CLIP on Wheels (CoW)
CoWs on PASTURE: Baselines and Benchmarks for Language-Driven Zero-Shot Object Navigation
For robots to be generally useful, they must be able to find arbitrary objects described by people (i.e., be language-driven) even without expensive navigation training on in-domain data (i.e., perform zero-shot inference).
language-driven zero-shot object navigation (L-ZSON)
PASTURE benchmark considers finding uncommon objects, objects described by spatial and appearance attributes, and hidden objects described relative to visible objects

- A collection of baseline algorithms, CLIP on Wheels (CoW), which adapt open-vocabulary models to the task of L-ZSON.
- A new benchmark, PASTURE, to evaluate CoW and future methods on L-ZSON, We consider the ability to find:
- uncommon objects (e.g., “tie-dye surfboard”)
- objects by their spatial and appearance attributes in the presence of distractor objects (e.g., “green apple” vs. “red
apple”)
- objects that cannot be visually observed(e.g., “mug under the bed”).
Zero-shot object navigation (ZSON)
agents are evaluated on object categories that they are not explicitly trained on
Both algorithms necessitate navigation training for millions of steps and train separate models for each simulation domain.
[44] Zson: Zero-shot object-goal navigation using multimodal goal embeddings
[37] Simple but effective: Clip embeddings for embodied ai
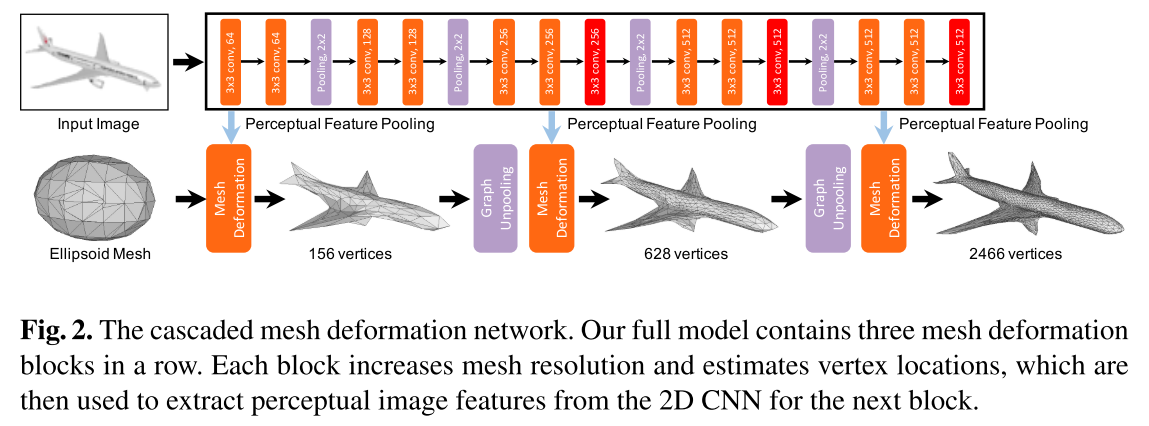
CLIP on Wheels (CoW) Baselines
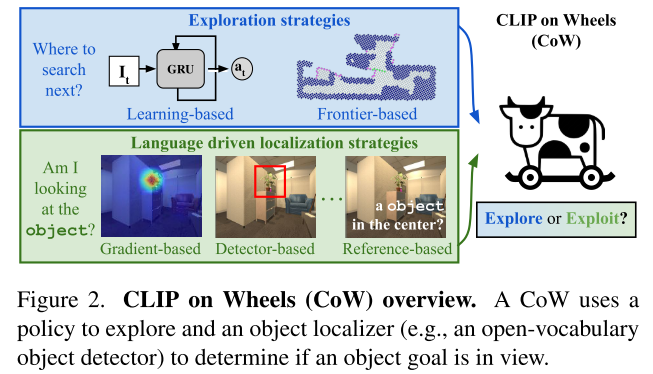
Depth-based Mapping
0.125m分辨率的地图
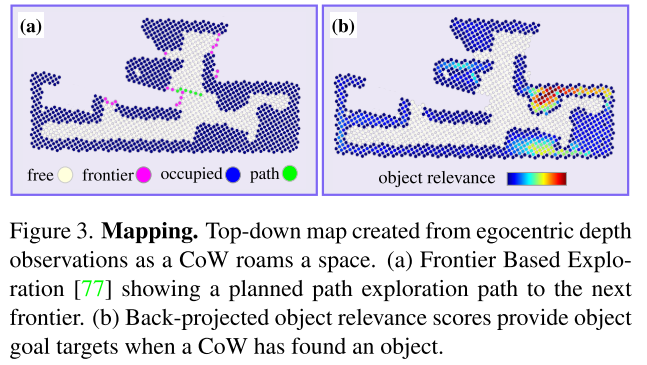
Exploration
- Frontier based exploration (FBE)
- move to the frontier between free and unknown space to discover new regions. Once the navigator reaches a frontier, it moves greedily to the next closest frontier.
- Learnable exploration
Object Localization
- CLIP with k referring expressions
- CLIP with k image patches
- CLIP with gradient relevance
- MDETR segmentation
- OWL-ViT detection
- Post-processing
- Target driven planning
The PASTURE Benchmark
PASTURE builds on ROBOTHOR validation scenes
PASTURE evaluates seven core L-ZSON capabilities:
Uncommon objects.
Traditional benchmarks (e.g.,ROBOTHOR and HABITAT MP3D)主要在常见类别上进行评估,但家用环境中物体是非常多样的,因此作者添加了12 new objects to each room.
We use names shown in Fig. 4 as instance labels, which are minimal descriptions to identify each object. Some identifiers refer to text in images (e.g., “whiteboard saying CVPR”) or to appearance attributes (e.g., “wooden toy airplane”). Other objects are less common in North America, like “mat´e”, which is a popular Argentinian drink.

Appearance descriptions.
对visual attributes的感知能力
“{size}, {color}, {material} {object}”. For example: “small, red apple”, “orange basketball”, “small, black, metallic alarm clock”.
Spatial descriptions.
对spatial information的感知能力
“{object} on top of {x}, near {y}, {z}, …”. For example, “house plant on a dresser near a spray bottle”. To determine [on top of] relations, we use THOR metadata and to determine [nearness] we use a distance threshold between pairs of objects.
Appearance descriptions with distractors.
有干扰物出现的情况
For example, for the task of finding a “red apple”, we have both a red apple and a green apple in the room.
Spatial descriptions with distractors.
有干扰物出现
Hidden object descriptions.
An ideal object navigator should find objects, even when they are hidden.
“{object} under/in {x}”. For example, “basketball in the dresser drawers” or “vase under the sofa”. We sample large objects (e.g., beds, sofas, dressers) in each scene to determine [under/in] relations. Additionally we remove visible instances of {object} from the room.
Hidden object descriptions with distractors.
Consider finding a “mug under the bed”. A distractor mug will also appear in the scene making the task more challenging.
Experiments