BEVBert
BEVBert: Multimodal Map Pre-training for Language-guided Navigation
Motivation
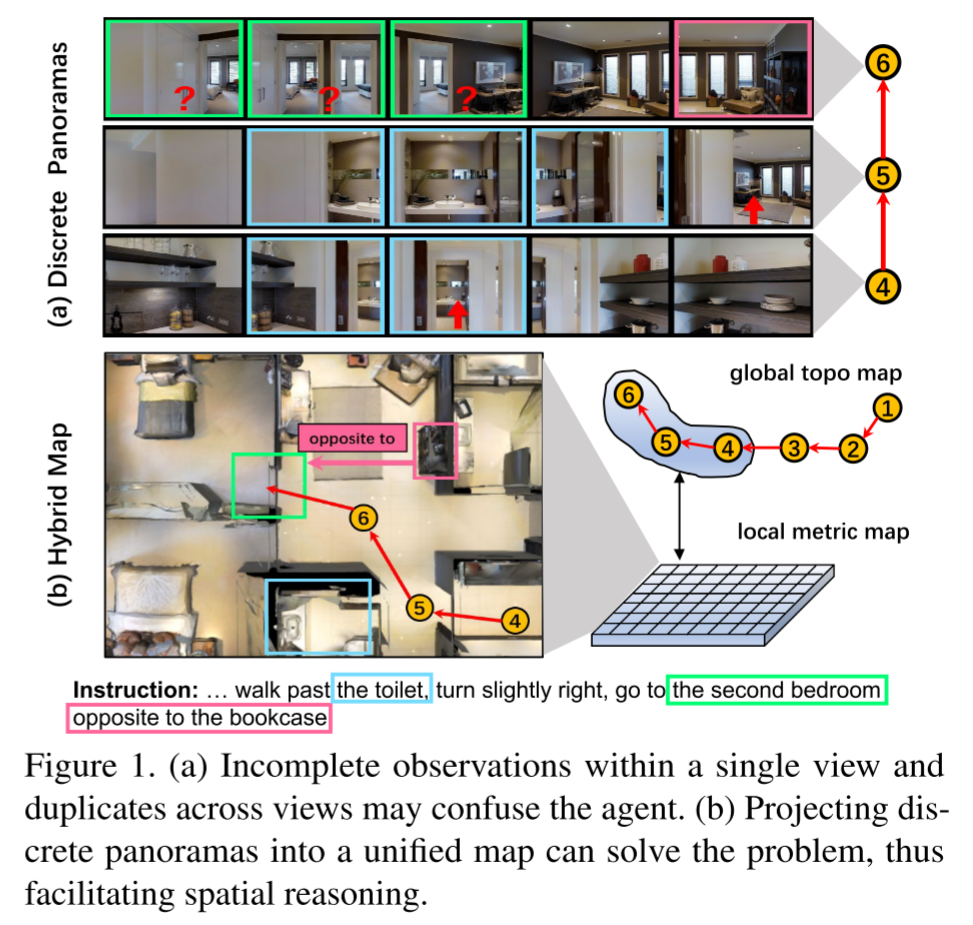
Most existing pre-training methods employ discrete panoramas to learn visual-textual associations. This requires the model to implicitly correlate incomplete, duplicate observations within the panoramas, which may impair an agent’s spatial understanding.
如下图所示,单个视图中不完整的观察和跨视图的重复观察可能会使agent感到困惑, discrete panoramas require implicit spatial modeling and may hamper the learning of generic language-environment correspondence
it is difficult to infer “the second bedroom opposite to the bookcase” because there are duplicate images of “bedroom” and “bookcase” across different views, and therefore it is hard to tell they are images for the same object or multiple instances.
