Open Vocabulary 3D Scene Understanding
CVPR2022 PointCLIP
PointCLIP: Point Cloud Understanding by CLIP
第一篇将CLIP用于3D点云的工作,实现了点云分类的zero-shot learning和few-shot learning
Methodology
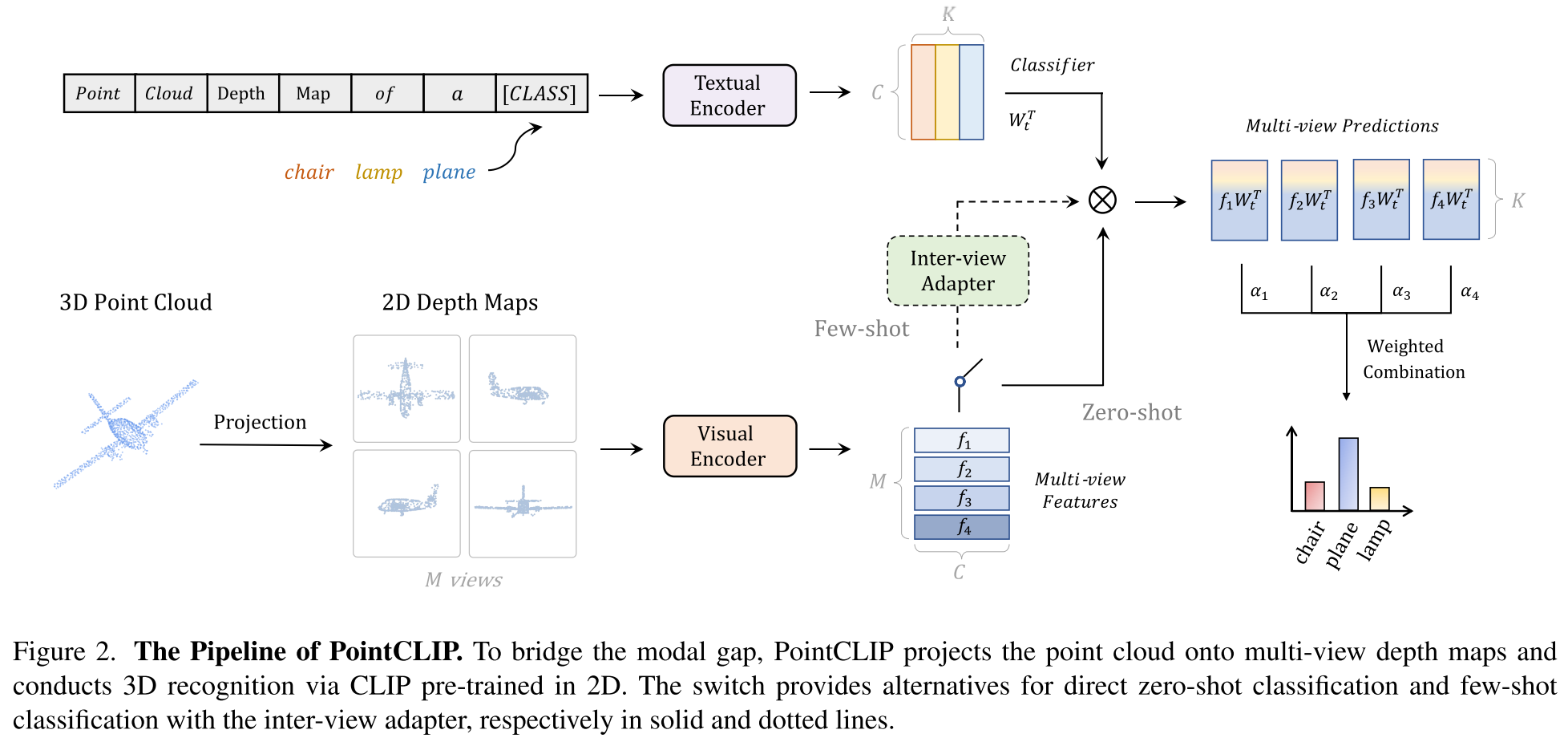
抽取点云特征
使用投影的方式,将3D的点云投影到几个预定义的平面(6个正交的视角),变为2D图像,具体来说,投影到bottom view就是将坐标为$(x,y,z)$的点投影到图像平面上的$([x/z],[y/z])$,投影得到的图像是缩小的图,近大远小。没有使用卷积将1通道转换为3通道,而是直接将深度$z$作为像素值,并复制到每个通道,得到3通道图像。
Zero-shot Classification
经过投影获得了$M$个视角的投影深度图,然后利用CLIP的视觉编码器提取特征,同时用CLIP的文本编码器提取”point cloud depth map of a [CLASS]”的文本特征,计算每个视角的视觉特征和文本特征的相似度,然后加权得到最终的相似度(logits)。但这种zero-shot的分类结果和有监督相差甚远,在ModelNet40数据集上的准确率只有20.18%,基本不太可用。原因可能是点云投影图像其实和图像存在较大的gap,且投影的方式其实会丢失信息。
Inter-view Adapter for PointCLIP
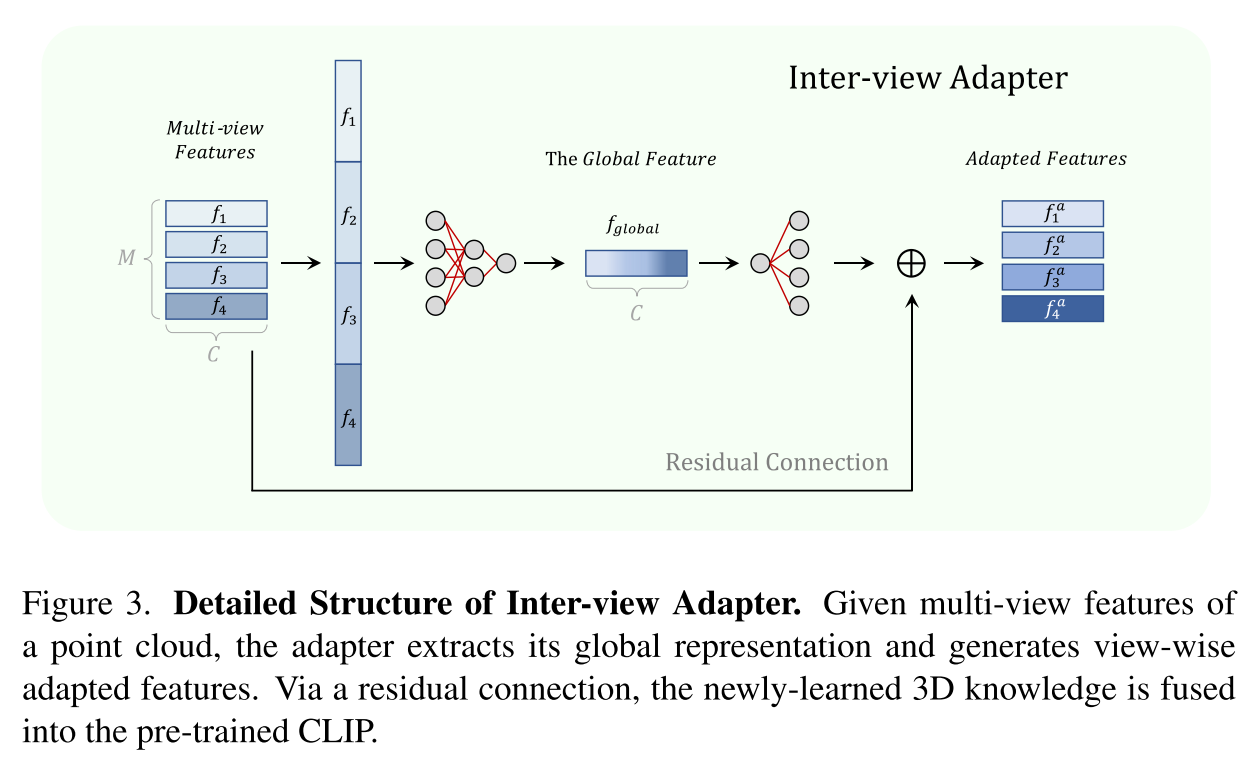
