CVPR2018 ACoL
Adversarial Complementary Learning for Weakly Supervised Object Localization
对抗性互补学习弱监督目标定位
策略
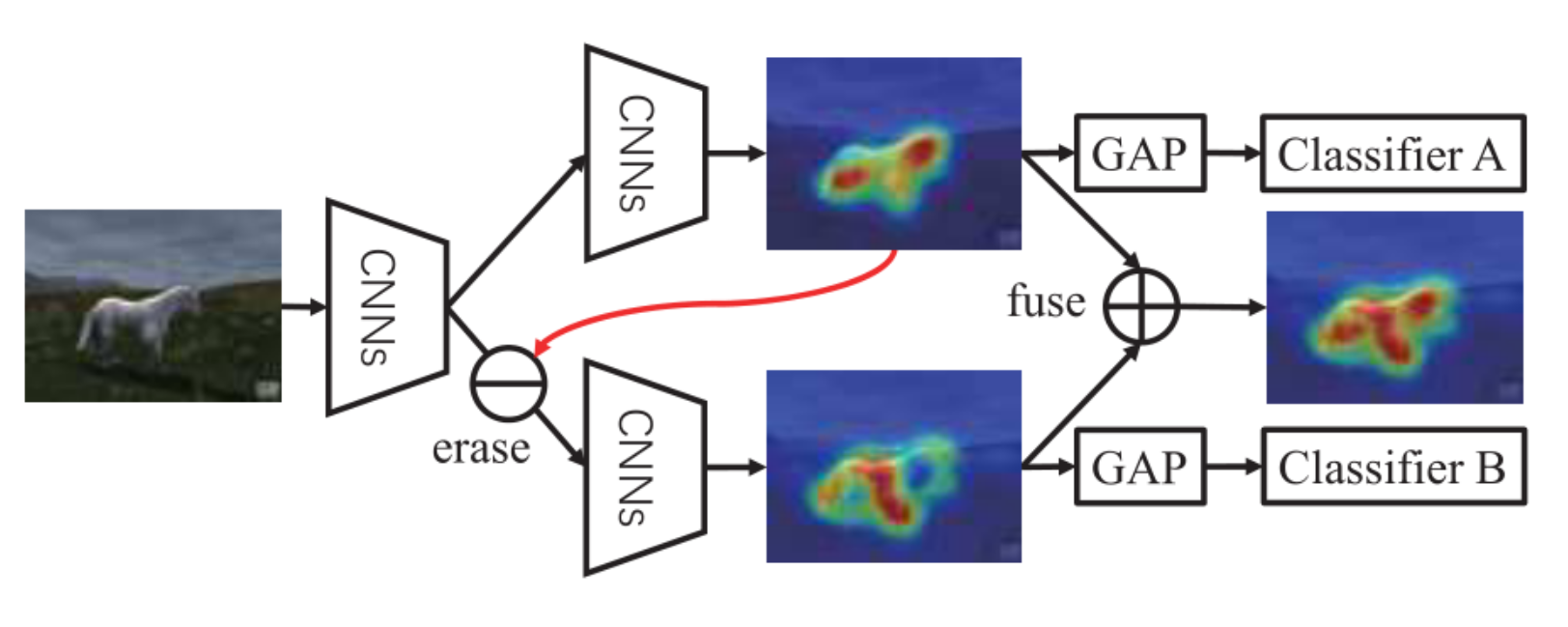
使用两个分类器
分类器 A 利用判别性区域(马的头部和后腿)进行识别。通过擦除特征图中的此类判别区域,作为分类器 B的输入,分类器B被引导使用新的和互补对象区域(马的前腿)的特征进行分类。最后,通过融合来自两个分支的目标定位图获得最终的目标区域。
Attention-based Dropout Layer for Weakly Supervised Object Localization
仅使用图像级标签来学习对象的位置,不使用位置标注
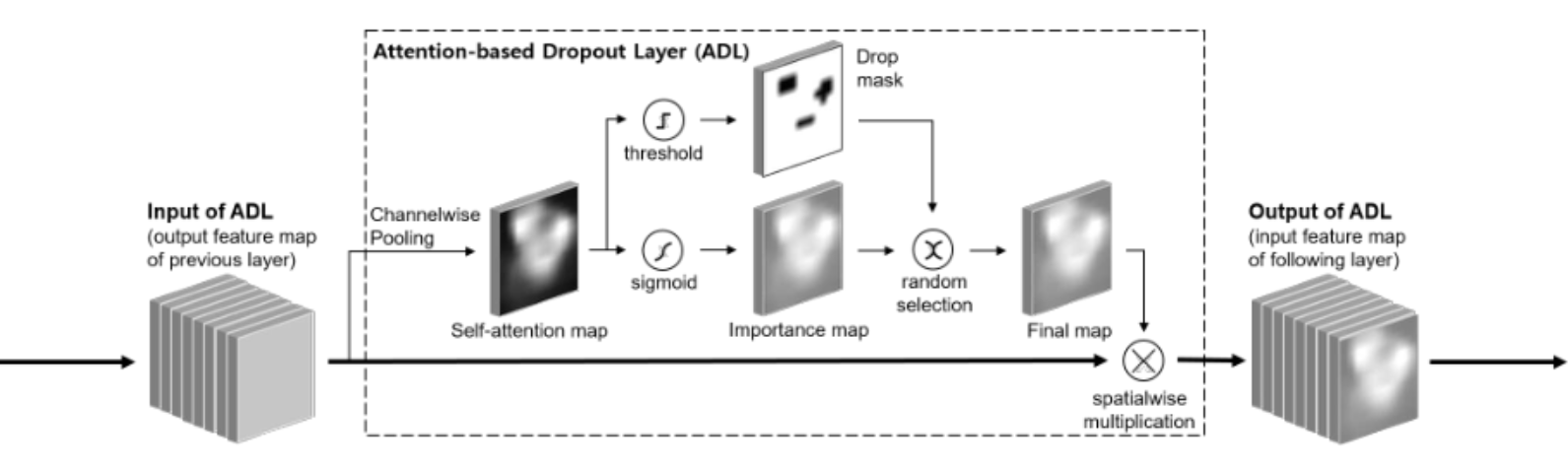
将feature map通过Channelwise Pooling生成Self-attention map
从Self-attention map中获得2个掩码:
随机选择其中一个掩码,作为当前iteration的掩码
Drop mask会遮盖掉最具判别性的区域,使网络获取目标的整体范围,提高localization accuracy
Importance map会突出信息区域以提高模型的识别能力,提高classification能力
