LERF
LERF: Language Embedded Radiance Fields. ICCV2023 Oral

Motivation
人类使用自然语言描述一个特定的3D位置通常会从以下角度出发:
- visual appearance
- semantics
- abstract associations
- actionable affordances
NeRF是一个colorful desity field,但是没有语义信息,基于NeRF建立3D场景交互界面受到限制
LERF在NeRF基础上加了一个language field,输入位置和尺寸,输出CLIP特征。在训练时,使用从training views的image crops中获得的多尺度CLIP特征来训练language field。
这使得CLIP编码器捕获不同尺度的图像上下文,从而将相同的3D位置与不同尺度的不同language embeddings(例如,不同的语言嵌入)相关联。如“器皿”与“木勺”)
LERF构建的3D表示language field是视角无关的,可以用不同的文本提示查询,而无需每次重建底层表示,将多个视点融合到单个共享场景表示中,而不是按图像操作。
Related Work
Distilling 2D Features into NeRF
- Semantic NeRF [39]
- Panoptic Lifting [33]
- Distilled Feature Fields[20]
- Neural Feature Fusion Fields [37]
3D Language Grounding
- 3D vqa [15,2,6]
- incorporating language with shape information can improve object recognition via text [11, 36]
- VL-Maps,OpenScene采用了微调的OV dense feature
- CLIP-Fields,NLMaps-SayCan特征更稀疏,因为是基于检测到的物体
- ConceptFusion 使用了Mask2Former
LERF没有使用任何region或者mask proposals
Methodology
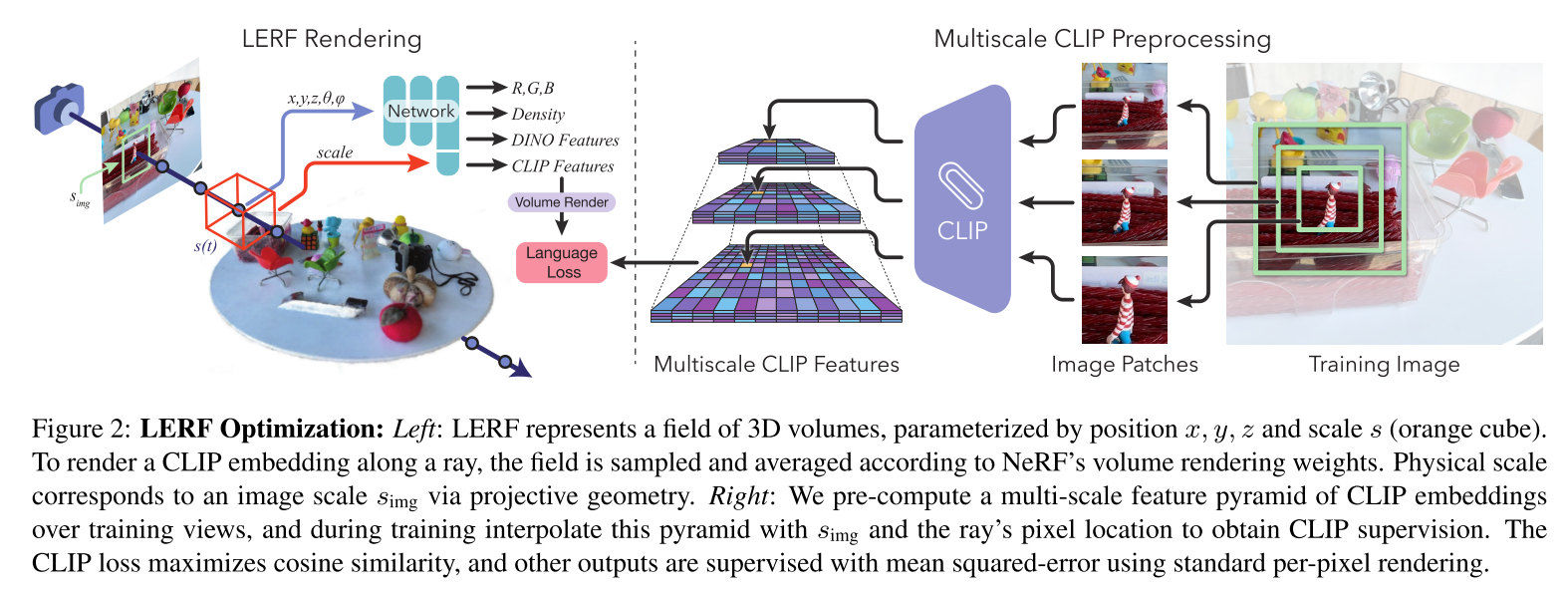
LERF Volumetric Rendering
NeRF:输入位置$\vec{x}$和视角方向$\vec{d}$,输出颜色$\vec{c}$和密度$\sigma$
在NeRF基础上,添加图2中的红色箭头分支,获得language embedding $F_{lang}(\vec{x},s) \in \mathbb{R}^d$,这一分支的输入是位置$\vec{x}$和尺度$s$,输出是一个$d$维的language embedding
- 这个输出是视角无关的(也就是输入没有视角方向$\vec{d}$),因为同一位置的语义应该是视角不变的。这使得多个视图可以对同一个field做出贡献,将多视图的embeddings平均。
尺度$s$表示以$\vec{x}$为中心的立方体的世界坐标中的边长,并且类似于Mip-NeRF通过集成位置编码合并不同尺度。
color和density的渲染和NeRF一致
To render language embeddings into an image, we adopt a similar technique as prior work[20, 39] to render language embeddings along a ray $\vec{r}(t)=\vec{o_t}+t\vec{d}$.