一个潜在的解决方案是将这些观测值投影到一个统一的地图中,该地图明确地聚合不完整的观测值并删除重复的观测值, 这种方案与预训练的结合尚属空白,本文对此进行了首次探索
Metric map代表
[16] Object goal navigation using goal-oriented semantic exploration
缺点:存储和计算inefficiencies
The metric map uses dense grid features to precisely describe the environment but has inefficiencies of scale, As a result, using a large map to capture the long-horizon navigation dependency can cause prohibitive computation, especially for the computation-intensive pre-training
Topo map代表
[17] Neural topological slam for visual navigation
优点:
- the topo map can efficiently capture dependency by keeping track of visited locations as a graph structure
- It also allows the agent to make efficient long-term goal plans, such as backtracking to a previous location
缺点:压缩的特征表示缺少了局部的细粒度信息
- However, each node in the graph is typically represented by condensed feature vectors, which lack fine-grained information for local spatial reasoning
本文没有采用large global metric map,而是提出了一种混合方法,结合metric map和topo map。
local metric map for short-term spatial reasoning
conducting overall long-term action plans on a global topo map
Related Work
[15] Weakly-supervised multi-granularity map learning for vision-and-language navigation
Visual Representation in Vision-Language Pre-training
Image-based methods [51]提取图像的整体特征,但忽略了细节,因此在fine-grained language grounding上存在缺陷
Object-based methods [5, 52] represent an image with dozens of objects identified by external detectors. The challenge is that
objects can be redundant and limited in predefined categories.- Grid-based methods [55,56] directly use image grid features for pre-training, thus enabling multi-grained vision-language alignments
