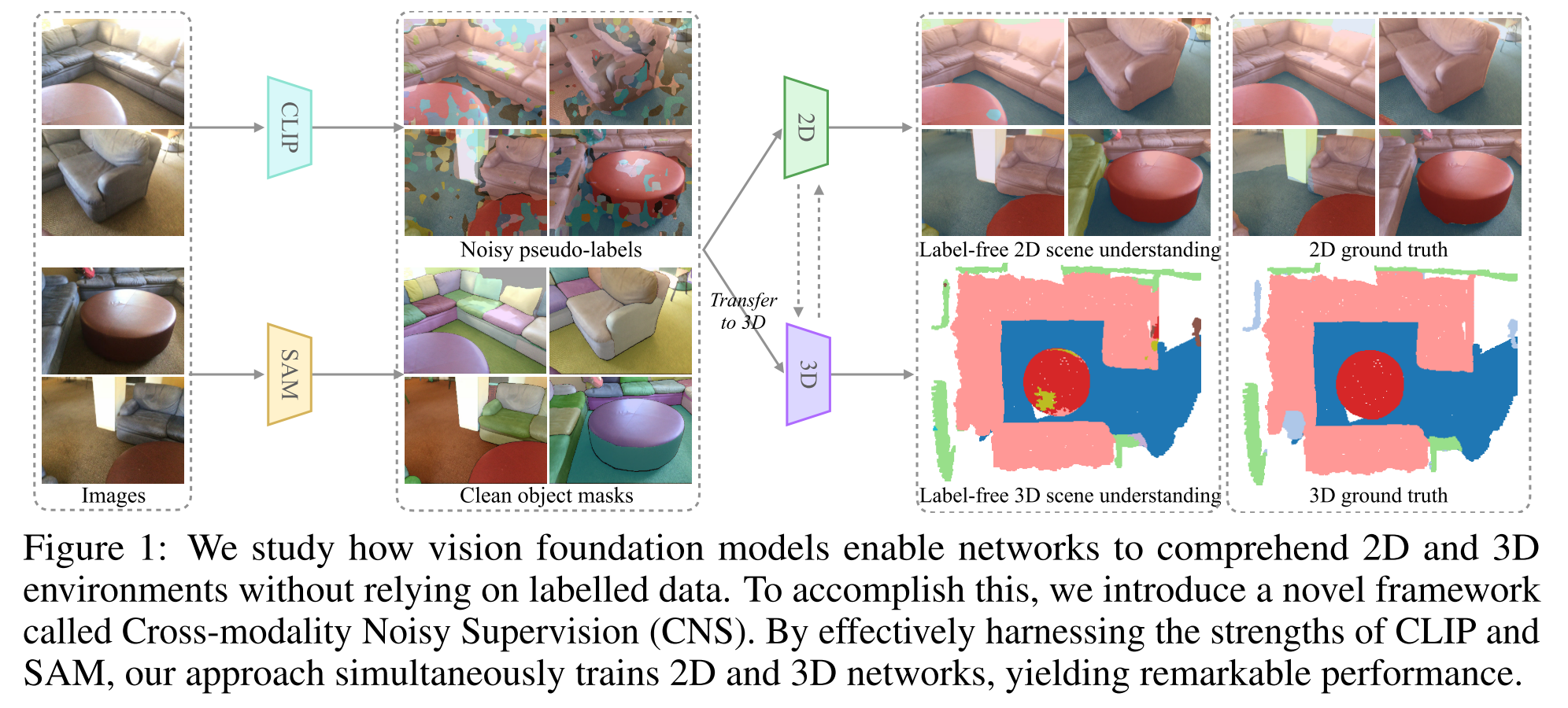
Towards Label-free Scene Understanding by Vision Foundation Models
label-free scene understanding
主要的挑战在于如何利用CLIP生成的带噪伪标签来有效的监督网络
Methodology
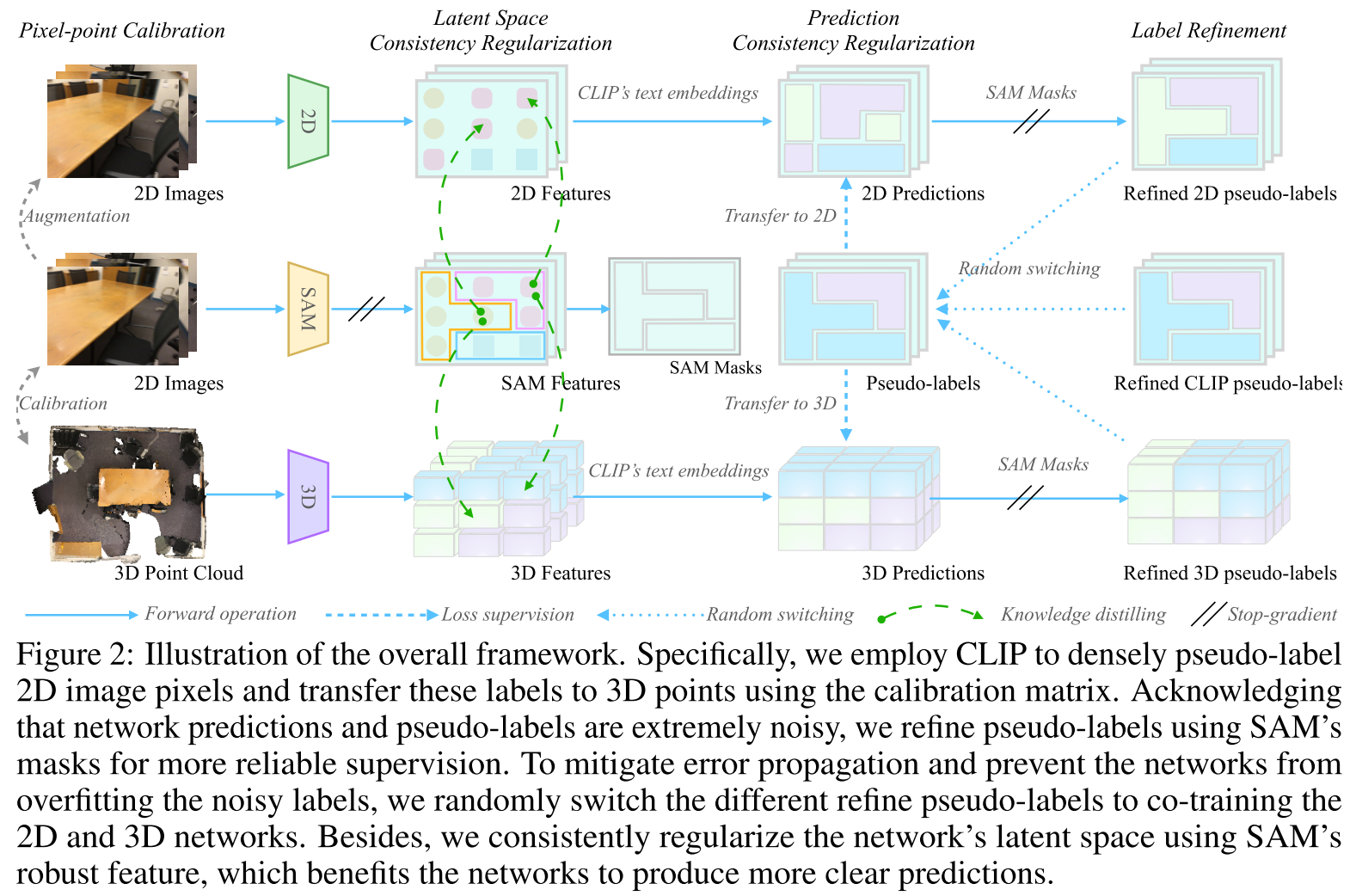
Cross-modality Noisy Supervision
- Pixel-point Calibration
- $\{c_i,s_i,x_i,p_i\}^N_{i=1}$,$c_i,s_i,x_i,p_i$分别表示第i对pixel-point的:CLIP像素特征,SAM像素特征,2D network像素特征,3D network点特征
- Pseudo-labeling by CLIP
- follow MaskCLIP & CLIP2Scene
- 将CLIP像素特征与预定义的类别名对应的CLIP文本特征计算相似度,将最大相似度的作为伪标签
- 伪标签可以transfer到对应的像素和点云上,$P_{s_i}=P_{x_i}=P_{p_i}=P_{c_i}$
- Label Refinement by SAM
- 使用投票机制,同一个mask内的pixels and point pseudo-labels对应同一个语义
- SAM细化后得伪标签记为$\{P^_{c_i}\}^N_{i=1}$,$\{P^_{x_i}\}^N_{i=1}$和$\{P^*_{p_i}\}^N_{i=1}$
Prediction Consistency Regularization
- 训练过程分为两个阶段
