Introduction
NeRF
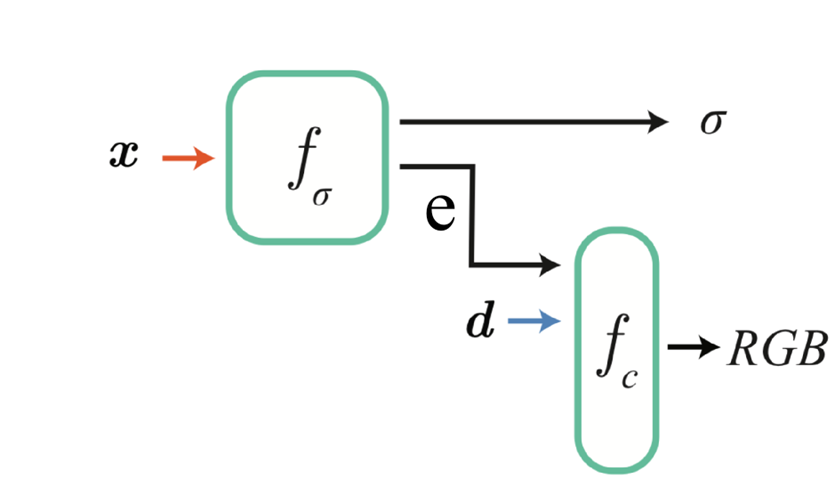
- NeRF (Neural Radiance Fields: Representing Secenes as Neural Radiance Fields for View Synthesis),把场景表达为神经辐射场的形式,来做新视角合成。它本质上是两个简单的全连接的MLP,用来拟合空间位置和视角方向,到该点体密度和RGB值的映射。具体过程如图所示。第一个网络$f_\sigma$输入空间位置$x$,输出这一空间位置的体密度$\sigma$,同时还输出一个特征向量$e$。用第二个网络$f_c$估计RGB值,这个RGB值是和视角相关的,因为材质、光照、反射等等条件的影响,同一个位置的颜色会根据观察角度的不同而变化。把视角$d$和体密度网络$f_\sigma$输出的特征向量$e$一起输入网络$f_c$,得到RGB。
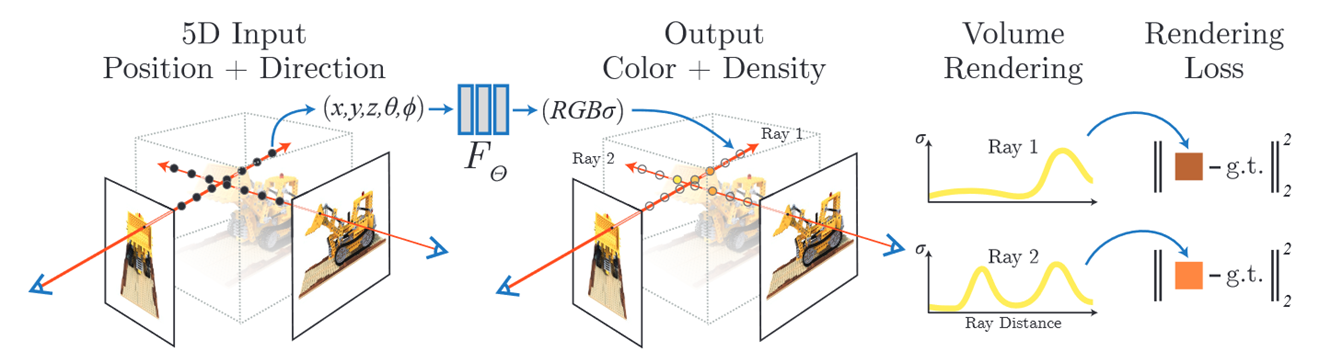
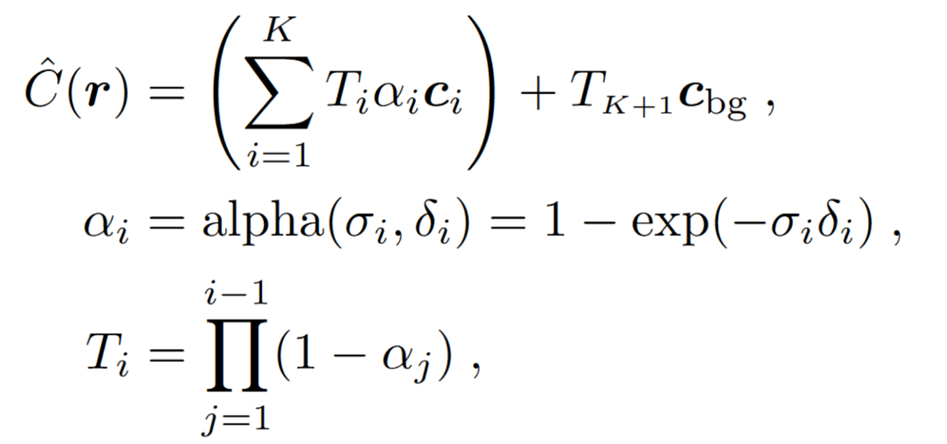
体渲染(volume rendering): 在渲染一张图像的时候,从相机光心生成采样射线,射线上取采样点,使用MLP计算体密度σ和RGB,用一个可微的渲染公式把所有采样值求和获得一个像素值。像素值和ground truth求loss,优化MLP的参数。
体渲染公式:模拟光线在真实世界中的传播。体密度类似于不透明度,实际上不透明度是公式第二行的alpha。对于传统的点云或者TSDF类似的表达是存在遮挡现象的,也就是我们知道一个像素或者一个空间点的RGB值,但不知道沿着视线方向这个点背后的情况,所以模型或者地图往往会有空洞,没法做新视角合成。而NeRF能够通过预测不透明度或者说体密度获得整条射线上所有采样点的情况,并且进行训练优化,让那些被遮挡的地方也能学到正确的体密度和RGB值,从而完成新视角合成。
NeRF的优缺点:
- 优点是连续的场景表达,照片级的新视角合成,可编辑。因为我们输入网络的位置xyz可以不受分辨率限制,可以是任意值,就看NeRF学的细不细致了,所以是连续的场景表达。为了学到高频的细节NeRF还对位置和方向进行正弦编码,让比较靠近的位置之间有着差别很大的编码。