Erasing Integrated Learning : A Simple yet Effective Approach for Weakly Supervised Object Localization
基于分类网络的WSOL方法通常会突出显示最具辨别力的部分,而不是对象的整个范围。然而,试图探索对象的整体范围反而会降低图像分类的性能。
CAM定位得到的往往是对应类别最具判别性的部分,对抗擦除技术用于缓解这一问题
ADL随机擦除前向传播中最具辨别力的区域,节省了相当多的计算和参数开销。但ADL 仍然受到信息区域随机丢失引起的分类退化的限制。当 ADL 插入网络时,它随机选择擦除最具辨别力的区域或突出显示特征图中的信息区域。但是随机擦除会以某种方式丢弃重要信息,从而导致分类性能下降。
ACoL 在顶部应用两个并行分类器来训练网络,一个直接从共享骨干网输入未擦除的特征图并生成擦除掩码,而另一个通过此掩码输入擦除的特征图。
SeeNet 针对对象和背景线索引入了两种自擦除策略,可以防止注意力转移到背景区域,从而更准确地挖掘对象。
HaS随机隐藏给定图像的补丁,以迫使网络寻找对象的更多相关部分,这也可以被认为是一种数据增强方式。
DANet 借助对对象类别层次结构的更强监督,利用跨类别语义差异和空间差异来学习互补和有区别的视觉模式。
soft proposal network
SPG
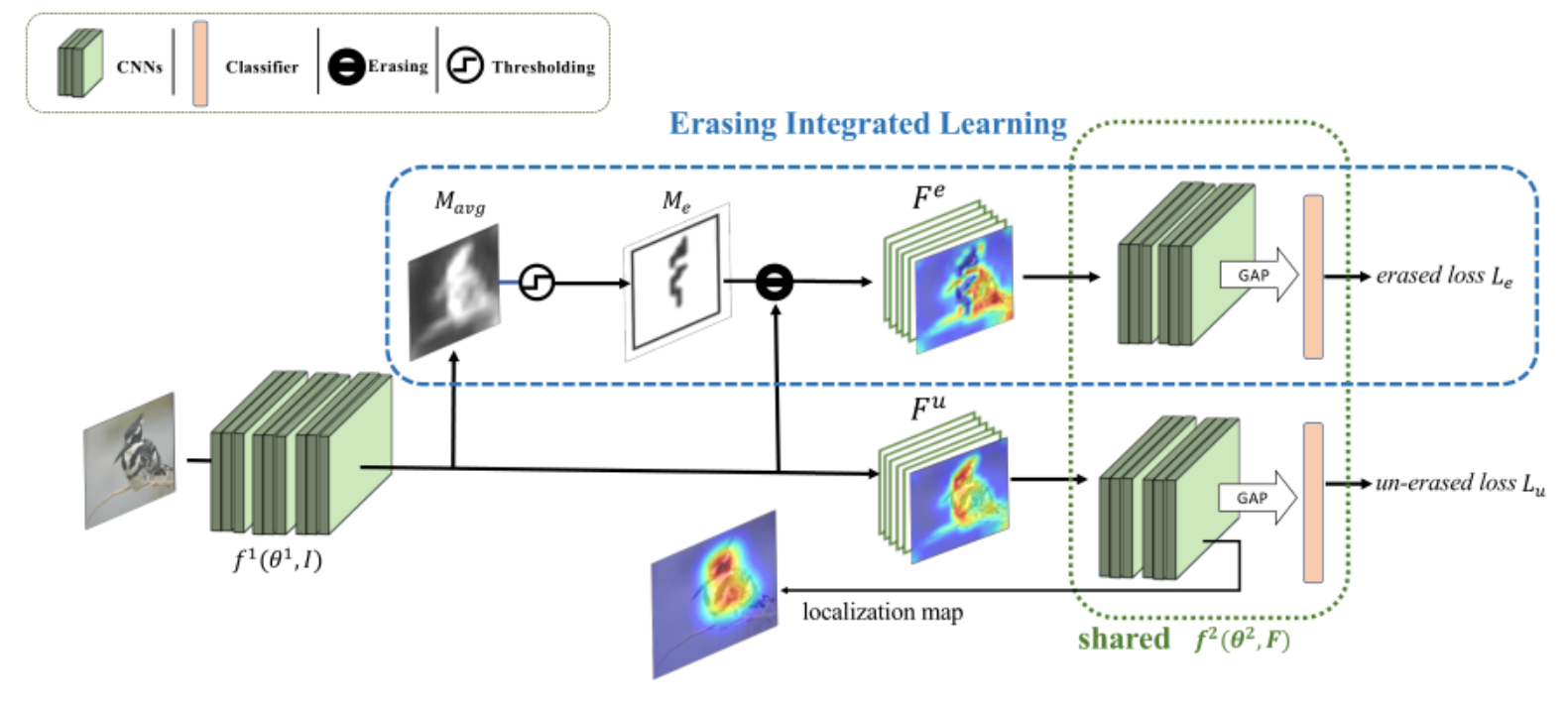