由于PointCLIP的zero-shot classification与有监督方法的存在较大的性能差距,作者考虑了更加实际的few-shot settings,借鉴CLIP-Adapter,提出了Inter-view Adapter(3层MLP),在训练时CLIP的编码器都是冻结的,仅通过交叉熵损失来微调这个可学习的adapter。few-shot samples就可以带来巨大提升,在ModelNet40上的结果,从20.18%提升到了87.20%,基本达到了有监督的方法的效果,并且只用了每个类别16个样本,不到全部数据的1/10。
Multi-knowledge Ensemble
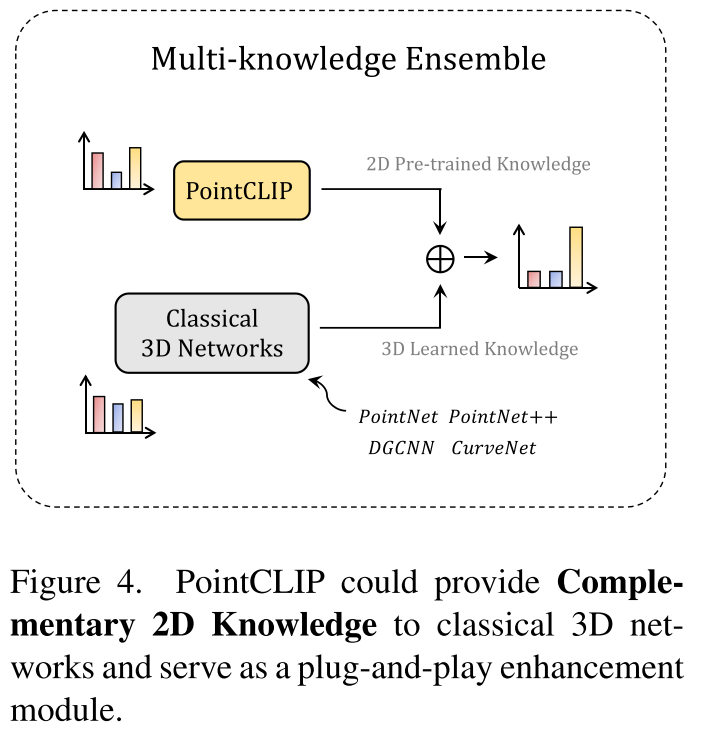
传统方法是在3D数据集上from scratch进行训练的,而PointCLIP继承了CLIP中包含的2D先验,作者认为是对以往方法的一个知识补充,因此提出进行模型集成,通过简单相加直接集成它们的预测logit作为最终输出,这为传统方法带来了性能提升,PointCLIP因此可以作为一个即插即用的模块使用。
Experiments
Datasets
- ModelNet10
- ModelNet40包含9843个样例和40个类
- ScanObjectNN
Discussion
- 投影得到的图像和CLIP训练所用图像之间的分布仍然存在巨大gap,如表示形式是深度图,没有颜色
- 投影方式会损失一部分3D的信息
- 多视角的特征融合采用了固定的权重
- CLIP文本端prompt template的小的变换会导致2-3%的性能波动
PointCLIP V2
PointCLIP V2: Adapting CLIP for Powerful 3D Open-world Learning
