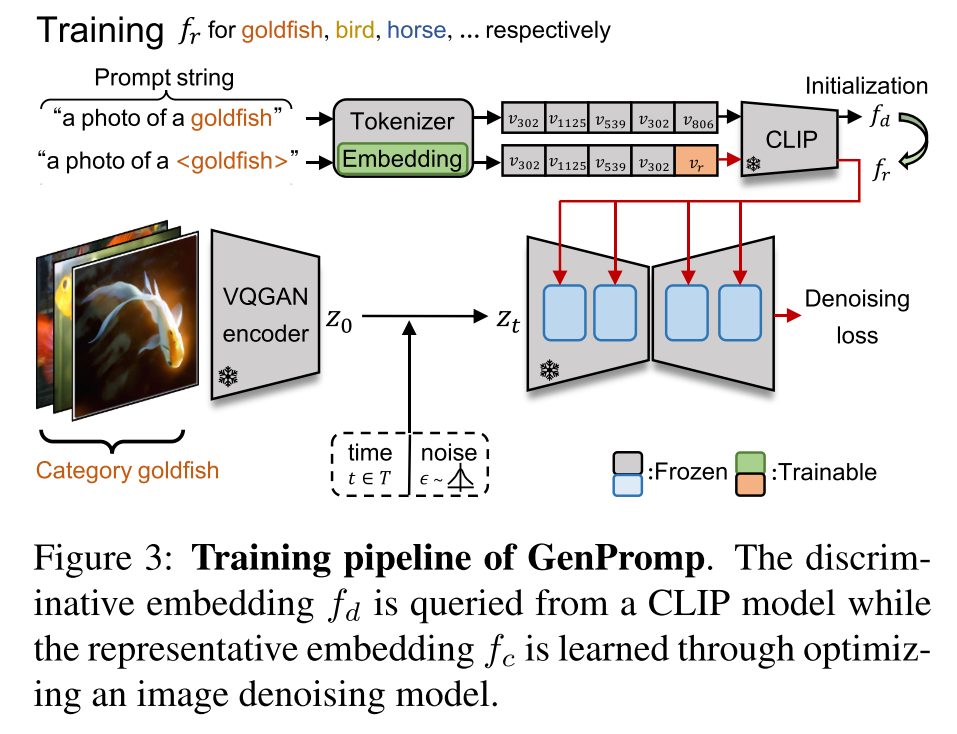
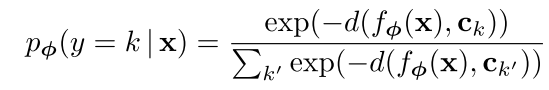Generative Prompt Model for Weakly Supervised Object Localization
HomeRobot: Open-Vocabulary Mobile Manipulation
HomeRobot: Open-Vocabulary Mobile Manipulation
Open-Vocabulary Mobile Manipulation (OVMM) is the problem of picking any object in any unseen environment, and placing it in a commanded location.
