Pixel2Mesh
Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images
- Volume和点云缺乏物体表面的细节信息
- Mesh模型用途更广泛,轻量,且细节丰富
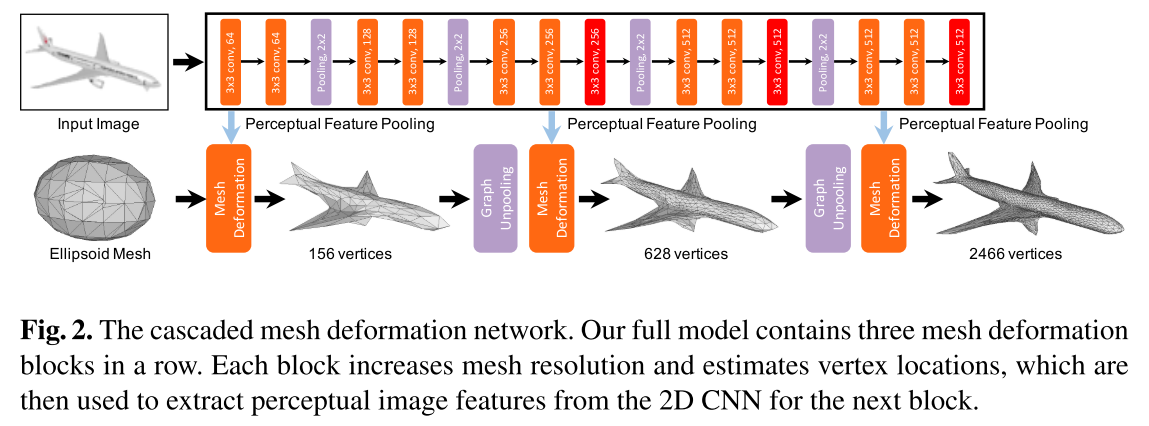
- 输入单张RGB图像(Input Image),并初始化一个椭球体作为初始三维形状(Ellipsoid Mesh)
- 全卷积提取图像特征(图中上半部分)
- 通过Perceptual Feature Pooling来引入图像特征来引导调整图卷积网络中的节点状态
- 图卷积来表示三维mesh,并对三维mesh不断进行形变,提升角点数量,coarse-to-fine得到最终的输出(图中下半部分)
- graph uppooling实现图节点数量上采样,获得更加精细的mesh
- 将3D Mesh中的顶点和边定义为图的节点和边
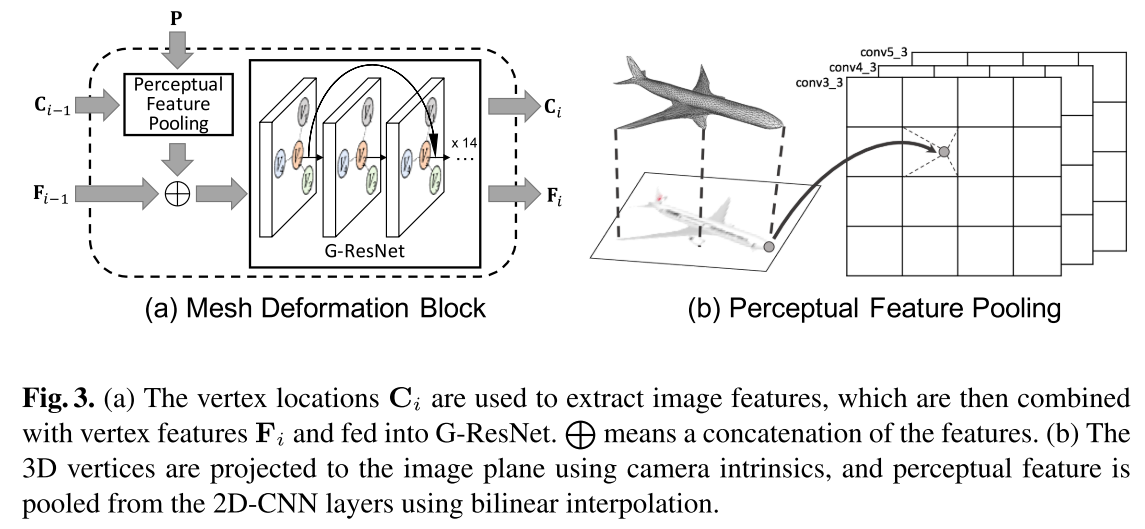
- Mesh Deformation Block
- C代表三维顶点坐标,P表示图像特征,F表示三维顶点的特征
- Perceptual Feature Pooling的作用是根据三维顶点坐标$C_{i-1}$去图像特征P中提取对应信息(找投影位置)
- 不同时刻,不同模态的特征融合作为G-ResNet的输入,然后输出当前时刻的三维顶点坐标和三维顶点特征