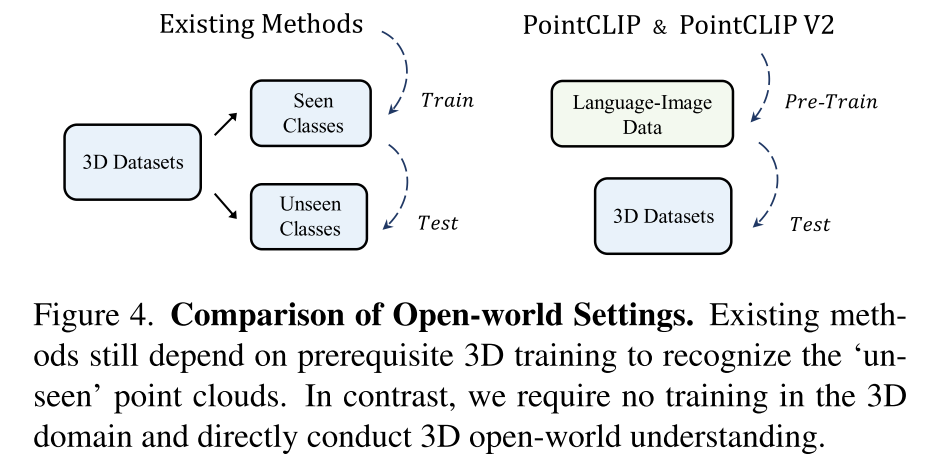
限制PointCLIP的zero-shot能力的两方面原因:
- 稀疏的视觉投影。直接投影的方式虽然简单,但是和自然图像有很大的差别,这限制了CLIP的特征提取效果
- 原始的文本提示方式。PointCLIP在CLIP中的2D prompt基础上加入了简单的domain-specific words比如”a depth map”,其实并没有很好的描述3D点云的形状等信息
因此PointCLIP V2就是从这两个方面入手:
生成更逼真的深度图,缩小投影点云和自然图像之间的gap
利用LLMs来生成3D信息的描述,作为CLIP的prompt
Methodology
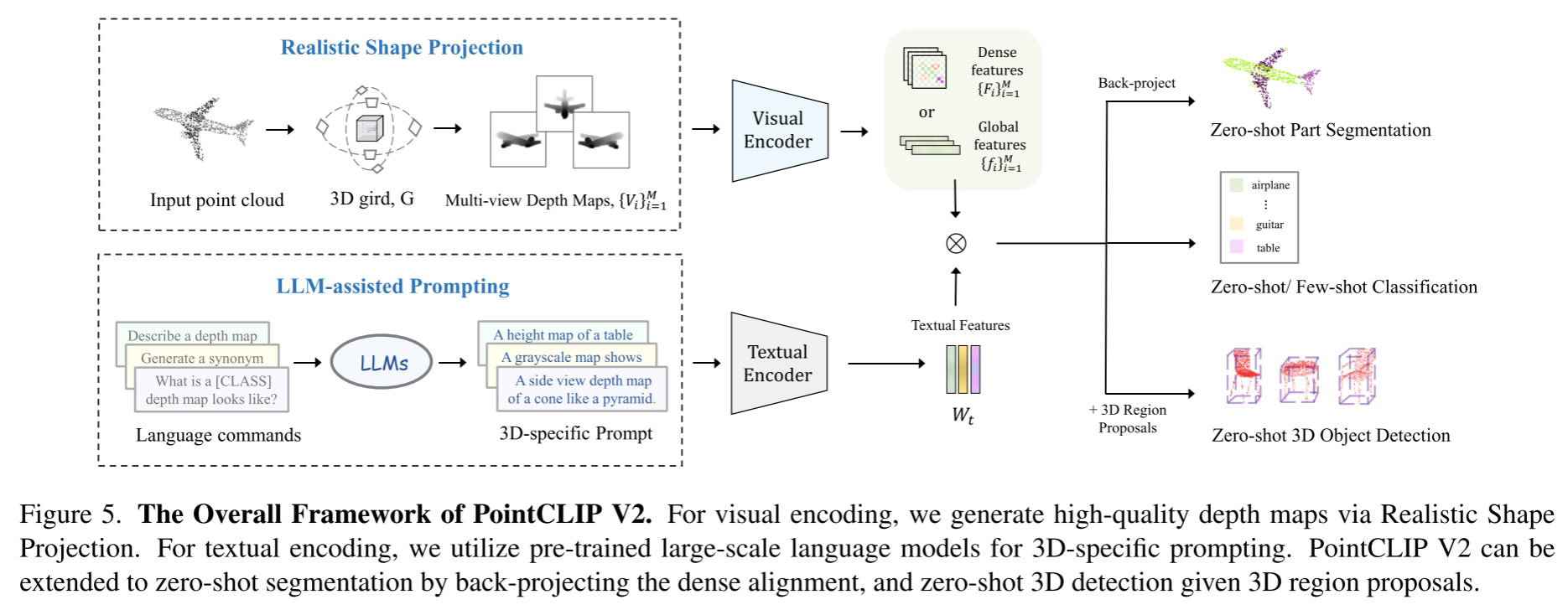
Realistic Shape Projection
将不规则的点云转换为具有深度值的基于网格的体素,然后在顶部应用3D局部池化和Gaussian filtering kernel。这样投影得到的三维形状由更稠密的点和更平滑的深度值组成
Voxelize → Densify → Smooth → Squeeze
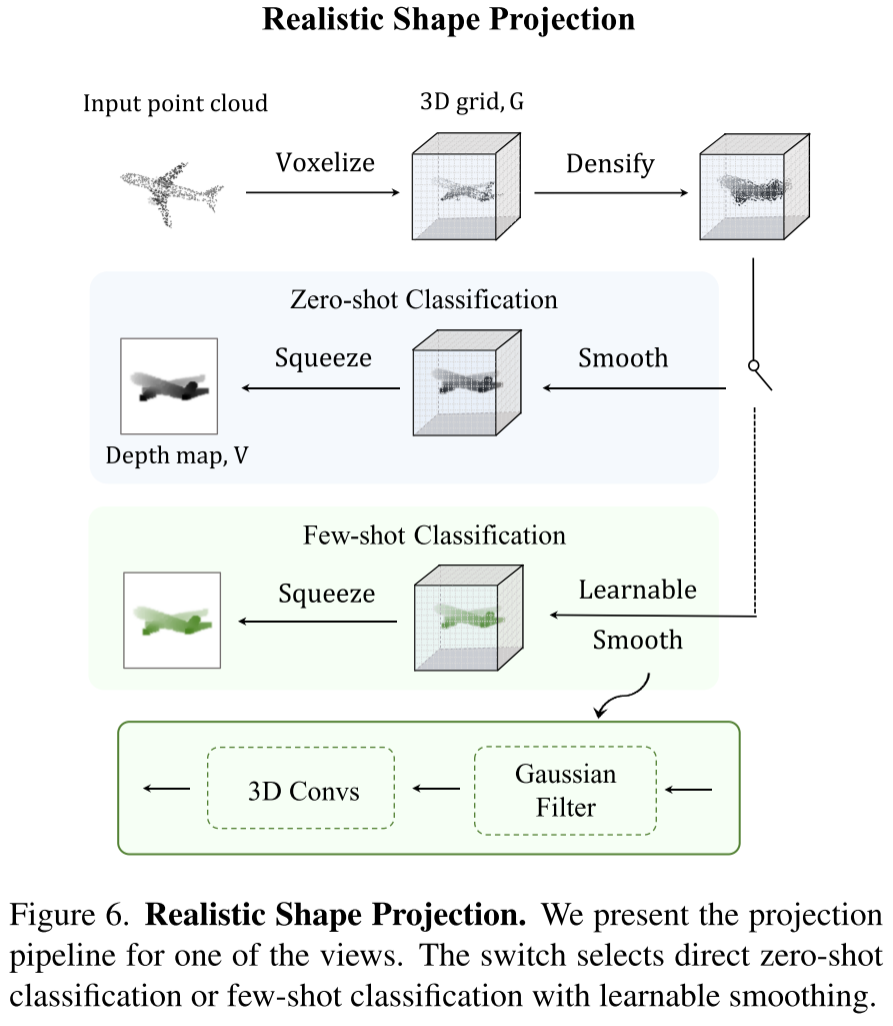
Voxelize
将点云体素化,就是将归一化的空间点坐标投影到一个个的体素上(类似于图像的像素),当多个点被投影到同一体素时,值取最小深度值,这是因为,从目标图像平面的角度来看,具有较小深度值z的点将遮挡较大的点。
经过体素化获得了包含稀疏深度值的3D网格$G$,由于点云的稀疏性,其大部分体素是空的。
Densify