LERF是基于volumes而不是基于points的,需要为ray上每个位置都设置一个尺度参数:
$s(t)=s_{img}*f_{xy}/t$,其中$s_{img}$是一个固定的像平面初始化尺度,$f_{xy}$代表焦距, $t$代表采样点到ray origin的距离,几何上看,这表示了沿射线方向的一个视锥
原文是We achieve this by fixing an initial scale in the image plane simg and define s(t) to increase proportionally with focal length and sample distance from the ray origin
但分析公式应该是距离射线原点越远,尺度越小?
Rendering weights计算
Multi-Scale Supervision
在训练阶段重复计算CLIP特征是昂贵的,因此作者的做法是:
we pre-compute an image pyramid over multiple image crop scales and store the CLIP embeddings of each crop (Fig 2, right). This pyramid has n layerssampled between smin and smax, with each crop arranged in a grid with 50% overlap between crops
在训练时, randomly sample ray origins uniformly throughout input views, and uniformly randomly select $s_{img} \in (s_{min}, s_{max})$ for each.(在输入视图中均匀地随机采样光线原点,并为每个视图均匀随机地选择尺寸)
Since these samples don’t necessarily fall in the center of a crop in this image pyramid, we perform trilinear interpolation between the embeddings from the 4 nearest crops for the scale above and below to produce the final ground truth embedding$\phi^{gt}_{lang}$
然后最大化rendered embedding和gt embedding的余弦相似度
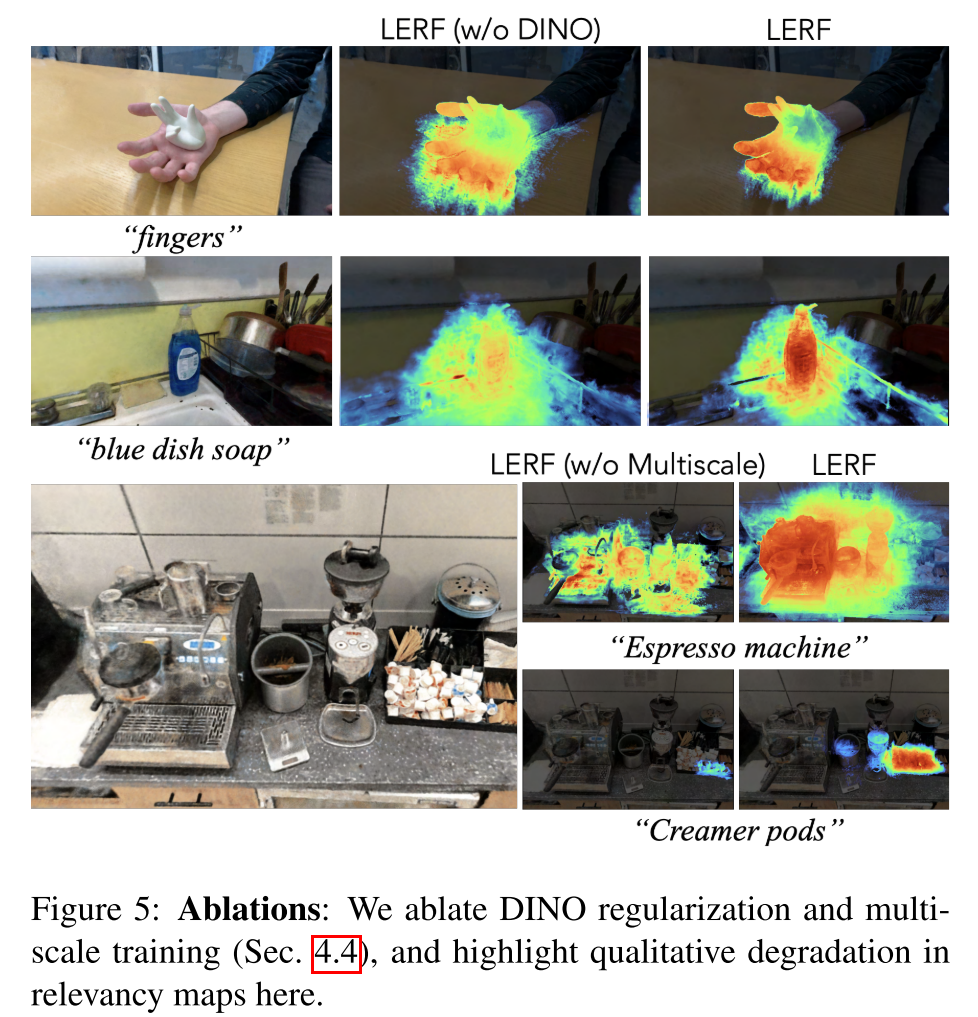
DINO Regularization
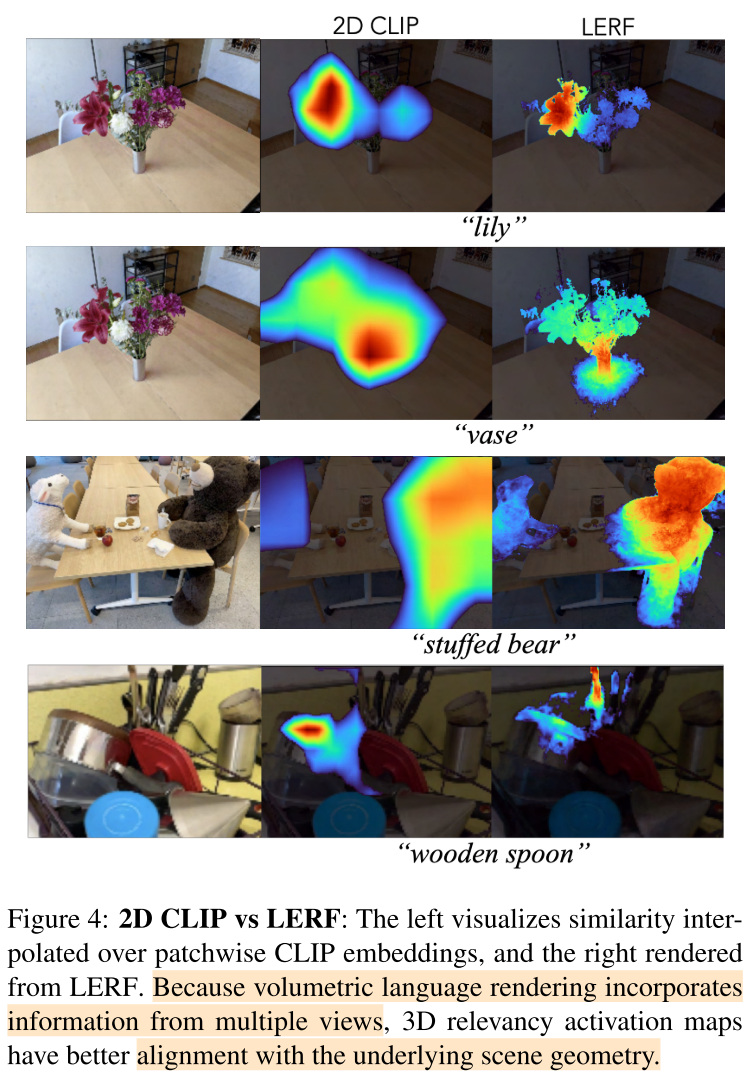
问题:relevancy maps can sometimes be patchy and contain outliers in regions with few views or little foreground-background separation
