Semantic Abstraction
Semantic Abstraction: Open-World 3D Scene Understanding from 2D Vision-Language Models
基于open-set vocabulary and out-of-domain visual input对3D环境进行感知和推理是机器人在3D世界中进行操作的关键技术,Semantic Abstraction (SemAbs), a framework that equips 2D Vision-Language Models (VLMs) with new 3D spatial capabilities, while maintaining their zero-shot robustness.
赋予2D VLMs 3D空间能力的同时保留2D VLMs的zero-shot robustness
- completing partially observed objects
- localizing hidden objects from language descriptions
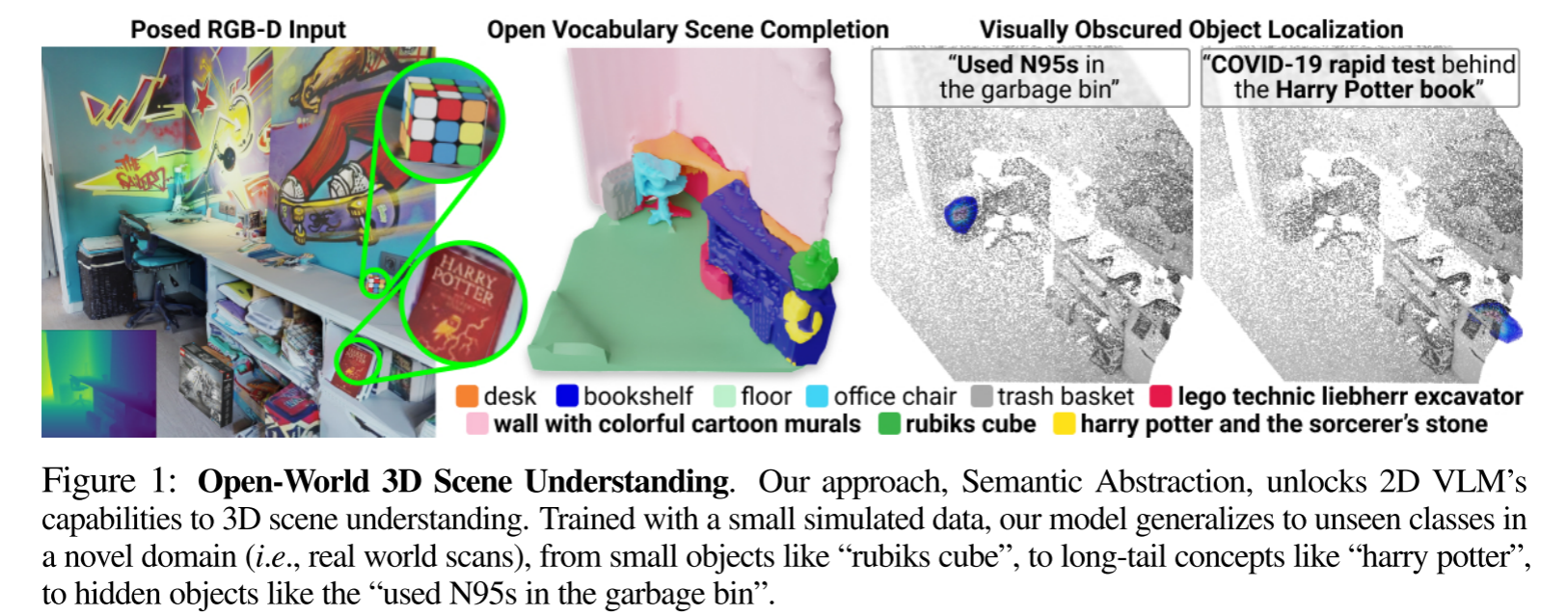
- novel vocabulary (i.e., object attributes, synonyms of object nouns)
- visual properties (e.g. lighting, textures)
- domains (e.g. sim v.s. real)
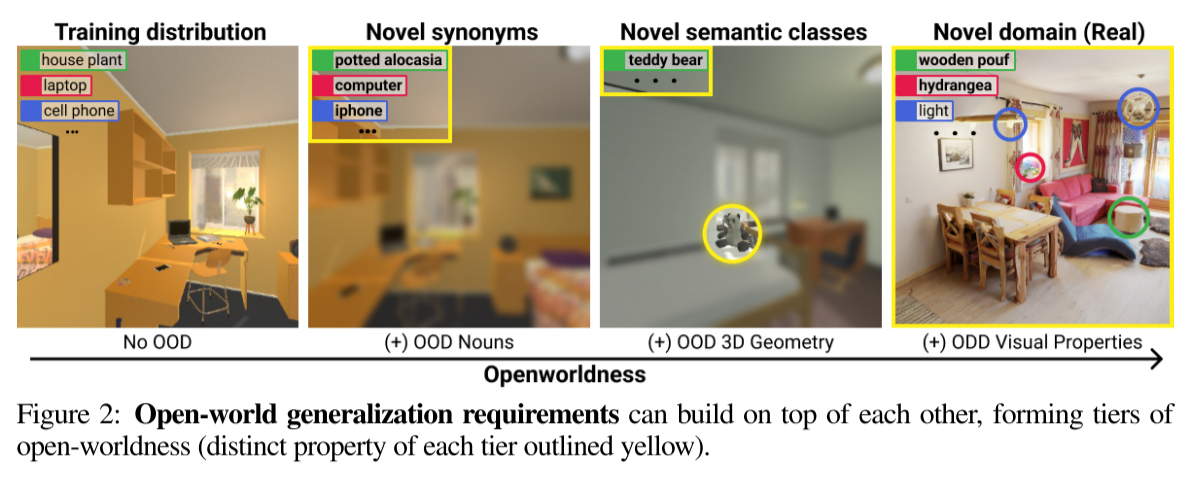
Motivation

Methodology
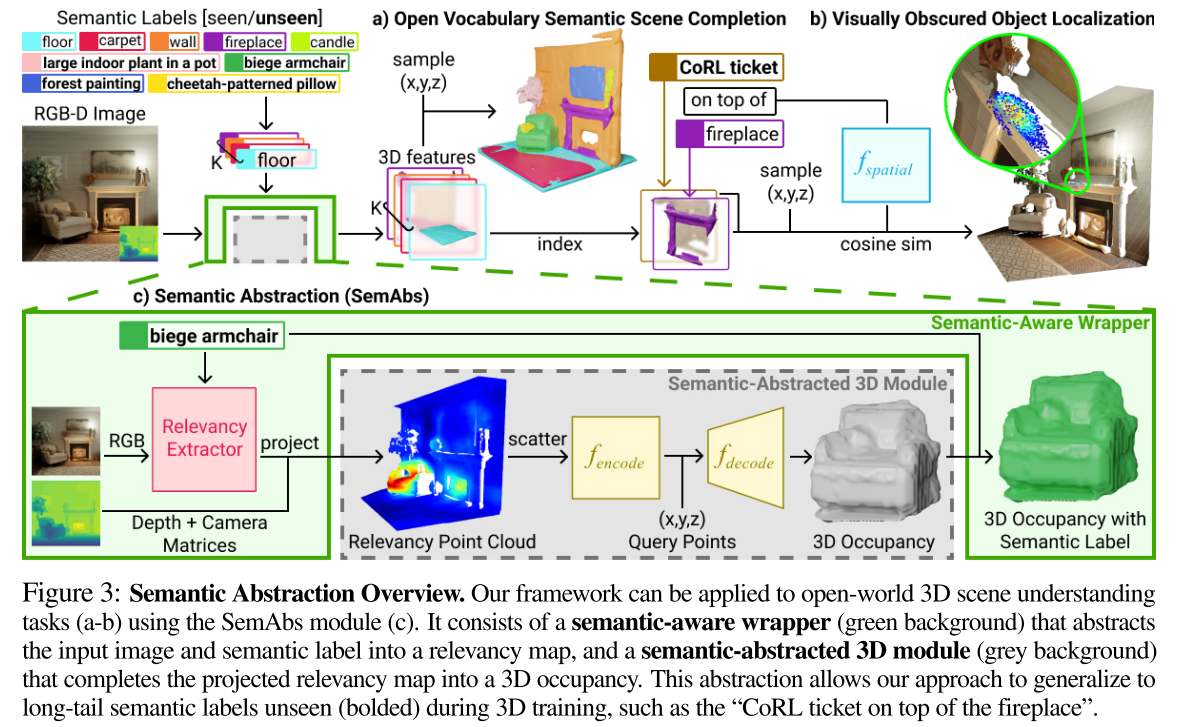
Abstraction via Relevancy
输入RGB-D $\mathcal{I} \in \mathbb{R}^{H\times W}$ + object class text label $\mathcal{T}$ (e.g. “biege armchair”),输出 the 3D occupancy $\mathcal{O}$ for objects of class $\mathcal{T}$
two submodules
The semantic-aware wrapper (Fig 3c, green background)
计算relevancy map $\in \mathbb{R}^{H\times W}$,每个像素的值表示该像素对$\mathcal{T}$的VLM分类得分的贡献,relevancy map可被视为文本标签的粗略定位