首先按照ADL中的掩码生成方法,利用channel wise avgpooling得到自注意力图,经过阈值筛选后得到Drop mask。然后使用Drop mask对原特征图进行擦除,将擦除后的和未擦除的特征图一起送入下一个卷积块,可以视作创建了擦除和未擦除两个数据流,网络参数权重共享,对擦除数据和未擦除数据分别产生两个分类损失,通过未擦除的损失,网络可以学习通过最具辨别力的类特定区域对对象进行分类。擦除的损失促使网络将注意力集中在判别力较低的部分以探索互补对象区域。在测试阶段EIL模块是不起作用的,直接使用普通模型得到注意力图。
消融实验证明了两个流产生的梯度不会冲突或相互抵消
Top-1 classification accuracy
Top-1 localization accuracy
localization accuracy with known ground-truth class (GT Loc)
Rethinking the Route Towards Weakly Supervised Object Localization
pseudo supervised object localization (PSOL)伪监督对象定位
WSOL has the assumption that there is only one object of
the specific category in the whole image
WSOL假设图像中属于特定类别的物体只存在一个(一类一物one object in one class)
相关文章提到了CAM,Grad-CAM,HaS,ACoL,SPG,ADL
关于WSOD:WSOD 没有one object in one class的限制。然而,WSOD 经常需要诸如selective search和edge boxes 等生成区域建议的方法,这将花费大量的计算资源和时间。此外,当前的 WSOD 检测器使用高分辨率输入来输出边界框,导致计算负担沉重。因此,大多数 WSOD 方法难以应用于大规模数据集。
WSOL的缺点:
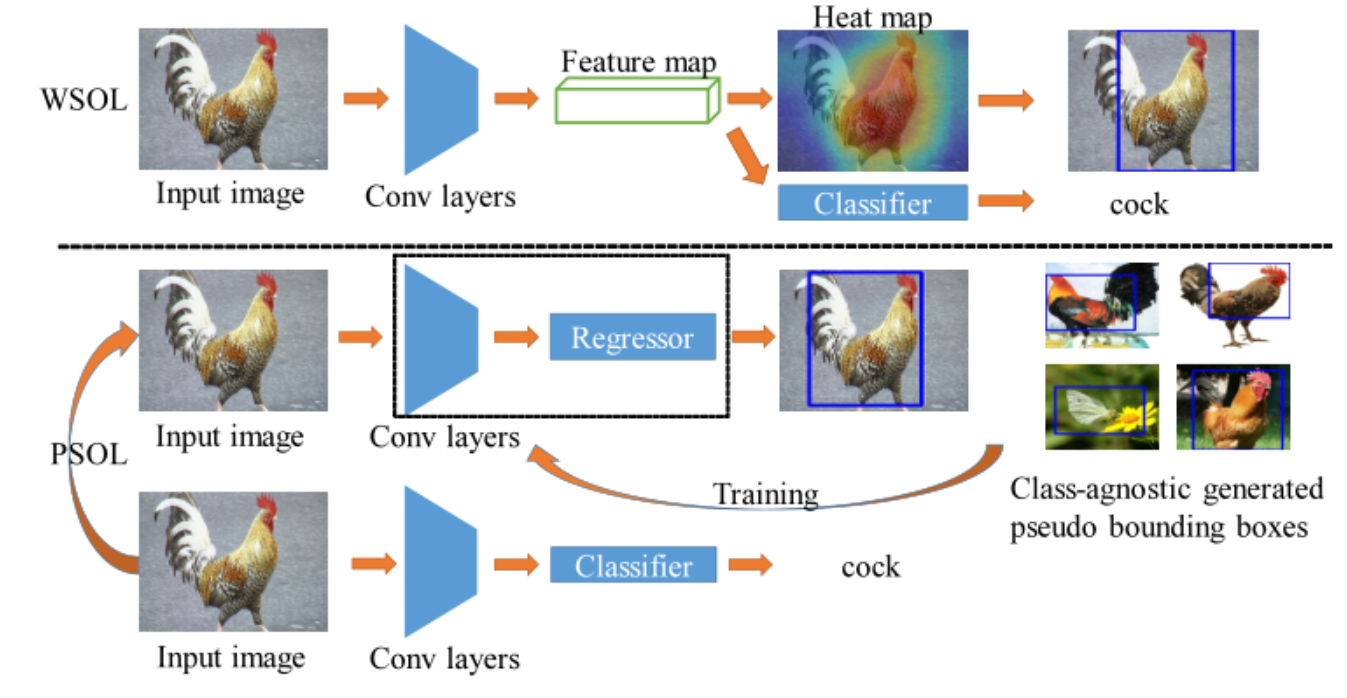
使用DDT-VGG16生成伪标注框(Class-agnostic generated pseudo bounding boxes与类别无关的伪边界框)
使用伪边界框训练localization网络,进行single-class regression (SCR)
另一分支单独训练分类网络
Evaluating Weakly Supervised Object Localization Methods Right
从输入输出看,给定输入图像,SS语义分割模型生成逐像素类预测 ,OD对象检测模型输出一组具有类预测的边界框,实例分割模型预测一组带有类和实例标签的不相交掩码。另一方面,OL对象定位假设图像包含单个类别的对象,并在来自感兴趣类别的对象周围生成二进制掩码或边界框。
自 WSOL 开创性的类激活映射 (CAM) 工作以来,该领域一直专注于如何扩展注意力区域以更广泛地覆盖对象并更好地定位它们。然而,这些策略依赖于完全本地化监督来验证超参数和模型选择,这在 WSOL 设置中原则上是被禁止的。