为了缓解这一问题,作者额外训练了一个field $F_{dino}(\vec{x})$, 输出每个位置对应的DINO feature,使用MSE loss
DINO在推理期间显式使用,并且仅在训练期间充当额外的正则化器,因为CLIP和DINO输出头共享架构骨干。
Field Architecture
- NeRF和language field的部分是分开的,反向传播不会互相影响
- multi-resolution hashgrid
- Nerfacto from Nerfstudio as backbone
Querying LERF
- obtaining a relevancy score for a rendered embedding
- automatically selecting a scale s given the prompt
Relevancy Score
- rendered language embedding $\phi_{lang}$,text query $\phi_{quer}$,canonical phrases $\phi^i_{canon}$
- All renderings use the same canonical phrases: “object”, “things”, “stuff”, and “texture”
$\min _{i} \frac{\exp \left(\phi_{\text {lang }} \cdot \phi_{\text {quer }}\right)}{\left.\exp \left(\phi_{\text {lang }} \cdot \phi_{\text {canon }}\right)+\exp \left(\phi_{\text {lang }} \cdot \phi_{\text {quer }}\right)\right)}$
Intuitively, this score represents how much closer the rendered embedding is towards the query embedding compared to the canonical embeddings
Scale Selection
- generate relevancy maps across a range of scales 0 to 2 meters with 30 increments, and select the scale that yields the highest relevancy score
- Visibility Filtering
- 部分区域并没有足够多的视图进行观察,因此可能会产生noisy embeddings,因此:during querying we discard samples that were observed by fewer than five training views (approximately 5% of the views in our datasets).