Most VLN pre-training are image-based [11, 12, 14], which rely on discrete panoramas. We introduce grid-based methods into VLN through metric maps, where the model can learn via multi-grained room layouts.
Methodology
Problem Definition
agent跟随指令穿过预定义的graph到达目标位置,每个时间步t都会得到离散的全景图(多个视角RGB images $\mathbf{V}_t$和depth images $\mathbf{D}_t$)及对应的位姿$\mathbf{P}_t$,
输入的观察表示为$\mathbf{O}_t=\{\mathbf{V}_t, \mathbf{D}_t, \mathbf{P}_t\}$
输出的动作实际上是从simulator提供的candidate set中选择一个可导航节点
$\mathbf{G}^*$代表predefined graph
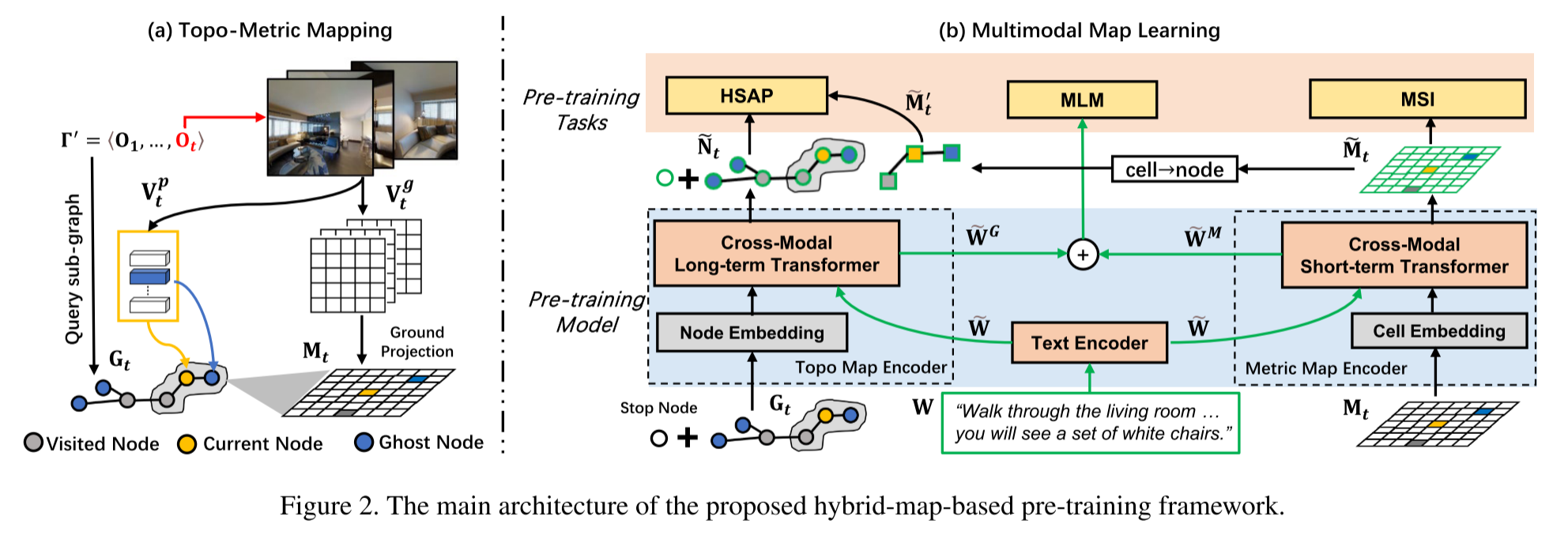
Topo-Metric Mapping
Image Processing
使用预训练的vit对RGB输入$\mathbf{V}_t$进行特征提取,得到特征向量$\mathbf{V}_t^p$和downsized grid features $\mathbf{V}_t^g$,对应的深度图像$\mathbf{D}_t$也被downsize到与downsized grid features一样的尺寸,得到$\mathbf{D}_t^{\prime}$
Topo Mapping
设agent走过的路径为$\Gamma^{\prime}$, 时间步为t, graph-based topo map $\mathbf{G}_t=\{\mathbf{N}_t,\mathbf{E}_t\}$保存路径$\Gamma^{\prime}$上观察到的所有节点
‘ghost’ denotes navigable nodes observed along the path $\Gamma^{\prime}$ but have not been explored
$\mathbf{E}_t$存储了两个相邻节点间的欧氏距离
- 将图像特征向量$\mathbf{V}_*^p$投影到节点上,作为visual representations
- $\mathbf{V}_t^p$被送入pano encoder(两层的transformer)来获取contextual view embeddings$\mathbf{\hat{V}}_t^p$
- 对于已经访问过的节点(visited nodes & current nodes),全景图是可以获取的,因此这些节点的特征则用全景视图的特征的平均来表示
- Ghost Node可以被部分的观察到,因此其特征可以由观察到这一节点的视图的embedding之和来表示
$\mathbf{G}_t$包含了所有已观察到的节点,在此基础上可以获得一个用于long-term planning的全局动作空间$\mathcal{A}^G$
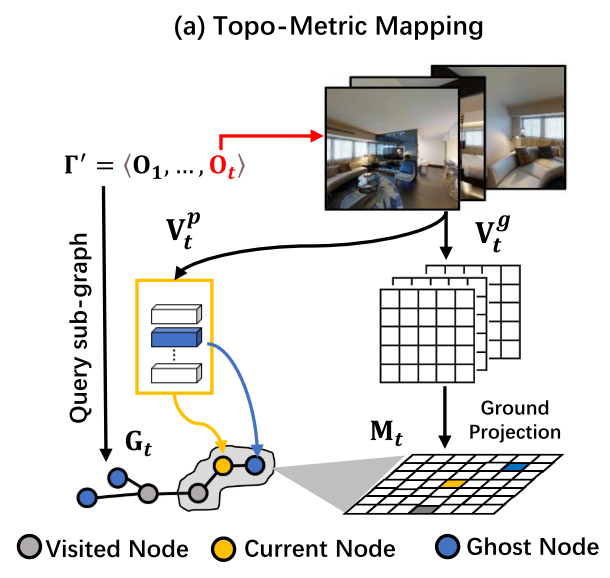
Metric Mapping
我们将grid-based metric map $\mathbf{M}_t \in \mathcal{R}^{U\times V\times D}$定义为一个egocentric map,其中每个单元格包含一个D-sized latent feature representing a small region of the surrounding layouts,使用nearby visited nodes对当前节点的观察的特征投影到ground plane,并进行平均池化
在$\mathbf{M}_t$基础上可以获得一个用于short-term reasoning的局部动作空间$\mathcal{A}^M$