作者认为CAM后的各种方法对WSOL任务的提升依赖于超参和模型的选择,这样的人工选择其实引入了监督信息
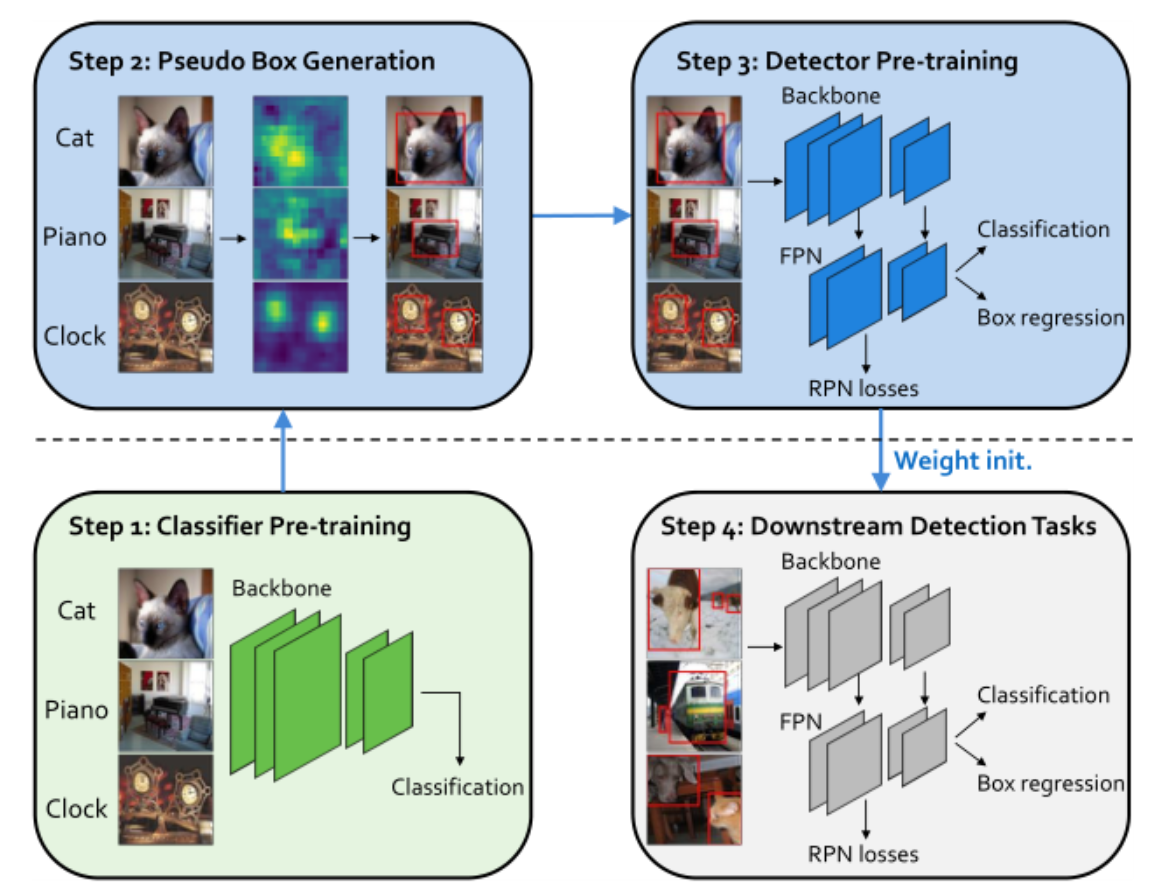
DAP:Detection-Aware Pre-training with Weak Supervision
使用WSOL方法来预训练目标检测网络
传统的分类预训练加微调只包含DAP工作流程中的1和4
分类预训练带来的目标检测经验增益随着预训练数据集的不断增大而递减,且当数据集足够大时,随机初始化也能得到和分类预训练加微调类似的较好结果。
本文认为预训练和微调任务的不匹配造成了分类预训练的增益递减。不匹配体现在:
Strengthen Learning Tolerance for Weakly Supervised Object Localization增强学习容忍度
gt known loc acc 87.6%
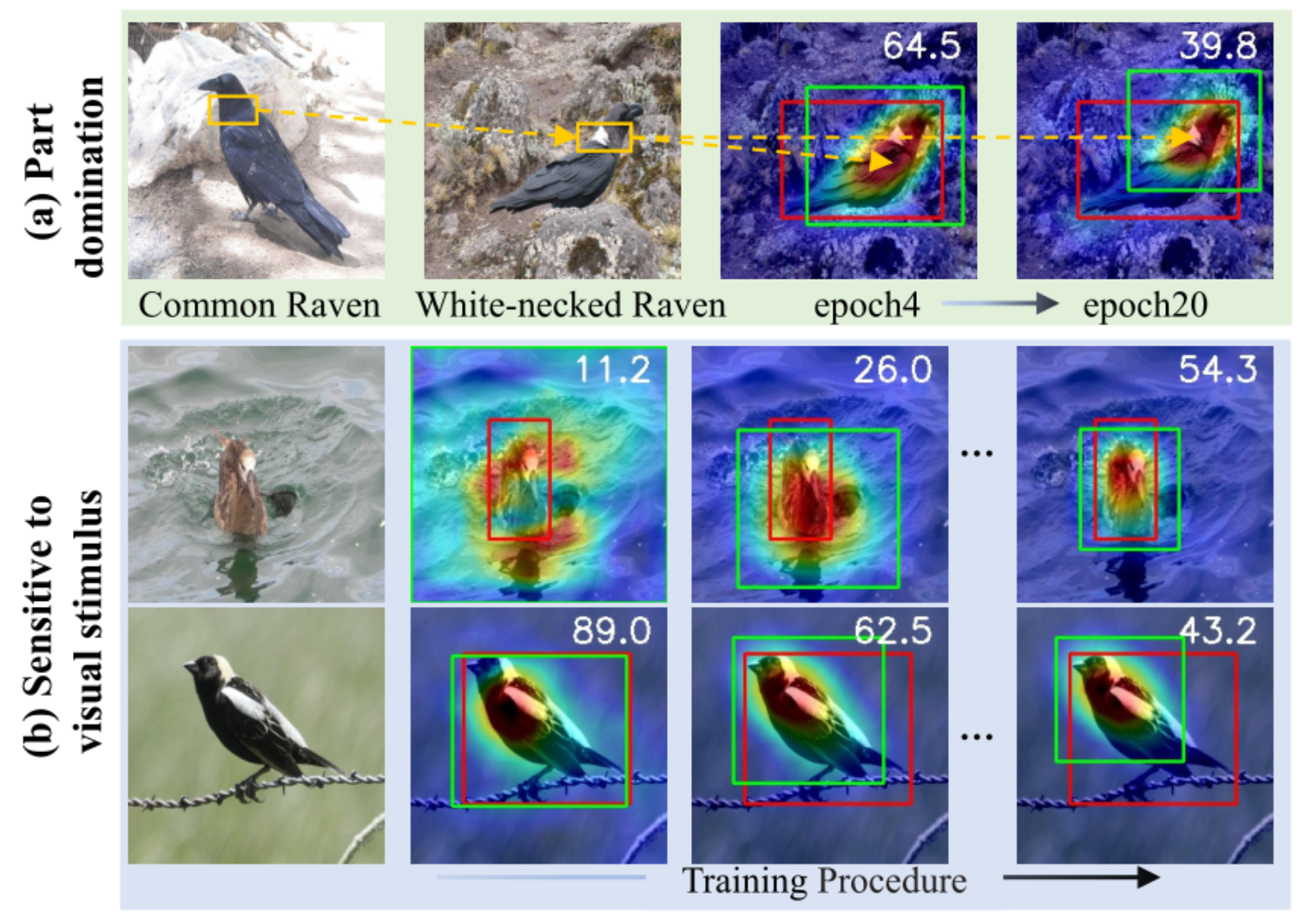
关注最具判别性的区域
由于 Common Raven 类别和 White-necked Raven 类别除了颈部区域的颜色外几乎没有区别,因此从这些图像中提取的类激活图只会关注鸟的颈部,这将导致对物体位置的错误预测。我们认为,造成这种现象的原因是对语义错误缺乏容忍度