为了解决稀疏性,作者通过局部最小池化来使gird更加密集,以保证视觉连续性。具体来说,作者通过局部空间窗口内的最小体素值重新分配$G$中的每个体素,这样的最小池化方式符合投影上遮挡视觉的直观认识。以这种方式,稀疏点之间的原始空体素可以被有效地填充有合理的深度值,而背景体素仍然保持为空,这导出更密集且更平滑的空间表示。
Smooth
局部池化操作可能会在3D表面上引入伪影,因此作者采用非参数高斯核来进行形状平滑和噪声过滤。通过选择合适的核大小和方差,滤波不仅可以去除由densify引入的空间噪声,而且可以保持原始3D形状中的边缘和角点的锐度。由此,我们获得了由3D网格表示的更紧凑和平滑的形状
Squeeze
简单地压缩$G$的depth dimension以获得投影深度图。我们提取每个深度通道的最小值作为每个像素位置的值,并将其重复三次作为RGB三通道的值。与PointCLIP 中的3D到2D透视变换相比,这样的基于网格的正交投影对于硬件实现更友好。
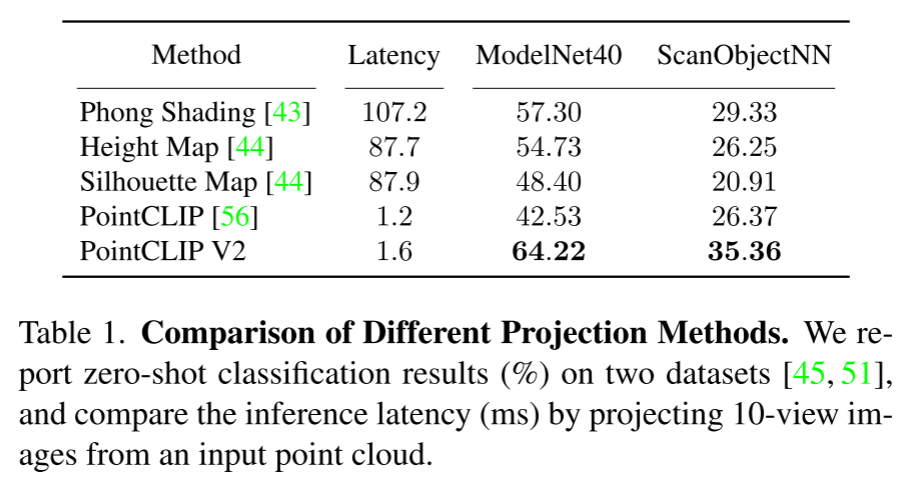
不同投影方式的推理时延和精度比较
LLM-assisted 3D Prompting
four series of 3D-related language commands

Open-world Understanding
- Zero-shot Classification
- Few-shot Classification
- Zero-shot Part Segmentation
- Zero-shot 3D Object Detection
PLA
PLA: Language-Driven Open-Vocabulary 3D Scene Understanding
