USA-Net
USA-Net: Unified Semantic and Affordance Representations for Robot Memory
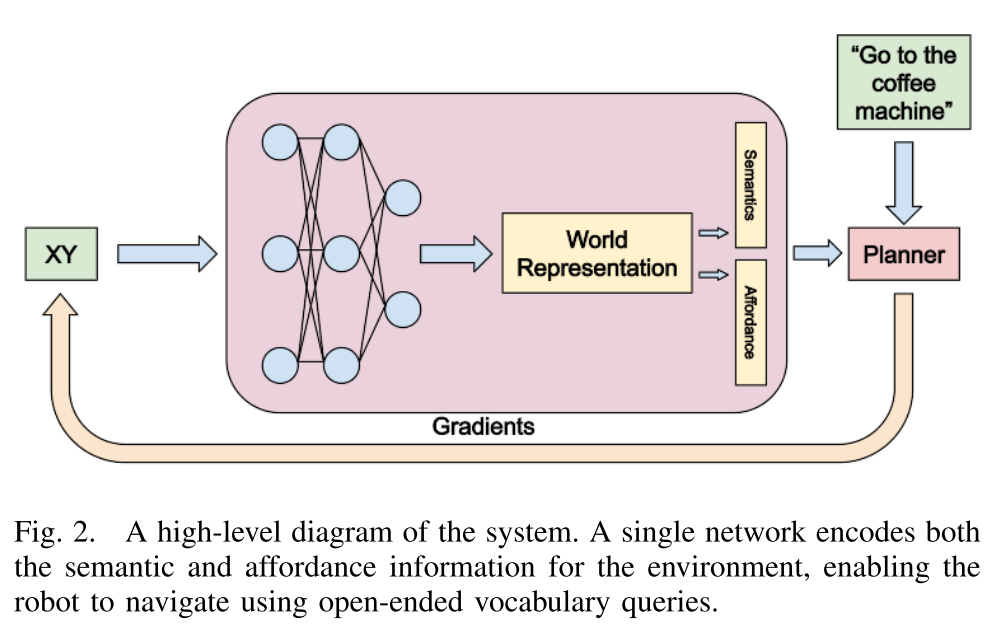
the first end-to-end differentiable planner optimizes for both semantics and affordance in a single implicit map
“take this can to the kitchen”, 机器人想要完成这样一个指令,需要两方面信息:
- semantic information:需要知道厨房的位置
- affordance information:进行轨迹规划,避免和场景中的其他物体碰撞
Motivation
Semantic information can then be used to find the location of objects for planning, 但没有考虑应该采取什么样的轨迹才能在不与障碍物相撞的情况下到达目标
in the case of a learned representation, we instead see a softer distribution of potential goals, where there may be tradeoff between trajectory planning and goal selection
基于学习到的表征来推断目标位置往往不能获得确切位置,而是一些潜在可能的目标位置,最佳语义位置可能被障碍物阻挡或以其他方式不可达,因此需要权衡可达性和目标选择
course-grained discrete motion planners, such as occupancy grids which use large cell sizes to conserve memory,可能无法捕获细粒度语义信息,诸如场景的小细节。
要执行命令“从冰箱里拿一杯苏打水”,机器人必须能够在环境中的粗粒度障碍物周围导航,而且还能与相对细粒度的苏打水罐进行交互。
How can we use RGB and depth data to capture a representation which can be used for both semantic goal navigation and motion planning?
Related Work
显式建图
[3] A persistent spatial semantic representation for high-level natural language instruction execution. In Conference on Robot Learning, pages 706–717. PMLR, 2022.
在occupancy map中寻找最优路径:
A* search algorithm [11]
RRT*[17]
fast-matching trees (FMT*) [15]
- batch informedtrees (BIT* ) [9]
- adaptively informed trees (AIT* ) [33]
- effort informed trees (EIT*) [34]
[25] isdf: Real-time neural signed distance fields for robot perception
Methodology
Experiments
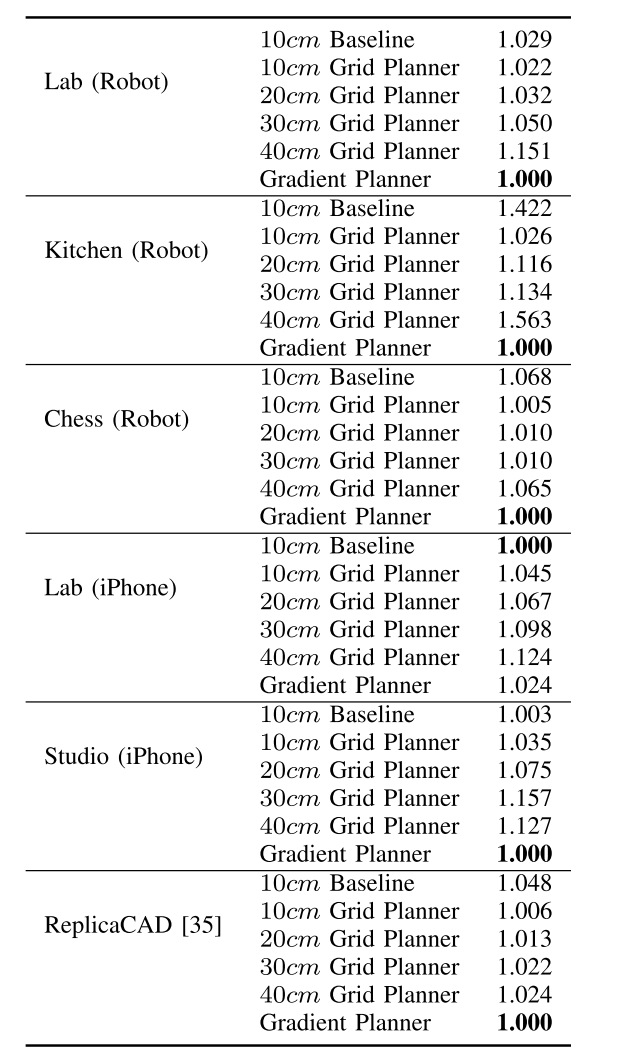
在随机选择的100个起点和终点对之间的最短路径上的平均长度倍数。较低的值表示较短的平均路径长度。值为1表示给定规划器的路径长度比给定场景的所有其他规划器的路径长度更好。
occupancy map的分辨率越高,grid planner的效果越好,其实差距并不是非常大?