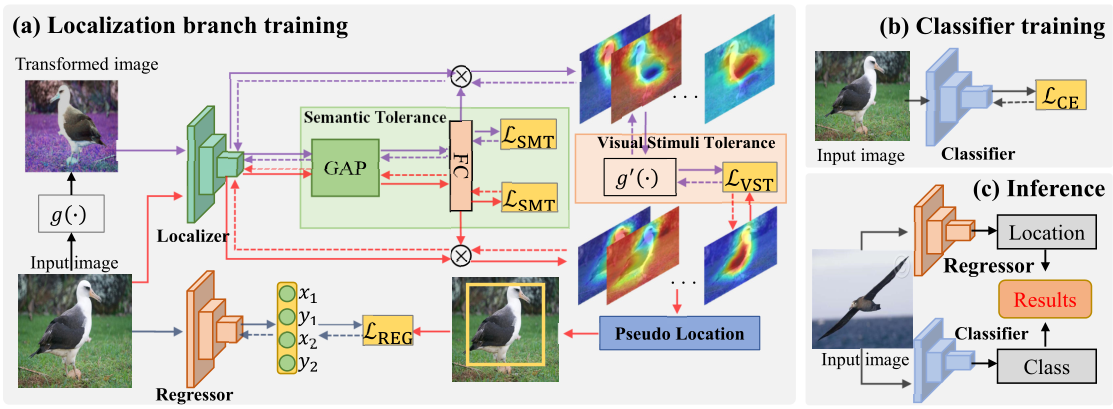
解决方法(Tolerance to Semantic Mistakes)
减少相似类别之间错误分类的惩罚,缓解这一问题
视觉敏感性:不同实例的定位精度表现出不同的收敛趋势。(可以理解为鲁棒性不强)
虽然只有图像级监督可用,但该模型在学习过程中几乎无法提取等变模式。这使得模型对输入视觉刺激的变化敏感,例如不同的色调、对比度、纹理、空间位置等。因此,不同实例的定位精度的收敛趋势变得非常不同。这种现象使得很难获得可以对任意输入图像实现准确性能的 WSOL 模型。
解决方法(Tolerance to Visual Stimulus)
变换图像的视觉响应图与原始图像的视觉响应图相匹配来增强对图像多样性的容忍度。
定位、分类统一框架:
Grad-cam, HaS, ACoL, SPG, ADL, Danet, EIL, CutMix
定位、分类分离框架:
PSOL, GC-net以及本文提出的SLT-Net
Self-produced Guidance for Weakly-supervised Object Localization 自生成导向的弱监督对象定位
Acol、object mining等方法忽视了像素之间的相关性。
注意力图可以有效地提供每个像素成为前景或背景的概率。虽然高前景/背景概率的像素可能不能覆盖整个目标物体/背景,但它们仍然为获取目标物体的一些共同模式提供了重要线索。