OVMM涉及到了感知、语言理解、导航和操作
an agent navigates household environments to grasp novel objects and place them on target receptacles


A Survey on Open-Vocabulary Detection and Segmentation: Past, Present, and Future
3D-Aware Object Goal Navigation via Simultaneous Exploration and Identification
3D-Aware Object Goal Navigation via Simultaneous Exploration and Identification
ObjectNav旨在使agent在unseen and unmapped scene下寻找一个特定类别的物体
Motivation
现有的工作主要通过端到端的reinforcement learning或者modular-based methods来解决这一问题
端到端的RL方法以图像序列作为输入,然后直接输出low-level的导航信息,但是受限于低的采样效率和较差的跨数据集泛化性。
modular-based methods通常包含:
- semantic scene mapping module,用于聚合RGBD观察和来自语义分割网络的输出以形成语义场景图(semantic scene map)
- RL-based goal policy module,这一模块将语义场景图(semantic scene map)作为输入,并学习在线更新目标位置
- local path planning module,用于驱动agent到达目标位置
现有的modular-based methods主要构建2D maps,scene graphs或neural fields来作为scene maps,这类构建方式都没有很好的利用环境的3D的空间信息。
使用3D场景表示可以自然的提高ObjectNav在3D场景中的表现,但是3D scene representation会为ObjectNav policy learning带来挑战:
- 构建和查询跨楼层场景的细粒度3D表示需要大量的计算成本,这会显著减慢RL的训练
- 3D场景表示相对2D来说,带来了更复杂和更高维的观察,导致较低的采样效率并阻碍navigation policy的学习
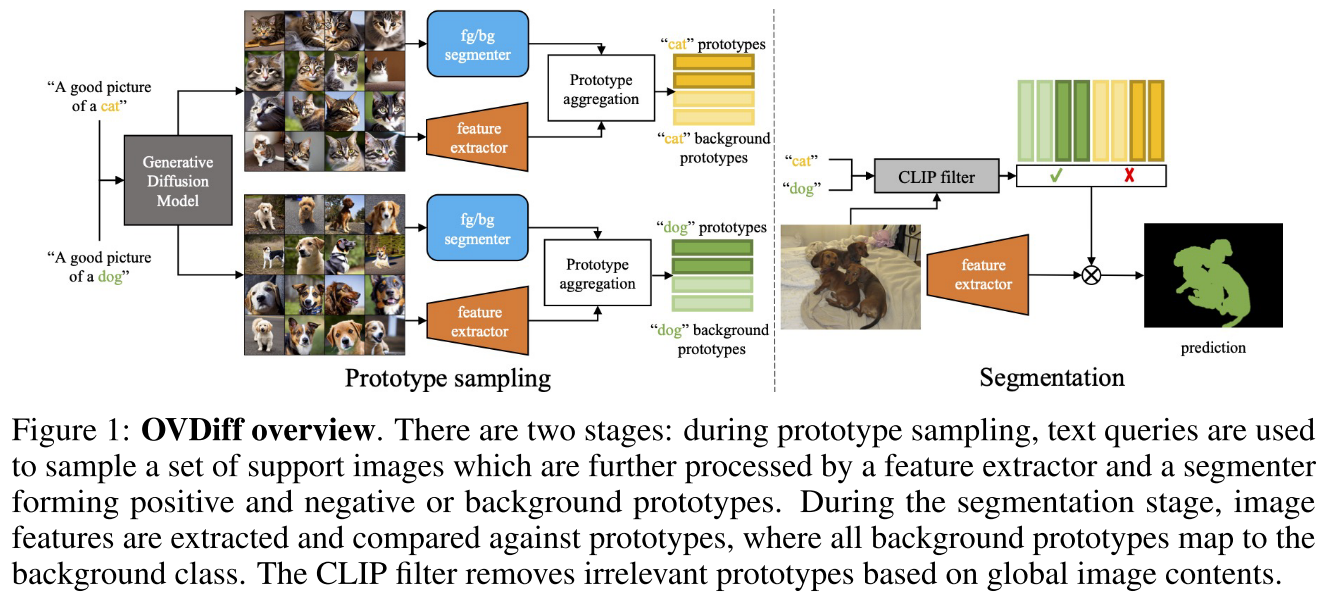
Diffusion Models for Zero-Shot Open-Vocabulary Segmentation
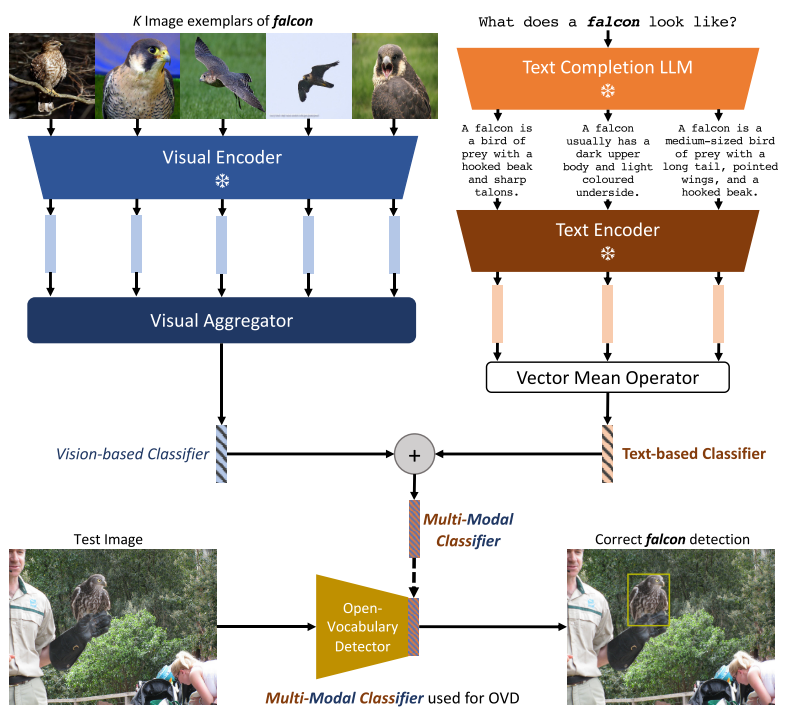
Multi-Modal Classifiers for Open-Vocabulary Object Detection
MM-OVOD
Multi-Modal Classifiers for Open-Vocabulary Object Detection
Motivation
直接用类别名加模板送入pretrained text encoder,然后用text embbeding代替传统检测器中的分类器的方法存在3个弊端:
- 可能存在语义歧义,且完全依赖预训练的文本编码器对于class name的内部表征,无法区分同一词汇表示的多种概念
- 有的情况下用户并不知道class name,反而exemplar images更容易获取
- 多模态输入时,exemplar images可以作为文本描述的很好的补充(比如复杂的图案,文本难以描述,但图像更直观)
Methodology
使用Detic作为baseline,centernet2作为检测器
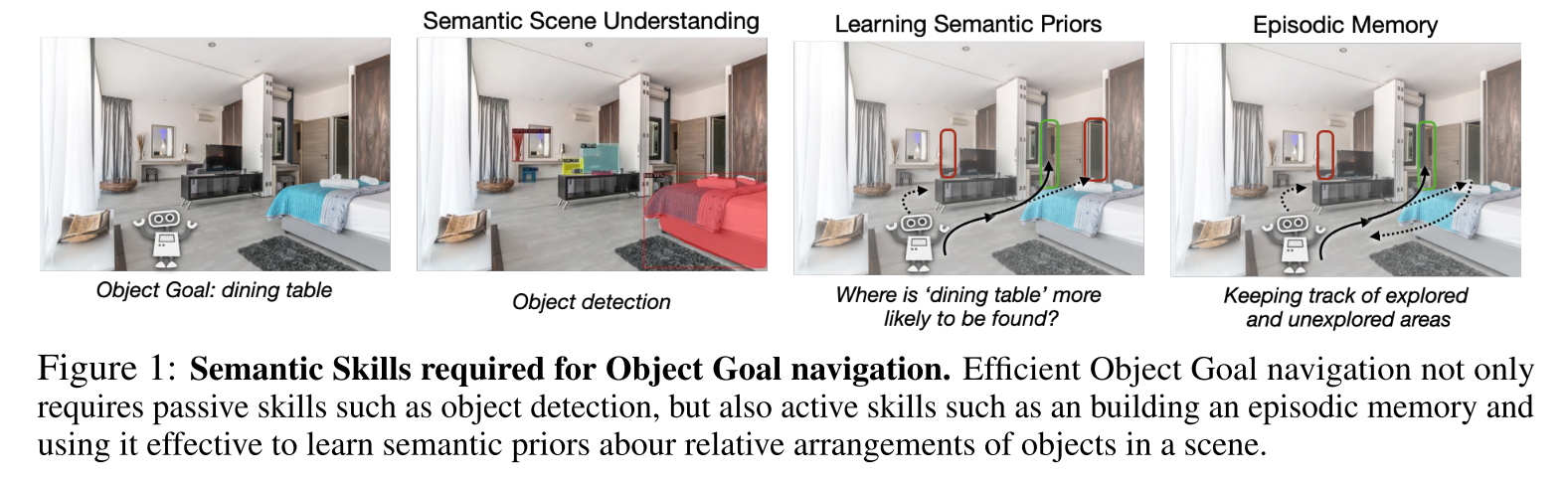
Object Goal Navigation using Goal-Oriented Semantic Exploration