- ShapeNet 13个物体类别
Pixel2Mesh++
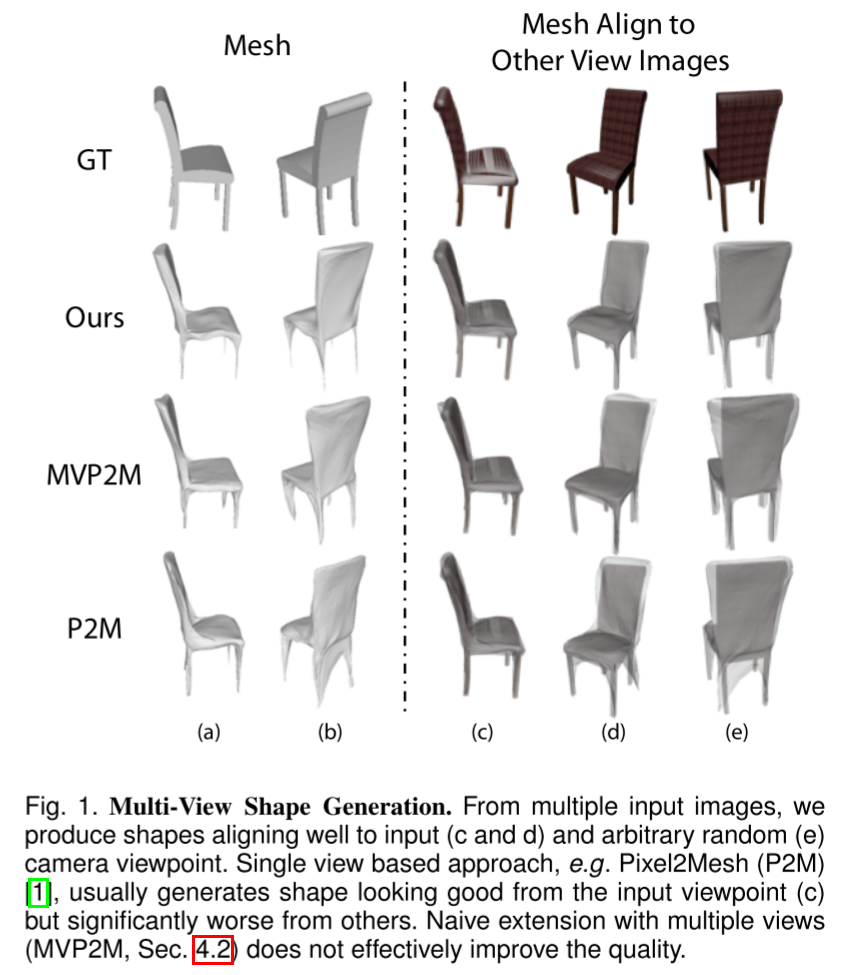
从几张已知相机位置的多视角彩色图片生成三角网格模型(3D Mesh)
Motivation
单视图生成3D形状受限于有限的观察视角,被遮挡区域中会产生粗糙的几何形状,并且在推广到非训练域数据的情况下进行测试时效果不佳,例如跨语义类别。传统多视图几何方法从视图之间的对应关系中准确地推断出3D形状,已经有很好的定义,并且不易受到泛化问题的影响。不过传统方法在多视角图片数量非常有限的情况下(比如小于5张)难以显式解出形状,但多视角的形状信息则可能直接由神经网络隐式编码和学习。
Methodology
输入物体的多视角彩色图像(已知或未知相机位姿),输出世界坐标系3D mesh
- 3D shape prediction
- camera pose estimation
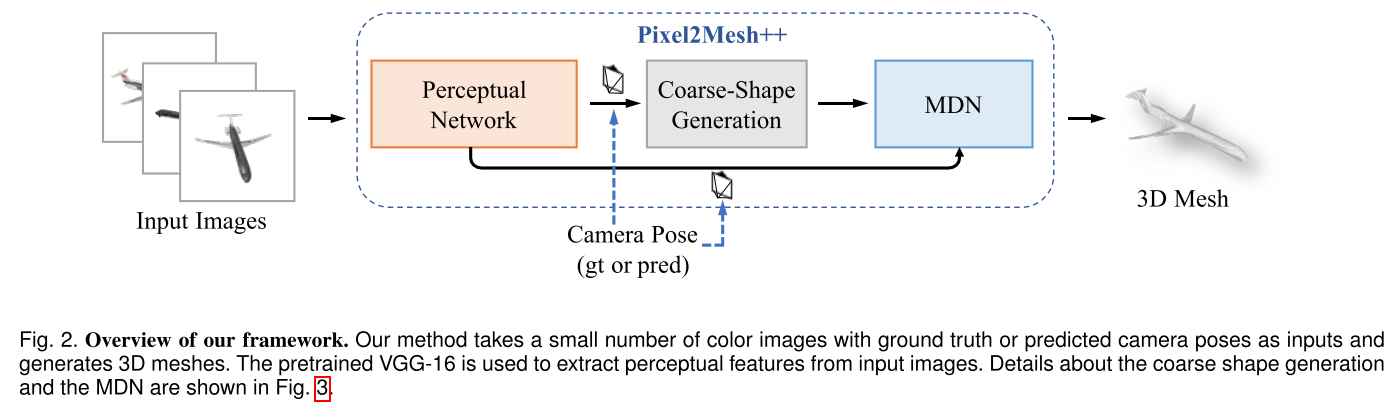
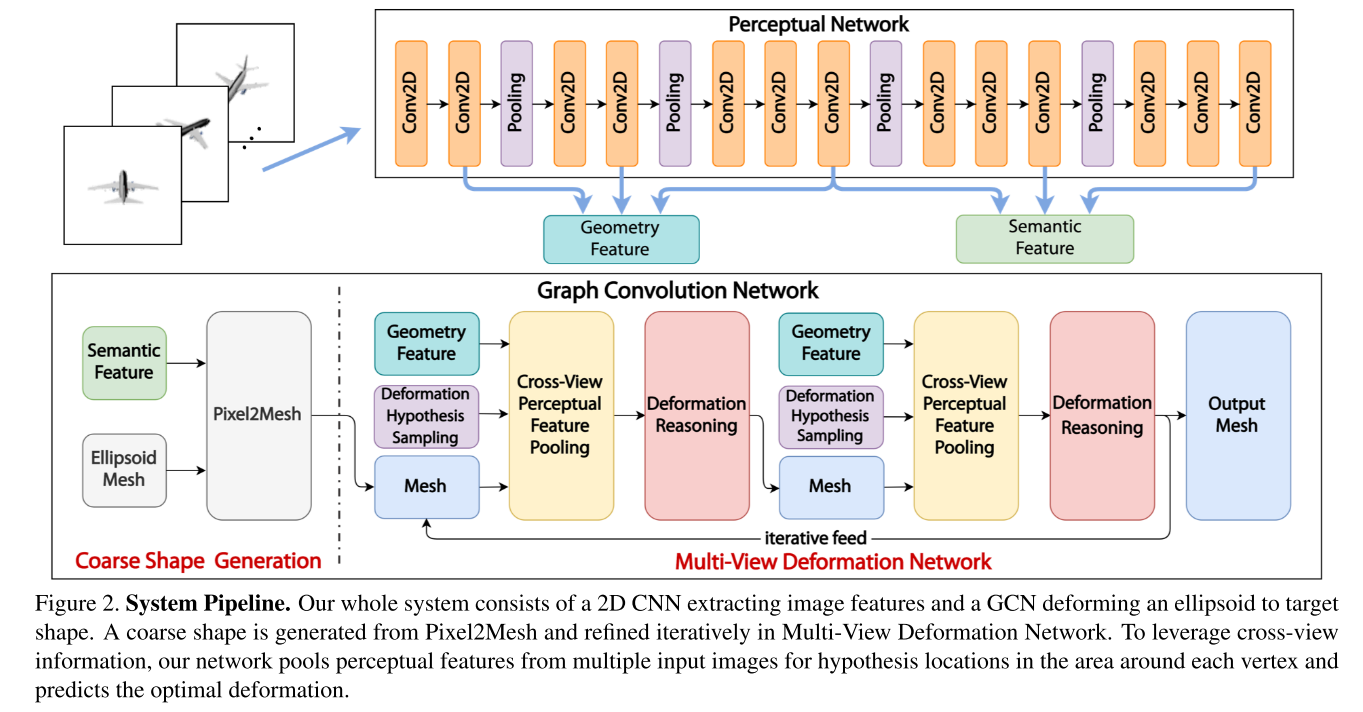
- 先使用Pixel2Mesh / DISN生成粗略的形状,然后使用Multi-View Deformation Network (MDN)进行细化
Multi-View Deformation Network (MDN),本质是一个GCN,但不同于其他基于GCN的模型,MDN中的图除了直接表示3D Mesh的顶点,还有顶点位置与形变假设(Deformation Hypothesis)组成的局部GCN