3D scene understanding is a fundamental perception component in real-world applications such as robot manipulation, virtual reality and human-machine interaction
Open-vocabulary scene understanding aims to localize and recognize unseen categories beyond the annotated label space.
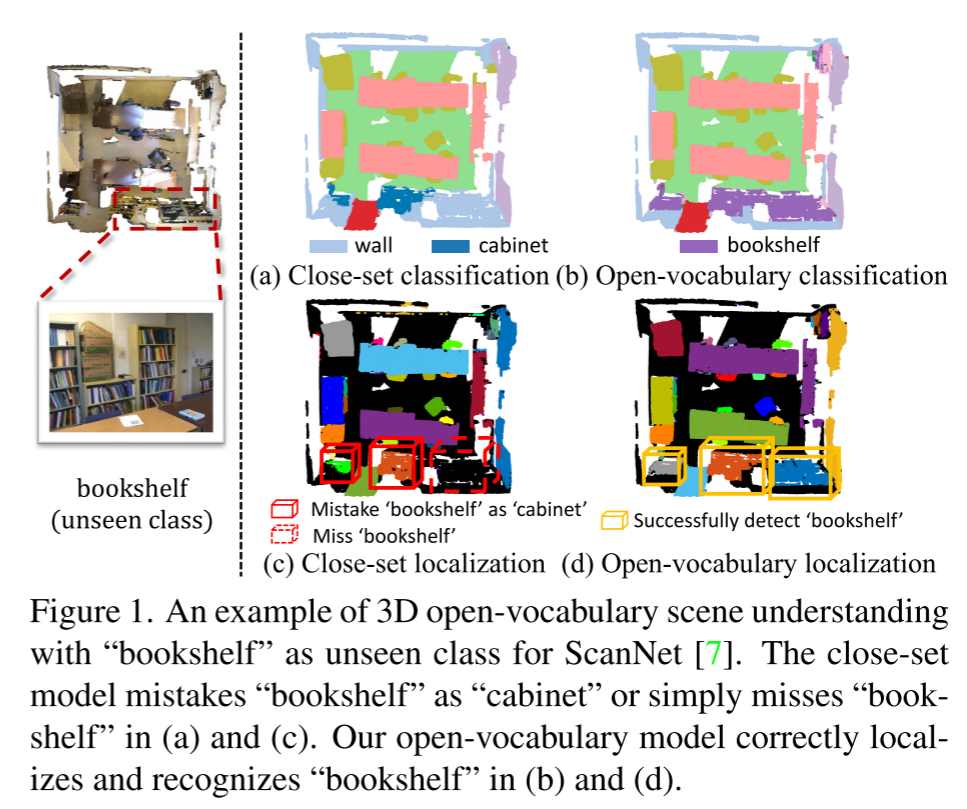
Motivation
PointCLIP, Clip2point这类将3D投影到2D再利用VLMs处理的方法实现object-level open-vocabulary recognition,但对于处理scene-level understanding tasks比如实例分割,这类方法有两个缺点:
- 需要多个RGB图像和深度图来表示3D样本,这在训练和推理期间产生大量计算和存储成本
- 3D到2D的投影引起了信息的丢失,无法直接从3D获取信息
core idea
exploit pre-trained VL foundation models to caption easily-obtained image data aligned with 3D data (i.e. the point set in the corresponding frustum to produce the image). Note that these images can be acquired through neural rendering or from the 3D data collection pipeline.