在此基础上,我们可以简单地利用这些可靠的前景/背景种子作为监督,鼓励网络感知前景物体和背景区域的分布。由于具有相关性的像素(例如在相同的对象或背景中)通常具有相似的外观,更可靠的前景/背景像素可以很容易地通过学习发现的种子。利用更可靠的引导像素进行监控,可以逐步将整个前景对象从背景中区分出来,最终有利于弱目标的定位
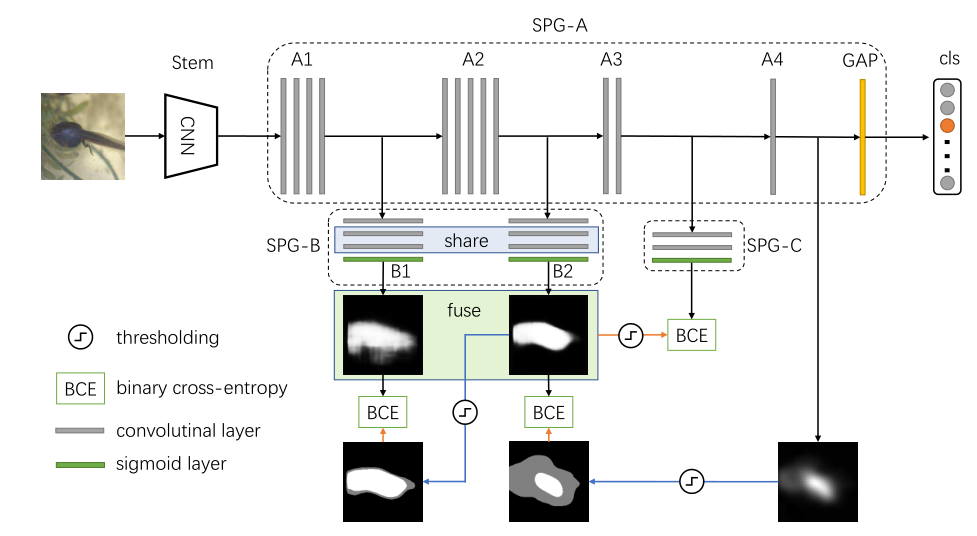
利用分类网络生成注意力图,按照置信度高低分为三个区域,高置信度区域为目标,低置信度区域为背景,中等置信度区域为未确定。
将深层特征图的注意力利用阈值得到前景和背景、位置区域的掩码,作为浅层网络产生的特征图的监督信息。
将前景(即感兴趣的对象)与背景分开,为分类网络提供像素的空间相关信息。然后将生成的 SPG 掩码用作辅助监督,以鼓励网络学习像素之间的相关性。因此,同一对象内的像素在特征图中将具有相同的响应。由于详细信息(即对象边缘和边界)在顶级特征图中通常非常抽象,因此我们使用中间特征来生成精确的 SPG 掩码。
Geometry Constrained Weakly Supervised Object Localization
几何约束弱监督对象定位
使用有时不明确的激活区域可能无法反映感兴趣对象的确切位置。因此,这些方法产生的监督信号不足以训练深度网络进行精确的对象定位。
需要手动仔细调整阈值,以便从相应的激活图中提取好的 bbox。
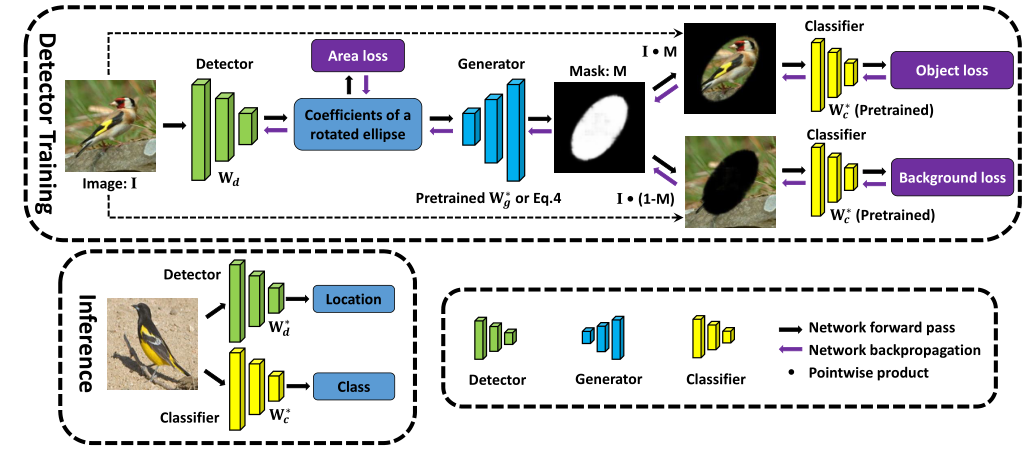