- 第一阶段利用$\{P^_{x_i}\}^N_{i=1}$和$\{P^_{p_i}\}^N_{i=1}$作为伪标签,使用Cross-entropy loss来同时监督2D和3D networks
- 第二阶段则是等概率随机指定$R_i^ \in \{P^_{x_i},P^_{p_i},\hat P^_{x_i},\hat P^_{p_i}\}$作为伪标签训练2D和3D network,其中$P^_{x_i},P^_{p_i}$是前面CLIP+SAM细化得到得,$\hat P^_{x_i},\hat P^*_{p_i}$则是2D 和3D network自己预测出得伪标签通过SAM细化得到的,这一self-training和cross training的过程,目的是reduce the error propagation flow of noisy prediction
- 在第一阶段训练2D和3D网络,用几个epochs来预热网络,然后无缝切换到第二阶段。通过这种方式,减少了噪声预测的错误传播流,并防止网络过度拟合噪声标签。
- 训练过程分为两个阶段
Latent Space Consistency Regularization
- 将知识从SAM特征空间迁移到目标2D和3D网络学习的图像和点云特征空间
- 将SAM特征和2D\3D特征在投影后的空间中对齐

Experiments
- ScanNet
- ScanNet consists of 1,603 indoor scans, collected by RGB-D camera, with 20 classes, where 1,201 scans are allocated for training, 312 scans for validation, and 100 scans for testing. Additionally, we utilize 25,000 key frame images to train the 2D network.
- nuScenes