在获得3D-language association后,如何使得3D network能够从pseudo captions中学习language-aware embeddings,关键的挑战来自3D场景级数据中复杂的对象组成,这使得难以将对象与标题中的相应单词联系起来,这和包含单个居中对象的以对象为中心的图像数据非常不同。
Fortunately, the captioned multi-view images from a 3D scene are related by 3D geometry, which can be leveraged to build hierarchical point-caption pairs, including scene-, view- and entity-level captions.
Methodology
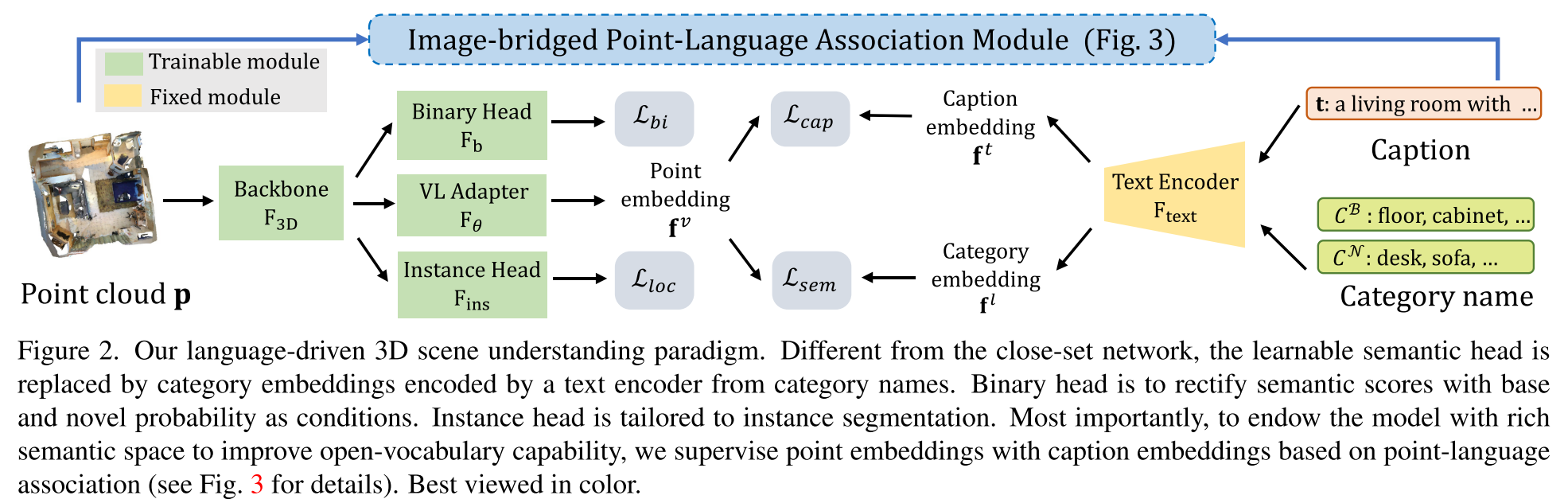
Text-Embedded Semantic Classifier
输入点云$p$经过backbone $\mathbf{F_{3D}}$得到特征$\mathbf{f}^p$
adapter $\mathbf{F}_{\theta}$对$\mathbf{f}^p$ 进行映射得到point embedding $\mathbf{f}^v$,然后与类别特征$\mathbf{f}^l$计算余弦相似度进行点云分类
Semantic Calibration with Binary Head
仅使用上述部分来得到的模型常常会将novel类分到base类中,因为训练阶段都是识别base类,不可避免地对base类别产生过度自信的预测,而不管它们的正确性如何
因此作者提出了binary calibration module来利用点属于base类或novel类的概率来校正语义得分。具体来说,在训练阶段作者使用binary head $\mathbf{F}_b$来区分annotated(即base类) points和unannotated(即novel类) points,使用BCELoss优化
$\mathbf{s}^{b}=\mathrm{F}_{\mathrm{b}}\left(\mathbf{f}^{p}\right), \quad \mathcal{L}_{b i}=\operatorname{BCELoss}\left(\mathbf{s}^{b}, \mathbf{y}^{b}\right)$
在推理阶段则使用预测的二元概率$\mathbf{s}^b$(点属于base类的概率和属于novel类的概率)
$\mathbf{s}=\mathbf{s}_{B} \cdot\left(1-\mathbf{s}^{b}\right)+\mathbf{s}_{N} \cdot \mathbf{s}^{b}$
Image-Bridged Point-Language Association