- NeRF的缺点包括训练数据需求大,模型无法泛化,地图难以扩展,训练慢,渲染慢。对于一个物体的模型往往需要上百张图片训练一两天的时间,渲染一张图片也得几十秒,而且换个模型就得重新训练,因为最终获得的模型其实是MLP里面的参数,换个场景就得换个MLP。也正因为是一个MLP,所以很难去扩展地图。MLP的拟合能力终究有限,给它一系列的场景图片去训练,它往往更倾向于记住后续到来的数据,这也被称作遗忘问题。
SLAM
simultaneous localization and mapping,同步定位与建图
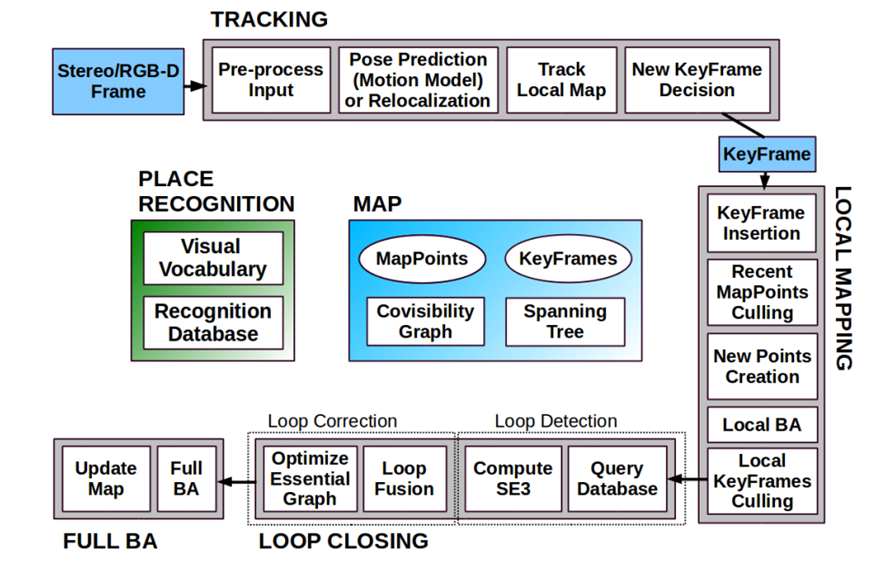
- 追踪 tracking(前端):从输入的图片或者深度数据中估计相机位姿,进而计算相机运动,从中抽取关键帧
- 建图 mapping(后端):从关键帧里构建地图,一般是根据特征点构建点云地图
- 优化 optimization:局部或者全局的相机位姿和地图优化
- 回环 loop closing:传感器的值或者位姿计算会在长时间的运行过程中产生漂移,回环模块检测到相机运行到了之前经过的地方的时候,会对这个漂移误差进行矫正
- 定位 location:当前端tracking追丢了的时候能保证重新获知相机位姿
NeRF与SLAM的结合
NeRF对SLAM带来的改进最直观的,是后端的建图部分。
NeRF地图的优势在于:
- 能够填补地图的空洞,NeRF通过射线采样和体密度,能让地图学到被遮挡的点后面的东西,从而实现空洞填补、新视角合成
- 新视角合成可以用来预测相机运动。比如,相机在运动过程中捕获了一帧图像,现在需要根据这帧图像去计算相机位姿,可以先用各种运动模型,比如说恒速模型,估计一个粗糙位姿,根据这个位姿用NeRF渲染出一张图来,图里面包含了之前没见过但是在新的这一帧里有的内容,然后把渲染图和真实图求一个Loss,来同时优化相机位姿和局部地图。事实上这个就是iMAP和Nice-SLAM的相机追踪原理。
- 除此之外,NeRF还有场景编辑功能,这对于VR、AR应用来说是很友好的,这也是NeRF的落地方向之一。NeRF based SLAM可以不用先建立点云,再生成mesh,再贴图等等步骤,直接一步到位,端到端地生成AR或者VR直接可用的地图。
填补空洞(iMAP)

NeRF-SLAM
