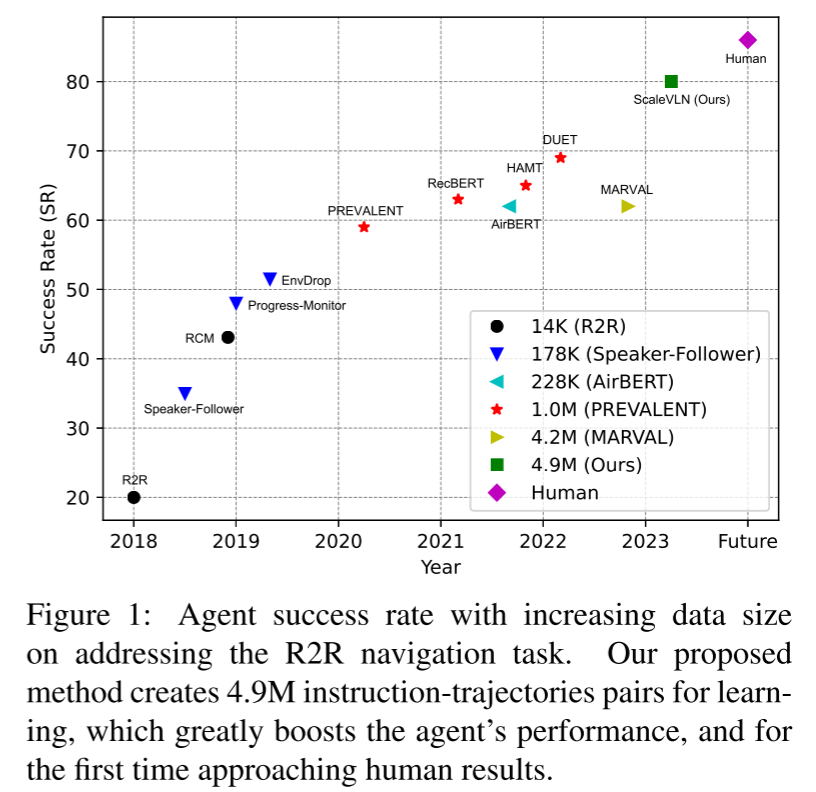
ScaleVLN
Scaling Data Generation in Vision-and-Language Navigation
Related Work
Pre-exploration
[26] Counterfactual vision-and-language navigation via adversarial path sampler. In European Conference on Computer Vision, pages 71–86. Springer, 2020. 2
[72] Learning to navigate unseen environments: Back translation with environmental dropout
[90] Vision-language navigation with self-supervised auxiliary reasoning tasks.
VLN cotinuous environments(R2R-CE)
[5] 1st place solutions for rxr-habitat vision-and-language navigation competition (cvpr 2022)
[30] Bridging the gap between learning in discrete and continuous environments for vision-and-language navigation
[40] Simple and effective synthesis of indoor 3d scenes. arXiv preprint arXiv:2204.02960, 2022. 2