core idea is to use multi-view images of a 3D scene as a bridge to access knowledge encoded in VL foundation models
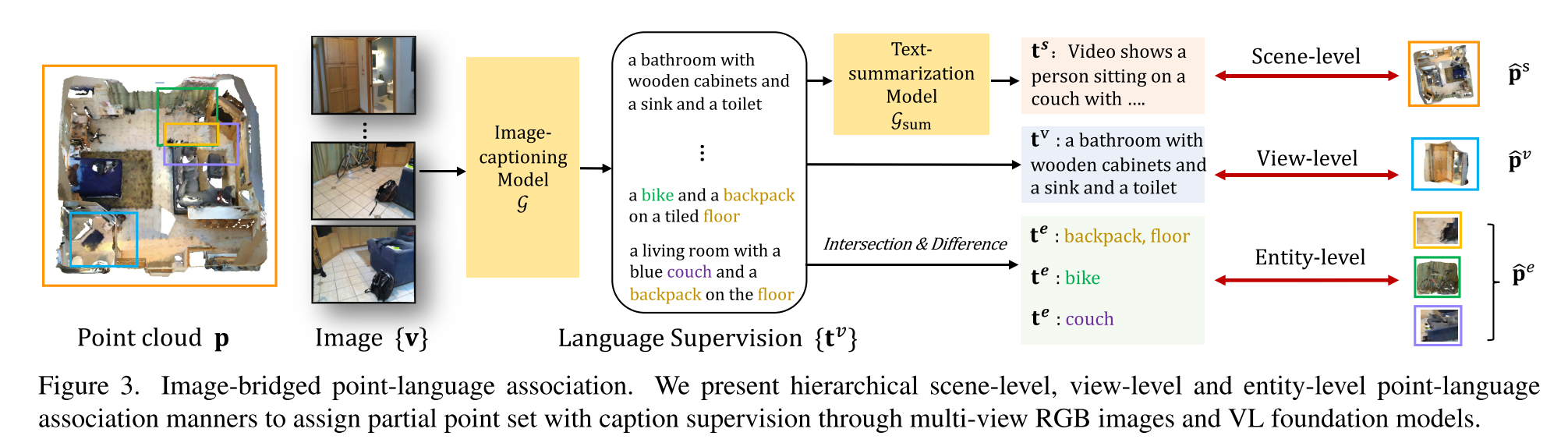
Caption Multi-View Images
虽然2D VL models没有在3D场景上训练,但是其产生的captions中包含的实体对象类别已经覆盖了ScanNet中的所有语义类类别,另外captions中还提供了对房间类型,语义类别,颜色纹理属性,空间关系
Associate Point Cloud with Language
在获得了image-caption pairs后,下一步是将point和language联系起来
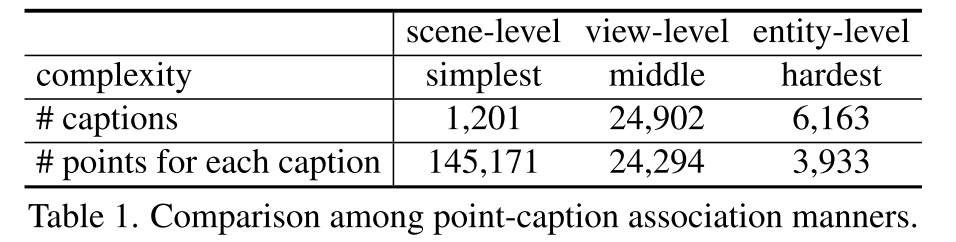
- Scene-Level Point-Caption Association
- 使用text summarizer将场景的所有2D image captions总结成一个场景描述
- View-Level Point-Caption Association
- 点反投影到3D空间中
- Entity-Level Point-Caption Association
- 将view-level captions中每条caption间实体的交集和并集抽取出来作为entity-level caption,对应的点云也取交集并集(并非采用2D目标检测的方式)
Contrastive Point-Language Training
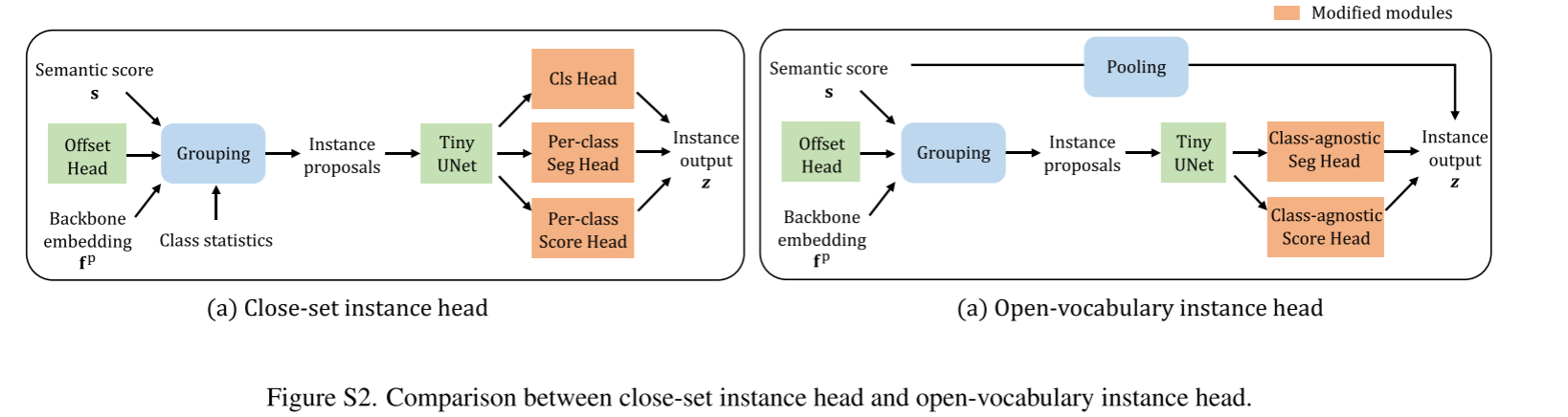
Open-vocabulary instance head
Experiment
Datasets and Perception Tasks
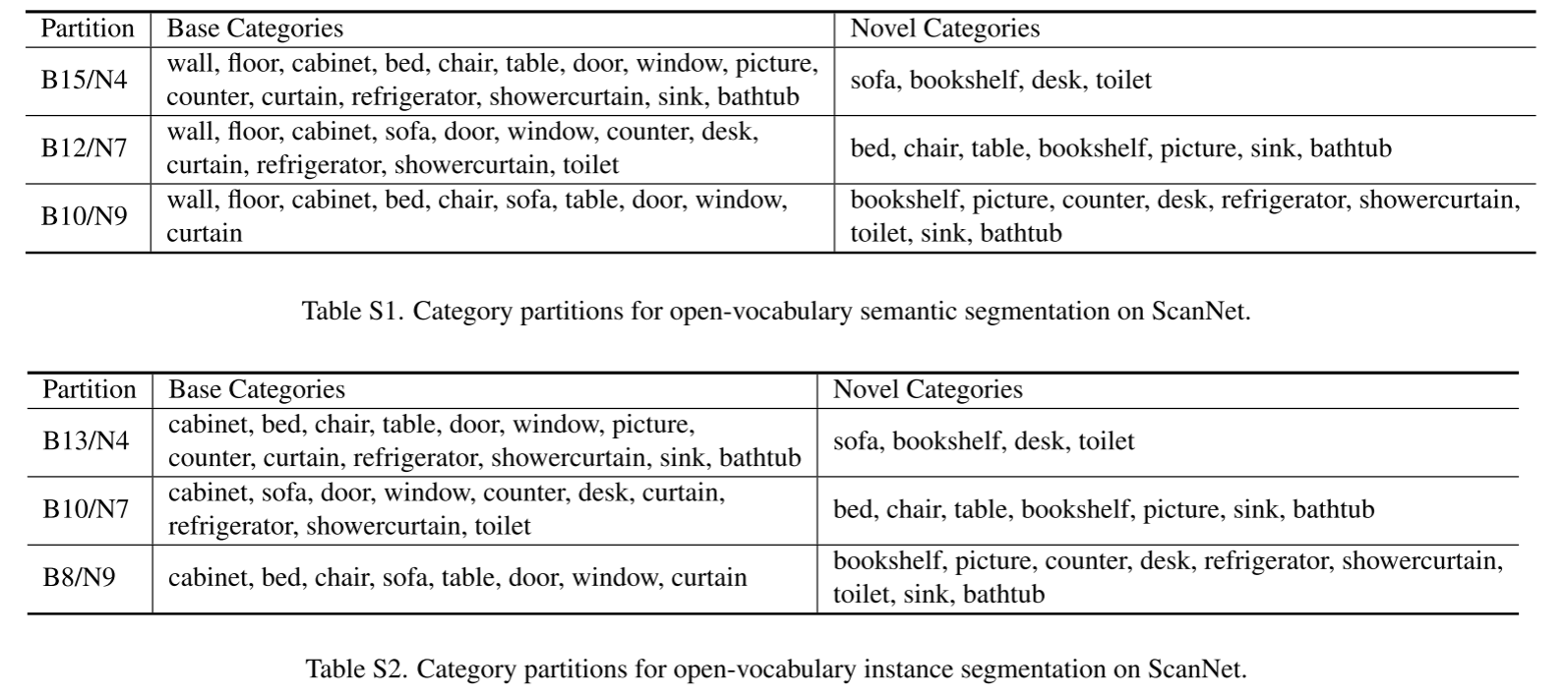
ScanNet 20类
- otherfurniture
- 剩余19类 base/novel 划分
- i.e. B15/N4, B12/N7 and B10/N9, where B15/N4 indicates 15 base and 4 novel categories
- As for instance segmentation, We also follow SoftGroup [38] to exclude two background classes(i.e. wall and floor) and thus obtain B13/N4, B10/N7, and B8/N9 partitions for instance segmentation on ScanNet
- 1,613 scenes (1,201 scenes for training, 312 scenes for validation and 100 for testing)
S3DIS 13类
Architectures and Baseline Methods.
- 3D encoder - sparse convolutional UNet [13, 6]
- 3d semantic segmentation with submanifold sparse convolutional networks
- text encoder - CLIP
- VL adapter - two fully-connected layers + batch normalization + ReLU
- binary head - UNet decoder
- instance head - SoftGroup
Limitation
- the calibration problem that the model tends to produce over-confident predictions on base classes,
which lies in both semantic and instance segmentation tasks- For semantic segmentation, though the binary head is developed to calibrate semantic scores for in-domain open-vocabulary scene understanding, it fails to rectify predictions for out-of-domain transfer tasks.
- Trained on the dataset-specific base/novel partition, the binary head is hard to generalize to other datasets with data distribution shifts, which encourages us to design more transferable score calibration modules in the future
- As for the instance segmentation task, though we largely address the localization problem for novel classes through fine-grained point-caption pairs, the calibration problem also exists in the proposal grouping process, where objects of novel classes cannot group well and probably obtain incomplete instance masks.