- 使用Deformation Hypothesis Sampling来获得潜在的形变候选位置
- 使用Cross-View Perceptual Feature Pooling来从多张图片中汇集跨视角的特征信息
- 由Deformation Reasoning模块学习从特征中推断出最佳的变形位置
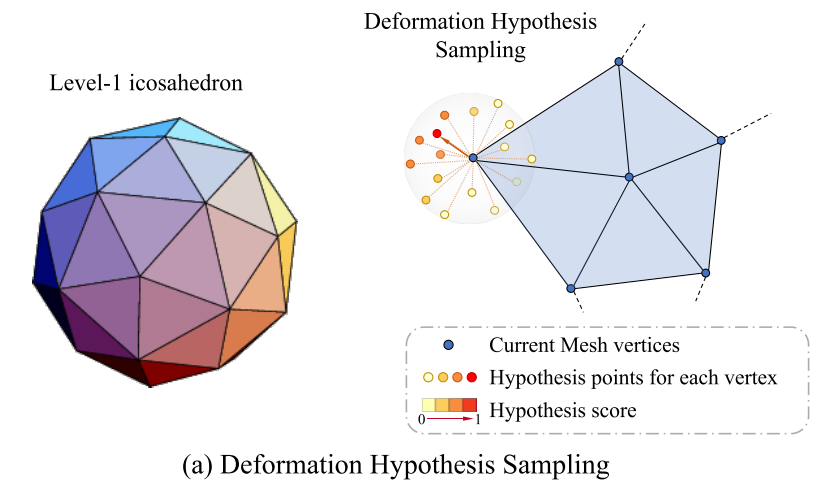
Deformation Hypothesis Sampling
为每个顶点选择形变的假设位置等价于在顶点周围的3D空间中采样点,作者从Level-1 Icosahedron上采样42个点,并在 Icosahedron表面和Mesh的顶点之间构建局部个GCN结构(43个nodes,120+42=162条edges),用以预测Mesh顶点的形变
To uniformly explore the nearby area, we sample from a level-1 icosahedron centered on the vertex with a scale of 0.02, which results in 42 hypothesis positions.
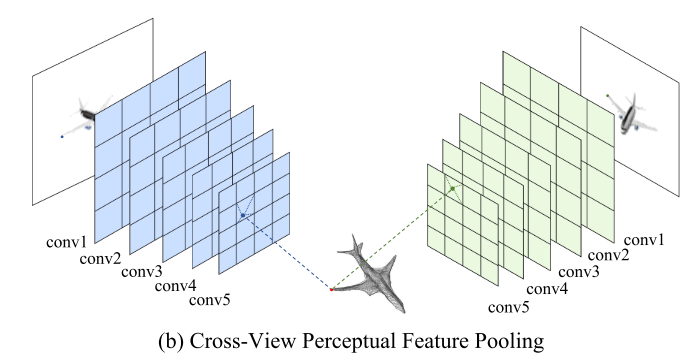