Object Goal Navigation using Goal-Oriented Semantic Exploration
Motivation
object goal navigation:在未知环境中导航到一个给定物体类别的实例对象位置
假设要求agent在未知环境中导航到“dining table”,在语义理解方面,该任务不仅涉及对象检测,即“dining table”看起来像什么,但也要了解“dining table”在哪里更有可能被找到。
- long-term episodic memory可以使agent有效探索和跟踪环境
- 学习语义先验可以使agent使用episodic memory来决定接下来探索哪个区域,以便在最少的时间内找到目标对象。
Few-Shot Learning
Prototypical Networks for Few-shot Learning
- 对于分类问题,原型网络将其看做在语义空间中寻找每一类的原型中心。
- 针对Few-shot的任务定义,原型网络训练时学习如何拟合中心。学习一个度量函数,该度量函数可以通过少量的几个样本找到所属类别在该度量空间的原型中心。
- 测试时,用支持集(Support Set)中的样本来计算新的类别的聚类中心,再利用最近邻分类器的思路进行预测。本文主要针对Few-Show/Zero-Shot任务中过拟合的问题进行研究,将原型网络和聚类联系起来,和目前的一些方法进行比较,取得了不错的效果。
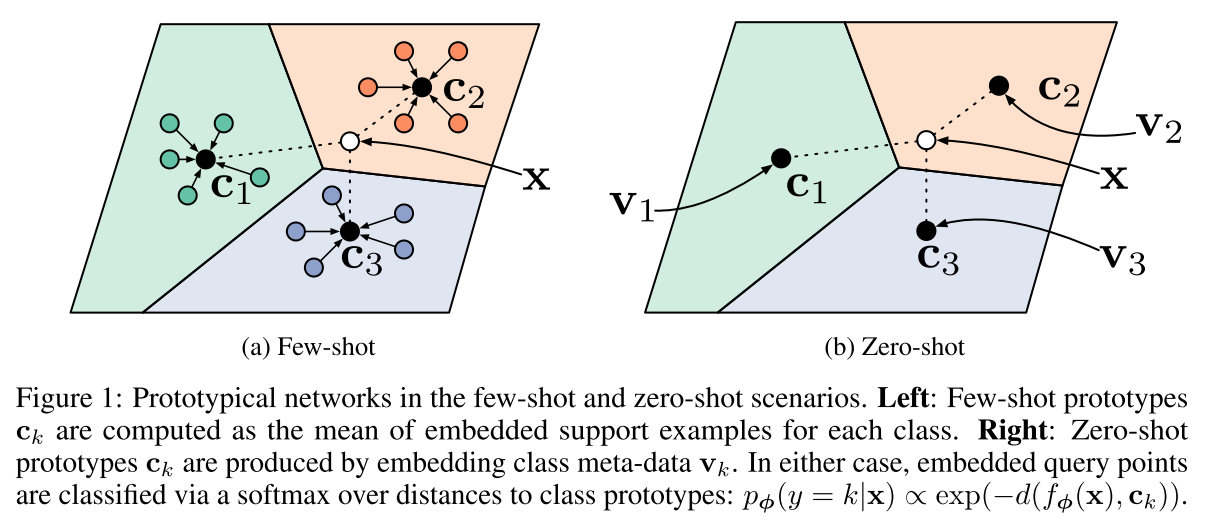
- $C_k$代表类的原型,是支持集样本embedding的均值向量
- $S_k$代表支持集中每个类的样本
$\mathbf{c}_{k}=\frac{1}{\left|S_{k}\right|} \sum_{\left(\mathbf{x}_{i}, y_{i}\right) \in S_{k}} f_{\phi}\left(\mathbf{x}_{i}\right)$
- 计算query instance和各个类原型间的距离,通过softmax得到分类概率分布