BuboGPT
BuboGPT: Enabling Visual Grounding in Multi-Modal LLMs
以往MLLMs对于图像给出的是粗粒度的描述和理解,而没有深入研究视觉对象和其它给定模态之间的细粒度关系。BuboGPT在MLLMs中引入visual grounding的能力
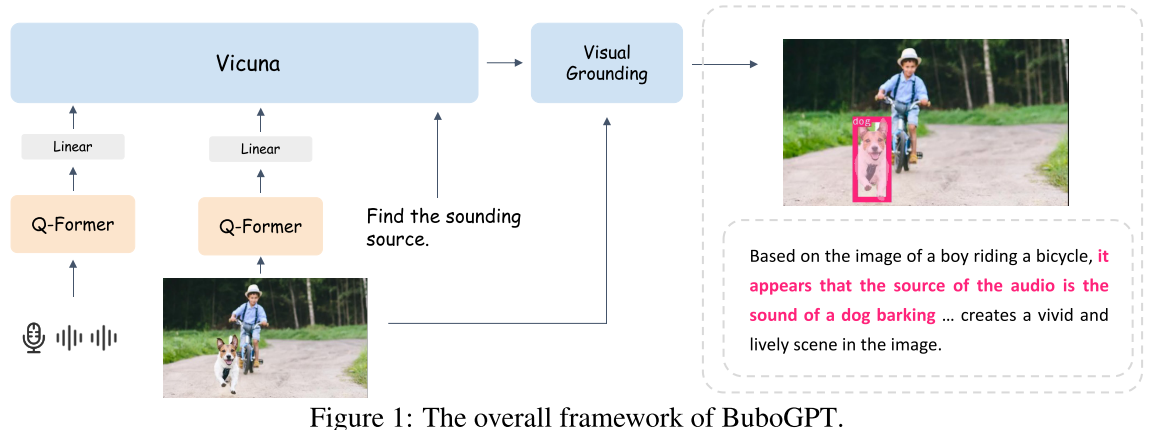
Methodology
Visual Grounding Pipeline
- tagging module (Recognize Anything Model (RAM))
- grounding module (Grounding DINO + Segment Anything Model (SAM))
- entity-matching module (使用GPT实现,prompt)
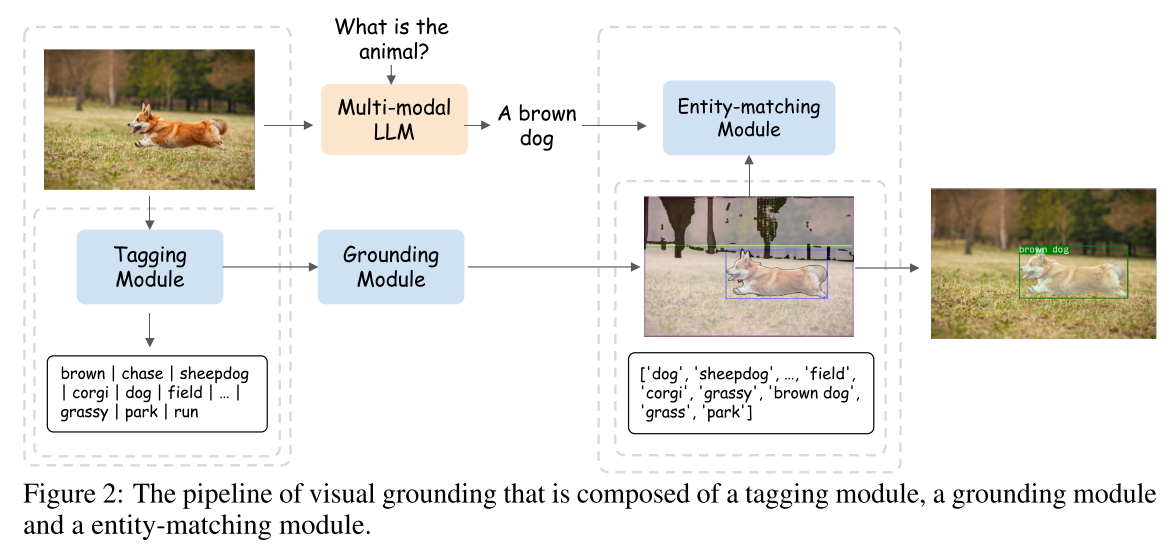
entity-matching module中使用的prompts
1 | # few-shot examples |
Multi-Modal LLM Training
- aligns with the LLM with a Q-former for each modality
- visual encoder - BLIP2
- audio encoder - ImageBind
- LLM - Vicuna
use a linear projection layer to connect the modality Q-Former with the LLM
two-stage training scheme
- The modality encoders and Vicuna model with be fixed throughout the training procedure
Stage 1: Single-modal Pre-training
- 与MiniGPT-4类似,第一阶段的作用是使linear projection layer的输出与LLM的词嵌入空间对齐
- 基于大量的modality-text paired data对modality Q-Former and linear projection layer进行训练
- For visual perception, we only train the projection layer for image captioning with the Q-Former from BLIP2 fixed
- For audio understanding, we jointly train the Q-Former and the projection layer for audio captioning
Stage 2: Multi-Modal Instruct Tuning
- 为了使模型适应输入模态的任意组合,作者设计了一个通用prompt

Instruction-Tuning Datasets
- Image-Text Dataset
We employ two previously published datasets for visual instruct tuning. The first one is released by MiniGPT-4, which contains 3,439 high-quality text-image pairs. The second one provided by LLaVA [6] is curated from 158K samples based on the COCO dataset, including three types of instructions, i.e., converstaions (58K), detailed description (23K) and complex reasnoning (77K)