Cross-ViewPerceptual Feature Pooling
如何有效从多视角(Multi-view)图像中获取信息是多视图形状生成的关键。受Pixel2Mesh启发,本文也使用VGG16的结构来提取perceptual feature。由于假设已知相机内参和外参,每个顶点和形变假设都能在所有的图像平面利用虚拟相机投影得到2D坐标。与Pixel2Mesh不同,本文使用更靠前的卷积层,以拥有更大的特征图空间尺寸和更局部的特征信息。
在汇集多个图像的特征时,concatenation往往是一种无损的aggregate方式,但这样将导致网络结构与输入图片数量相关。在多视角形状分类任务中使用的统计特征(statistics feature)能解决这一问题。本文通过将任意数量图片的统计量信息(mean, max, std)进行拼接,得到与视角数量无关的跨视角特征。基于统计的图像特征与3D坐标拼接在一起作为后续用于推理形变位置的特征信息。
In total, we compute for each vertex and hypothesis a 339 dimension feature vector
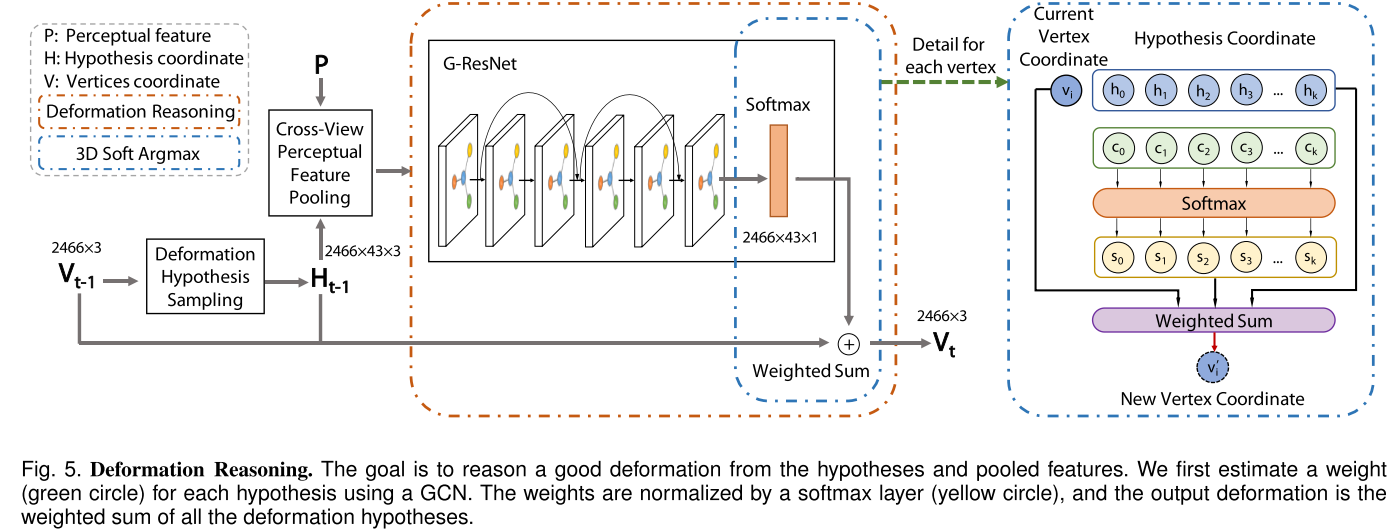
Deformation Reasoning
为每个顶点推理最优的形变位置是Pixel2Mesh++能够进一步提升形状质量的关键。值得注意的是选择最优的假设需要不可导的argmax操作,因此本文还提出了可导的寻找理想形变假设位置的soft-argmax模块。
