3D-OVS
3D Open-vocabulary Segmentation with Foundation Models
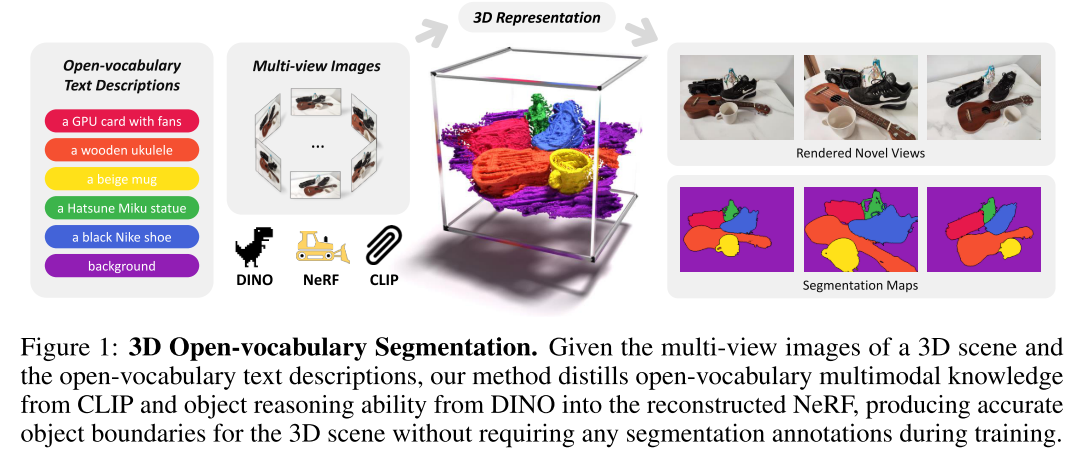
Motivation
- ScanNet的场景和物体类别都非常有限,因此不适合直接用于训练一个open vocabulary model
- OpenScene避免了对3D数据集的需要,但是它继承了2D模型的局限性,这些2D模型(如LSeg,RegionCLIP)通常使用有限文本标签的封闭词汇数据集进行微调,从而显著地损害开放词汇表属性,特别是对于具有长尾分布的文本标签
Achieve precise and annotation-free 3D open-vocabulary segmentation by distilling knowledge from two pre-trained foundation models (CLIP&DINO) into NeRF without finetuning on any close-vocabulary dataset.
CLIP产生的image-level features不适合pixel-level的分割任务,以往在封闭词汇数据上对CLIP进行微调以获得像素级特征的方法破坏了CLIP本身的开放词汇特性
CLIP图像特征通常与文本描述[2]具有模糊的相似性,需要对其进行正则化以实现准确的开放词汇分割
[2] LERF: Language Embedded Radiance Fields
DINO生成特征图,而不是explicit segmentation maps,需要从DINO features中提取出有利于精确分割的必要信息