CaFo
Prompt, Generate, then Cache: Cascade of Foundation Models makes Strong Few-shot Learners
- 利用GPT-3基于人工设计的模板产生文本输入,用于提示CLIP
- 通过DALL-E生成合成图像,据特定领域的文本为不同类别生成额外的训练图像,以扩展少量训练数据
- 引入可学习的缓存模型,自适应地混合来自CLIP和DINO的预测

Methodology
Prompt
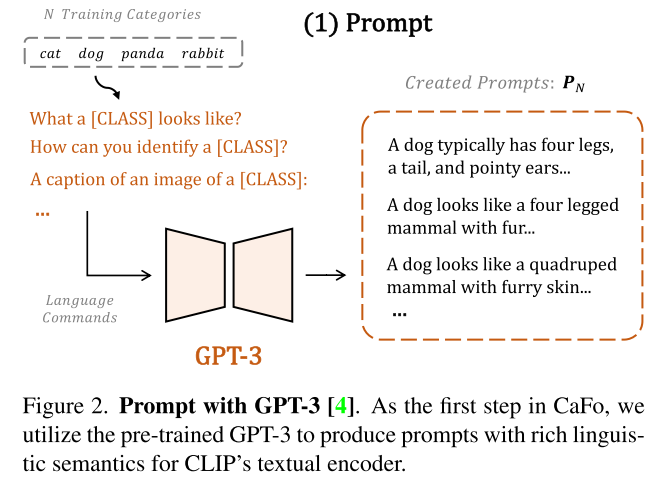
使用手工设计的模板来作为提示输入GPT3
将GPT3输出的文本描述送入CLIP text encoder提取文本描述特征
Further, for some downstream data with specialized categories, we can customize the language commands for producing prompts with more domain-specific semantics.
For example, in OxfordPets [53] dataset of pet images, we adopt the input ofGPT-3 as “This is a pet bulldog, it has thin neck, short face, floppy ears. It’s coat is short, straight, and in brindle color. This is a pet [CLASS],”. Based on that, GPT-3 continues to describe more details of the [CLASS] pet.
Generate
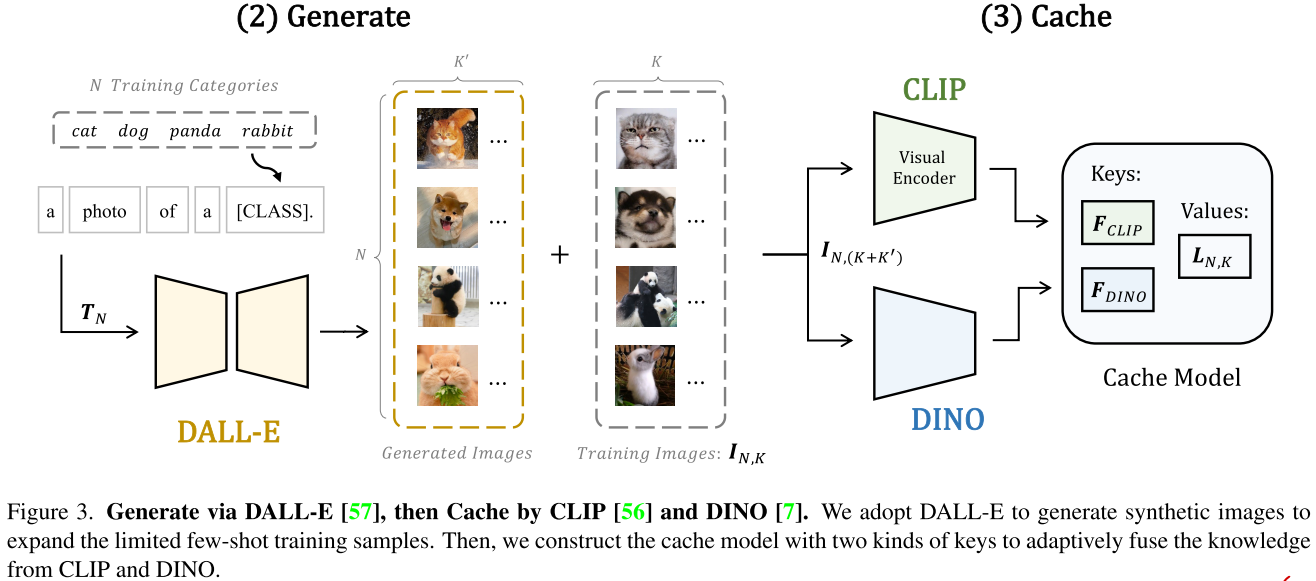
- 基于类别名使用DALL-E生成图像
- 使用CLIP来筛选生成的图像,选取top $K’$个作为扩充类别样本的数据
- We keep $K’$ comparable with $K$ to ensure the synthesis quality and also preserve the low-data regimes
Cache
caching two kinds of keys: 使用CLIP和DINO提取所有$N\times (K+K’)$张训练图像的特征,存为keys
$\begin{aligned}
& F_{\mathrm{CLIP}}=\operatorname{CLIP}_{v i s}\left(I_{N,\left(K+K^{\prime}\right)}\right) ; \\
& F_{\mathrm{DINO}} =\operatorname{DINO}\left(I_{N,\left(K+K^{\prime}\right)}\right)\\& F_{CLIP,DINO} \in \mathbb{R}^{N(K+K’)\times C}
\end{aligned}$为每个样本都生成对应的one-hot label作为两种keys对应的value
$L_{onehot} \in \mathbb{R}^{N(K+K’)\times N}$