具体来说,跨视角的特征$P$通过GCN(scoring network,由6个graph residual convolution layers组成),为每个假设预测权重$c_i$ ,权重再通过softmax层来归一化为选择的概率$s_i$其中$\Sigma^{43}_{i=1}{s_i}=1 $ ,顶点的位置被更新为这些假设坐标$h_i$的加权和$v=\Sigma^{43}_{i=1}s_i*h_i$, 其中$h_i$是每个变形假设的位置,包括顶点原本的位置。
Differentiable Renderer
We use common mesh rasterizer renderer pipeline [59], [73] as an optional component.
当可以从输入对象获得图像的轮廓时,可以通过可微分渲染器将预测形状的轮廓与多视图输入轮廓图像进行匹配来进一步优化对象的3D形状。
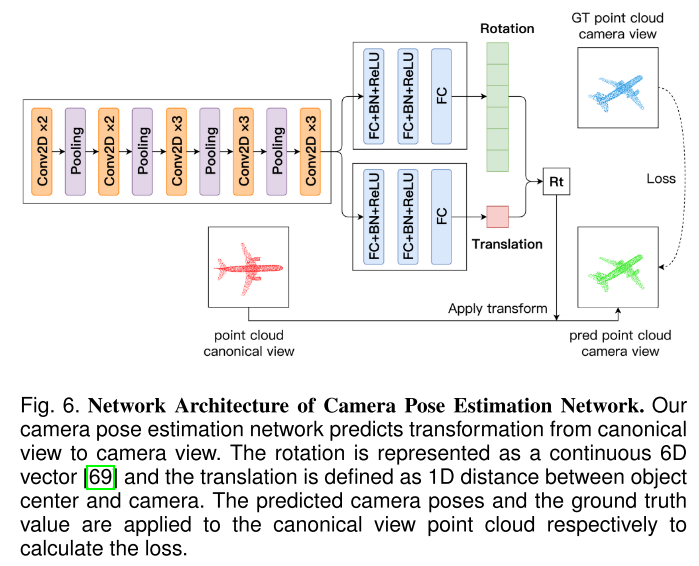
Camera Pose Estimation Network
当相机位姿未知时,需要从给定的图像中预测对应的相机外参
Experiment
该数据集使用ShapeNet [74]的子集创建,该子集包含来自13个类别的50 k个3D CAD模型。每个模型是从24个随机选择的摄像机视点渲染的,并给出了摄像机的内在和外在参数。