Pre-training Model
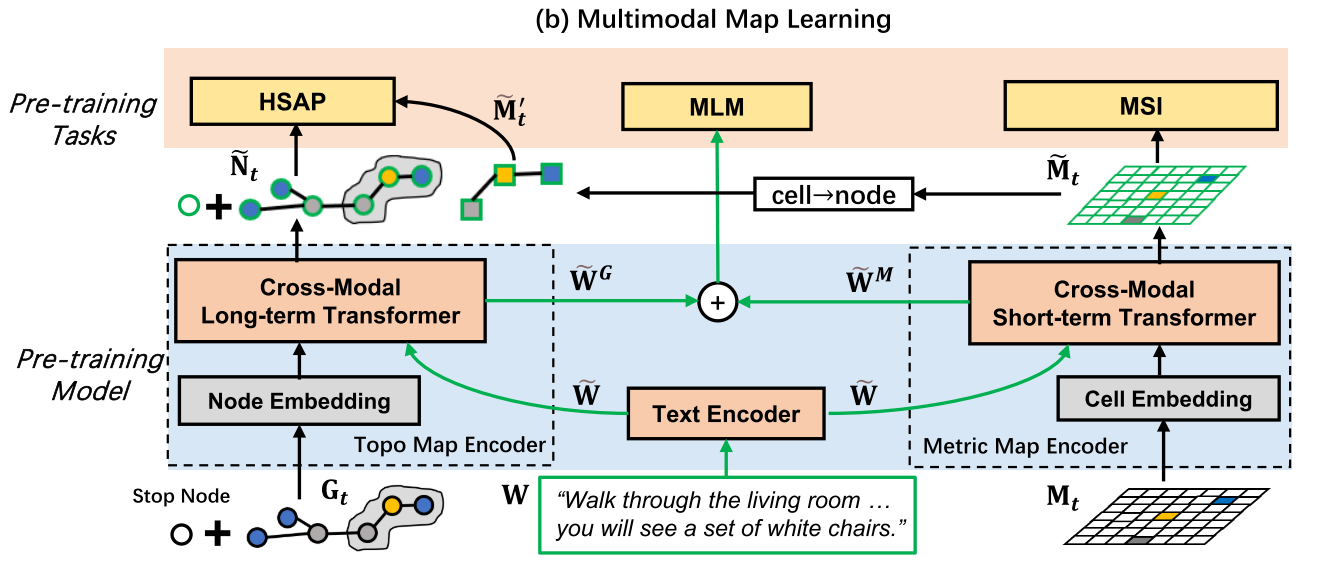
Pre-training Tasks
- Masked Language Modeling (MLM)
- Hybrid Single Action Prediction (HSAP): 结合$\mathcal{A}^M$和$\mathcal{A}^G$进行预测
- Masked Semantic Imagination (MSI):there are some unobserved areas on the metric map $\mathbf{M}_t$, which brings uncertainty for decision-making.因此提出MSI,通过对指令的推理和部分观察到的区域来帮助agent想象未观察到的区域
- 擦除一部分metric maps
- 每个格子内可能有多个类别,因此建模为多标签分类问题,使用二元交叉熵损失进行优化(定义了40个语义类别,obtain these labels from Matterport3D dataset)
Experiment
R2R, R2R-CE, and RxR focus on fine-grained instruction following, whereas R2R-CE is a variant of R2R in continuous environments and RxR provides more detailed path descriptions (e.g., objects and their relations). REVERIE is a goal-oriented task using coarse-grained instructions, such as “Go to the entryway and clean the coffee table”.
Navigation Metrics
- Trajectory Length (TL): average pathlength in meters;
- Navigation Error (NE): average distance in meters between the final and target location;
- Success Rate(SR): the ratio of paths with NE less than 3 meters;
- Oracle SR (OSR): SR given oracle stop policy;
- SR penalized by Path Length (SPL);
- Normalize Dynamic Time Wrapping (NDTW): the fidelity between the predicted and annotated paths and NDTW penalized by SR (SDTW).
Object Grounding Metrics to evaluate the capacity of object grounding
Remote Grounding Success (RGS)
RGSPL (RGS penalized by Path Length)
All metrics are the higher the better, except for TL and NE.
4.1. Implementation Details
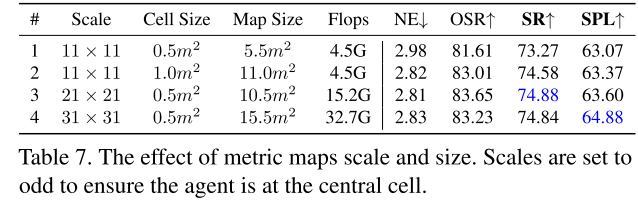
- set the metric map scale as 21 × 21, and each cell represents a square region with a side length of 0.5m (the entire map is thus 10.5m× 10.5m).
