TPAMI2021 Affinity Attention Graph Neural Network
Affinity Attention Graph Neural Network for Weakly Supervised Semantic Segmentation 亲和力与图卷积神经网络的结合
将弱监督转换为semi-supervised(部分点是有标注的)
Introduction
图神经网络GNN可以可以直接在不同节点之间建立长距离关系(边),聚合多个连接节点的信息,从而抑制标签噪声的负面影响,在标签有限的半监督任务中GNN也表现良好。
GraphNet的缺点:
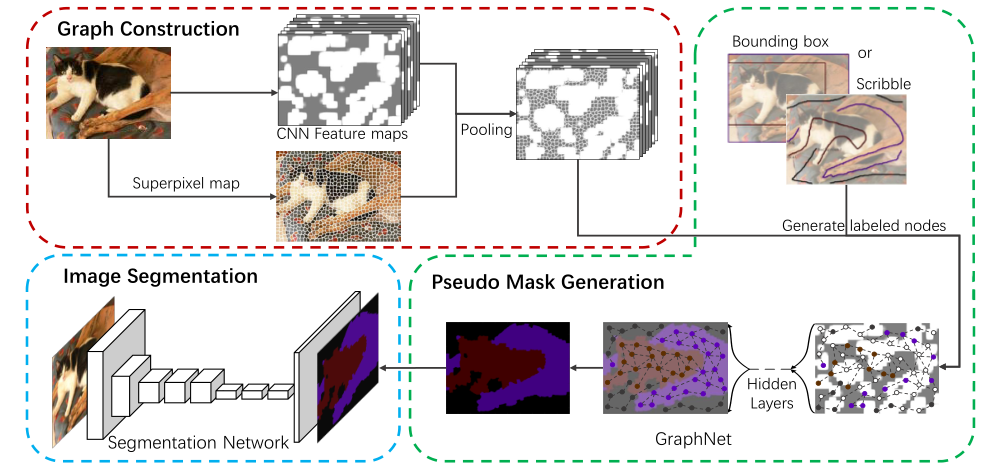
- GraphNet通过阈值构建了一个未加权的邻接图(邻接矩阵A)作为输入,会丢失一些信息,这样的图不能准确地提供足够的信息,因为它平等地对待所有边,边权重为 0 或 1,尽管实际上并非所有连接的节点都期望相同的亲和力。(邻接图中所有的边都是0或1,并不能很好的体现亲和力)
- GraphNet仅使用初始的标签节点进行训练,这使得当输入的初始节点特征不准确时,会导致不正确的特征聚合,只使用交叉熵损失,不能减轻不正确的节点、边和标签的影响。
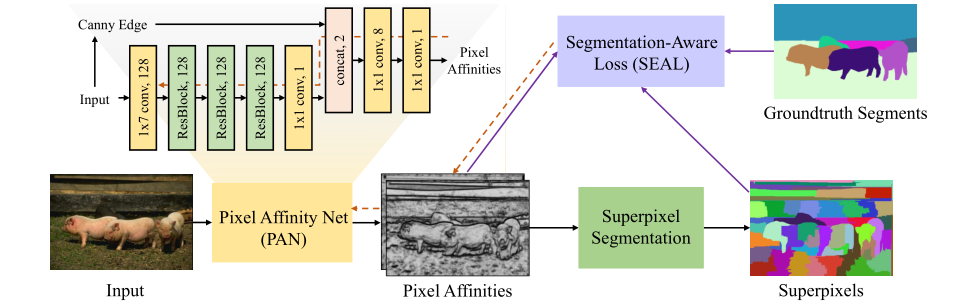
作者设计了一个 Affinity Attention Graph Neural Network (A2GNN) 来解决上述问题。具体来说,作者提出了一种新的亲和力CNN来将图像转换为加权图,而不是使用传统方法来构建未加权图。加权图比未加权图更合适,因为它可以为不同的节点对提供不同的亲和力。之前的方法如GraphNet只考虑局部连接的节点,构建了一个基于超像素的未加权图,而本文同时考虑了局部和长距离边,构建的加权图将一个像素视为一个节点。
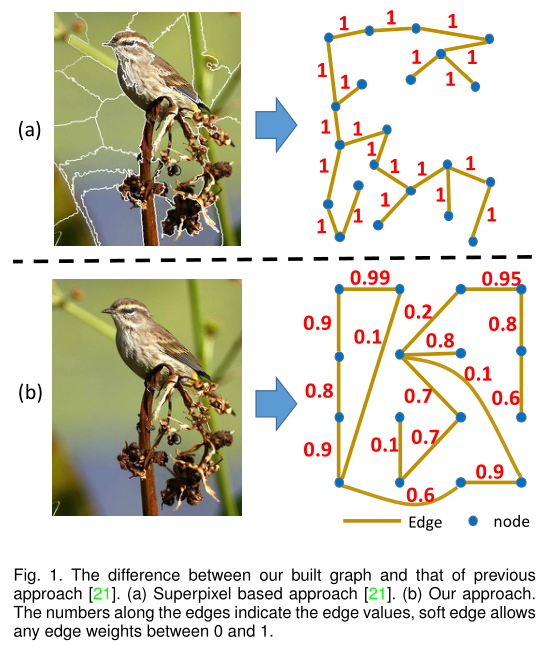
特点:
- soft edge
- pixel as node
- local and long distance
为了产生准确的伪标签,作者设计了一个新的 GNN 层,其中应用了注意力机制和边缘权重,以确保准确的传播。因此,具有弱/无边缘连接或低注意力的成对节点之间的特征聚合可以显着下降,从而相应地消除不正确的传播。随着训练的进行,节点注意力会动态变化。