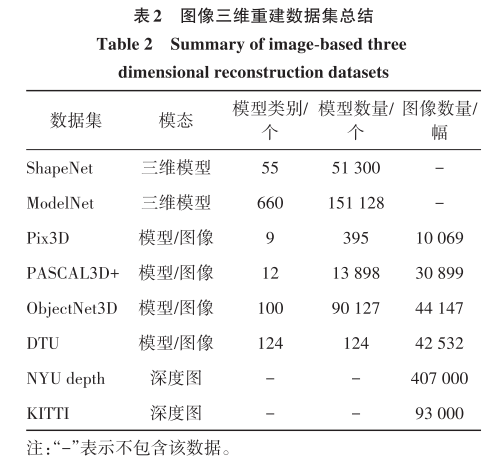
三维模型的表示形式有3种:体素模型、网格模型和点云模型。体素是三维空间中的正方体,相当于三维空间中的像素;网格是由多个三角形组成的多面体结构,可以表示复杂物体的表面形状;点云是坐标系中的点的集合,包含了三维坐标、颜色和分类值等信息
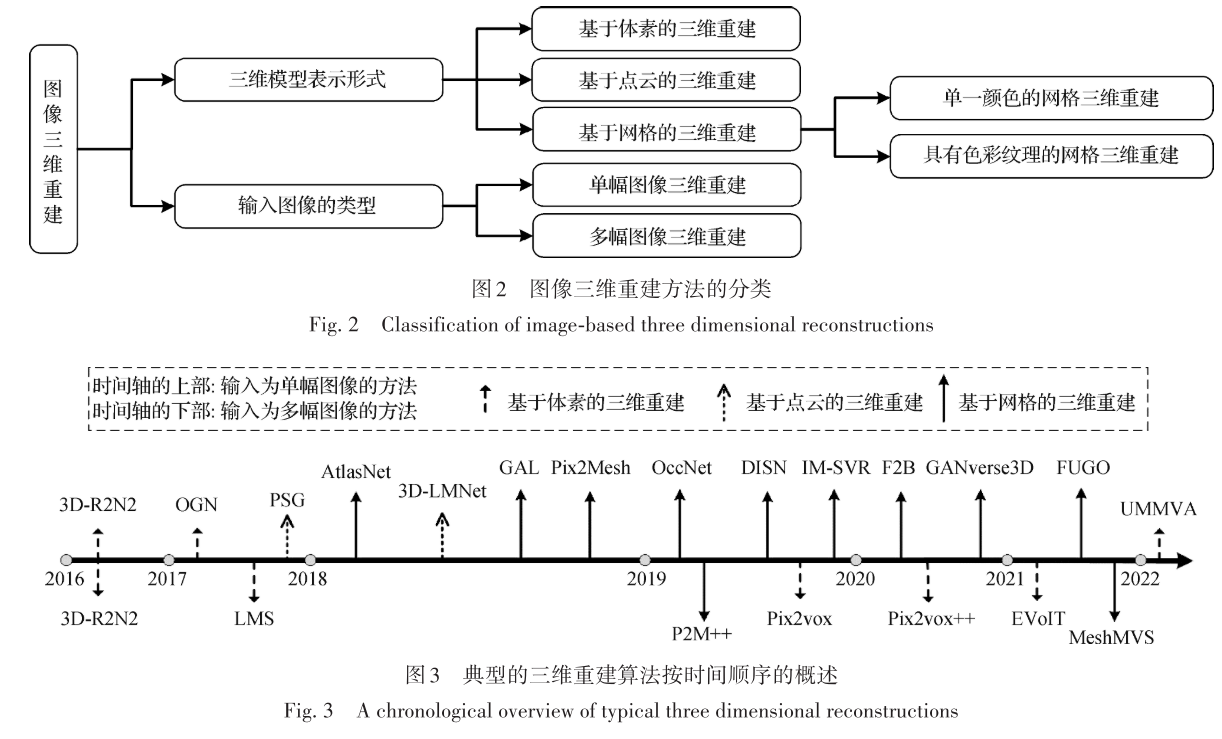
单幅图像三维重建
基于体素的单幅图像三维重建
- 在基于体素的三维重建网络中,处理体素的方式与处理图像中的像素的方式类似,二维卷积能够较简单地转变为三维卷积。基于体素模型的三维重建网络的解码器通常由三维卷积构成,利用三维体素模型进行训练,但重建体素模型通常需要较大的内存,所需内存和计算要求与体素模型的分辨率大小成立方比例,因此重建的体素模型分辨率较低,基于体素模型的方法无法重建物体的细节部位
基于点云的单幅图像三维重建
- 点云是利用三维坐标、颜色等信息表示物体表面的点的集合,为三维重建网络提供了更好的表示形式
- 基于点云的方法重建的形状更加平滑,相较于体素模型运算所占用的内存更少
- 由于点云的无序性,二维卷积无法直接应用在基于点云的三维重建方法的解码器中,基于点云的三维重建方法通常使用全连接层组成MLP解码点云信息,计算量随点云增多而增大,为减少计算量,通常侧重于重建表面的点,由于点云的离散性,重建的点云模型表面不完整,分辨率较低
基于网格的单幅图像三维重建
基于多阶段网络的单幅图像三维重建
相比于体素模型和点云模型,网格模型能够更加完整地表示物体表面形状,一些方法利用深度估
计、点云重建等多个阶段构建深度学习网络重建网格形式的三维模型深度图和表面法向表示物体部分视角的立体结构,深度估计和表面法向估计可作为网格重建的中间步骤。深度图的像素表示物体到相机所在平面的距离,表面法向表示物体表面的点的切线方向
基于深度和表面法向的网格模型重建对不可见部位的重建效果较差
基于模板的单幅图像三维重建
- 由于网格模型的顶点相互连接,将网格的顶点作为图结构进行处理,使用图卷积神经网络处理网格模型的顶点,从而对初始的网格模型进行变形优化,重建更加精细的网格形式的三维模型,如Pixel2Mesh