semantic-abstraction/generate_relevancy.py
将relevancy map投影到3D,获得Relevancy Point Cloud $\mathcal{R}^{proj}=\{r_i\}_{i=1}^{H\times W}$(每个点$r_i \in \mathbb{R}^4$, a 3D location with a scalar relevancy value)
The semantic-abstracted 3D module (Fig 3c, grey background)
treats the relevancy point cloud as the localization of a partially observed object and completes it into that object’s 3D occupancy
将$\mathcal{R}^{proj}$体素化,得到3D voxel grid $\mathcal{R}^{vox}\in \mathbb{R}^{D\times 128\times 128\times 128}$
疑问:scatter过程如何获得$D$维特征?原本是3D location + scalar relevancy value
然后将3D Unet作为encoder,对$\mathcal{R}^{vox}$进行特征提取,获得3D特征:
$f_{\text {encode }}\left(\mathcal{R}^{\text {vox }}\right) \mapsto Z \in \mathbb{R}^{D \times 128 \times 128 \times 128}$
可以从$Z$中采样得到任意一个点云$q$位置的特征,然后使用一个MLP进行解码,获得occupancy probability
$f_{\text {decode }}\left(\phi_{q}^{Z}\right) \mapsto o(q) \in[0,1]$
$f_{\text {encode }}$和$f_{\text {decode }}$使用3D dataset训练
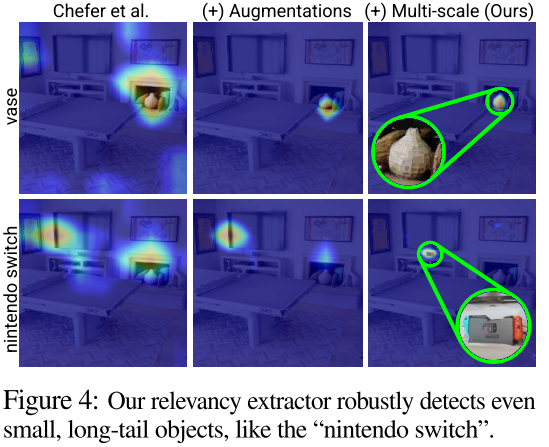
A Multi-Scale Relevancy Extractor
基于gradcam
空间位置关系dataset(针对单张图像)
behind, left of, right of, in front, on top of, and inside