During training, we follow Tip-Adapter that only enables the cached keys in the adapter to be learnable and keeps the pre-trained models frozen
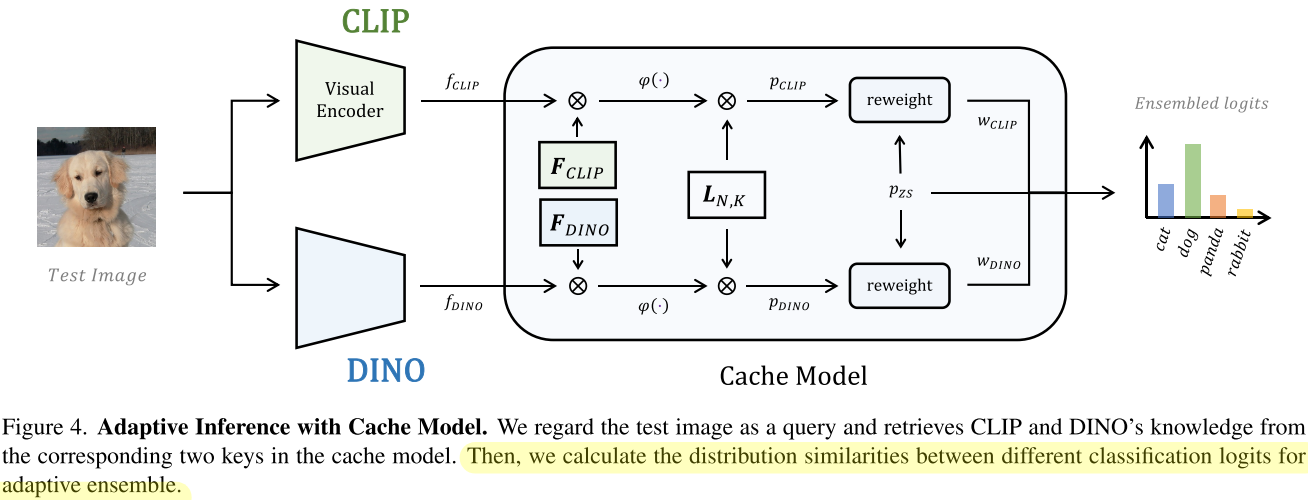
融合推理过程
首先通过CLIP和DINO提取query图像的特征$f_{CLIP},f_{DINO}\in \mathbb{R}^{1\times C}$
分别从CLIP’s zero-shot alignment和两个keys中获取3个predicted classification logits $p_{ZS},p_{CLIP},p_{DINO}\in \mathbb{R}^{1\times N}$
$\begin{aligned}
p_{\mathrm{ZS}} & =f_{\mathrm{CLIP}} \operatorname{CLIP}_{\text {tex }}\left(P_{N}\right)^{T} ; \\
p_{\mathrm{CLIP}} & =\varphi\left(f_{\mathrm{CLIP}} F_{\mathrm{CLIP}}^{T}\right) L_{\text {onehot }} ; \\
p_{\text {DINO }} & =\varphi\left(f_{\mathrm{DINO}} F_{\text {DINO }}^{T}\right) L_{\text {onehot }},
\end{aligned}$$P_N$代表GPT-3生成的prompts(对类别的文本描述),$\varphi(x)=exp(-\beta\cdot(1-x))$ serves as a non-linear
modulator to control the sharpness of affinity matrix作者将CLIP文本编码器提取的GPT-3生成的类别特征计算得到的predicted classification logit $p_{ZS}$作为prediction baseline,并respectively normalize the scales of three classification logits into -1 to 1 by their each mean and standard
deviation, 并计算其分别与$p_{CLIP}$和$p_{DINO}$的相似度来获得融合时的权重$\begin{array}{l}
w_{\mathrm{CLIP}}=p_{\mathrm{CLIP}} p_{\mathrm{ZS}}^{T} ; w_{\mathrm{DINO}}=p_{\text {DINO }} p_{\mathrm{ZS}}^{T} . \\
p_{e n}=p_{\mathrm{ZS}}+\sum_{i} p_{i} \cdot \operatorname{softmax}\left(w_{i}\right), \text { where } i \in\{\mathrm{CLIP}, \mathrm{DINO}\}
\end{array}$