GC-Net 由三个模块组成:检测器、生成器和分类器。检测器预测一组系数,这些系数表示包围对象的一些几何形状。生成器将系数转换为二进制掩码。然后分类器对生成的蒙版图像进行分类。在训练过程中,只需要分类标签,在推理过程中,检测器用于预测几何系数,从中可以计算出物体的位置。
Superpixel Segmentation with Fully Convolutional Networks
超像素通过将感知上相似的像素组合在一起来提供图像数据的紧凑表示。作为一种有效减少后续处理图像基元数量的方法,超像素已被广泛应用于视觉问题。但是只有少数尝试将它们整合到深度神经网络中。一个主要原因是标准卷积操作是在规则网格上定义的,并且在应用于超像素时变得低效。
修改深度架构以合并超像素的相关文章:
Superpixel convolutional networks using bilateral inceptions. ECCV 2016
Supercnn: A superpixelwise convolutional neural network for salient object detection. IJCV 2015.
本文提到的关键思想:将每个超像素和常规图像的网格单元相关联,这是传统超像素算法初始化的常用策略,将超像素分割任务看作找到图像像素和常规网格单元之间的关联分数,并使用全卷积网络直接预测分数。
本文主要贡献:
提出了一个简单的全卷积网络用于超像素分割
提出了一个通用的基于超像素的下采样/上采样框架
与下游任务一起训练超像素