- 基于模板的单幅图像三维重建通过变形初始网格模型或回归参数化模型的方式对三维模型进行重建,通常只能重建特定顶点数量的网格模型,对三维模型细节部位的重建效果较差
基于隐式函数的单幅图像三维重建
- 为减少训练期间的内存并进一步提高重建效果,一些研究者提出可表示三维形状的隐式函数,通过学习重建目标的隐式函数来重建网格形式的三维模型。常用的隐式函数有符号距离函数、空间占有率和点标签。
- 基于隐式函数的三维重建方法使用隐式函数表示物体形状,可重建具有完整表面和细节信息的三维模型。
基于可微渲染的单幅图像三维重建
- 大多数单幅图像三维重建的方法重建单一颜色的网格,一些方法通过可微渲染估计对三维模型进行纹理映射,重建具有颜色纹理的网格模型
- 通过可微渲染将初步重建的三维模型渲染为二维图像并与输入图像构建二维图像损失,通过估计形状、照明和纹理来重建具有颜色纹理的网格模型
- 基于可微渲染的单幅图像三维重建使用仅包含图像的数据集进行训练,降低了数据集的获取难度,可重建三维模型的颜色纹理
多幅图像三维重建
- 基于体素的多幅图像三维重建
- 基于体素的多幅图像三维重建网络结构与单幅图像三维重建网络类似,也是编码器—解码器结构,将编码器输出的多幅图像特征进行融合,并根据图像特征对体素模型进行细化调整,实现多幅图像三维重建
- 基于网格的多幅图像三维重建
- 基于网格的多幅图像三维重建的输入通常为已知相机参数的多幅图像,通过结合多视图中每幅图像对应的相机参数,能够获取图像之间的对应关系,从而提高重建三维模型的效果,如Pixel2Mesh++
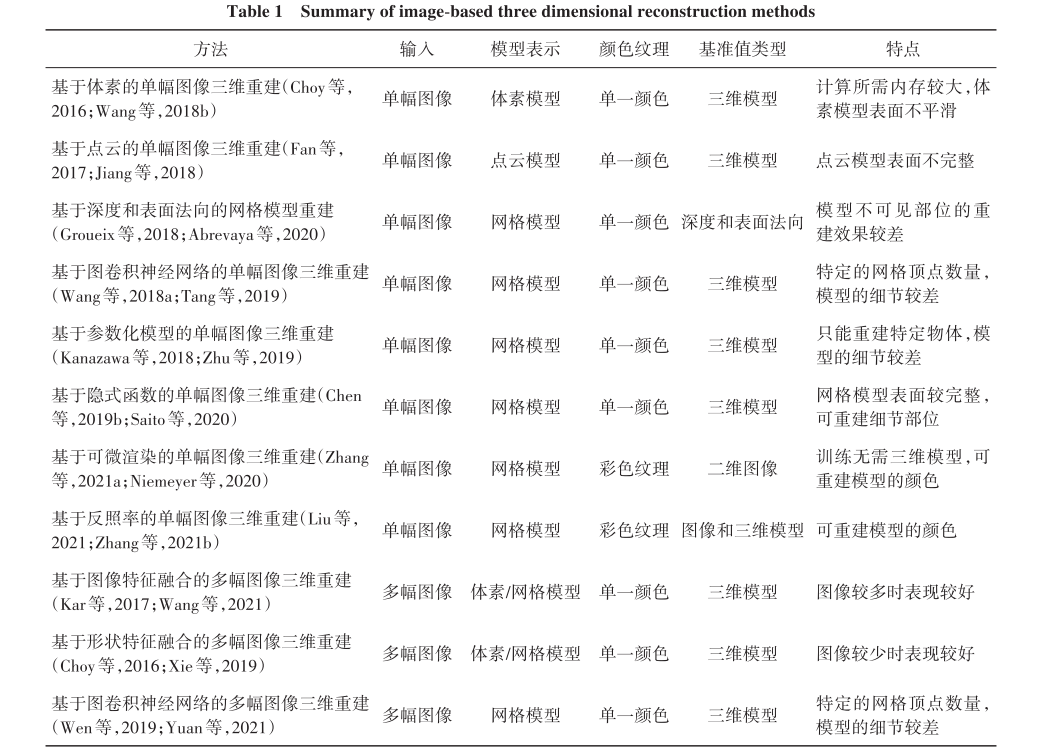
数据集
Shapenet数据集和ModelNet数据集中的图像为三维模型渲染合成,不同视角渲染的多视角图像可用于多幅图像三维重建
- Shapenet收集了大量三维模型并对三维模型添加相应的对齐、部位分割和尺寸等注释。ShapeNet 数据集包含55个类别的51 300个三维模型。大多数三维重建方法使用由13个类别的44 000个模型组成的ShapeNet数据集的子集,数据集中的二维图像由三维模型渲染合成。