- Training: 4 NVIDIA Tesla A100 GPUs (∼10 hours)
- Finetuning: 4 NVIDIA Tesla A100 GPUs (∼20 hours)
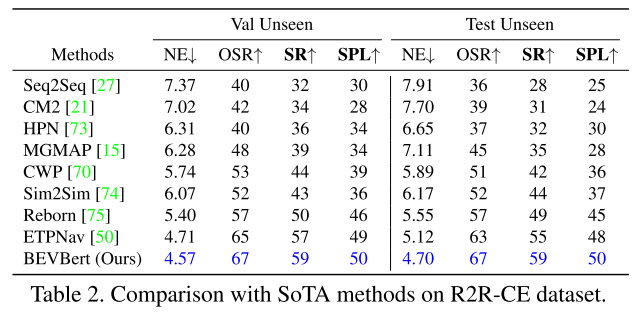
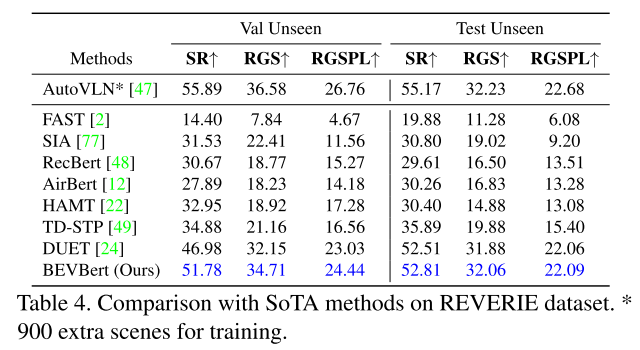
4.2 Comparison with State-of-the-Art
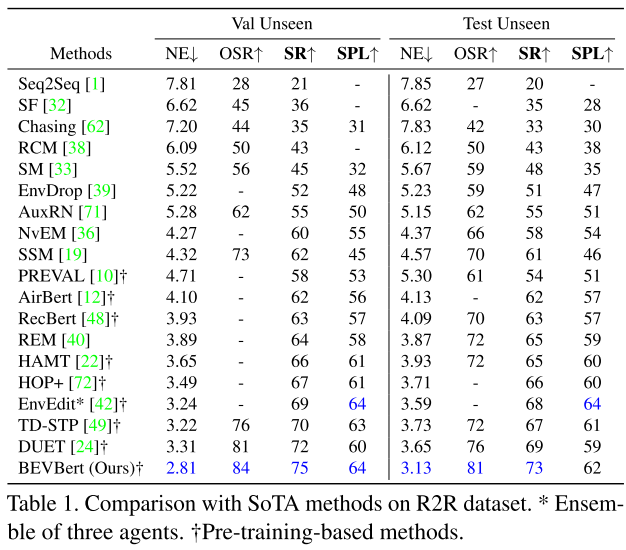
[50] Etpnav: Evolving topological planning for vision-language navigation in continuous environments
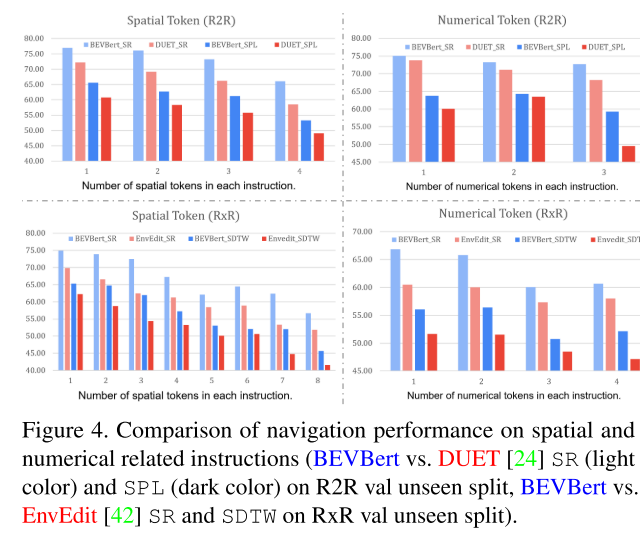
测试空间推理能力的定量实验
from R2R and RxR val unseen splits, we first extract the relevant instructions which contain either spatial tokens (e.g. “left of”, “rightmost”) or numerical tokens (e.g. “second”, “fourth”). An agent’s reasoning capability can be inferred from how well it follows these instructions
As the number of special tokens in each instruction increases, the performance of all models shows downward trends. This indicates spatial reasoning is a bottleneck of existing methods