ICRA2023 VLMaps
Visual Language Maps for Robot Navigation
Motivation
Without grounding language onto a spatial representation, these systems may struggle to:
- recognize correspondences that associate independent observations of the same object
- localize spatial goals e.g., “in between the sofa and the TV”
- build persistent representations that can be shared across different embodiments, e.g., mobile robots, drones
两大卖点
对语言和空间的感知理解能力:Localize spatial goals beyond object-centric ones, e.g., “in between the TV and sofa” or “to the right of the chair” or “kitchen area” using code-writing LLMs, expanding beyond capabilities of CoW or LM-Nav.
多智能体协作,不同的robots对应不同的obstacle maps: can be shared among multiple robots with different embodiments to generate new obstacle maps on-the-fly (by using a list of obstacle categories)
Generate new obstacle maps for new embodiments given natural language descriptions of landmark categories that they can or cannot traverse, e.g., “tables” are obstacles for a large mobile robot, but traversable for a drone.
both LM-Nav [13] and CoW [12] are limited to navigating to object landmarks and are less capable to understand finer-grained queries, such as “to the left of the chair” and “in between the TV and the sofa”
Methodology
构建一个spatial visual-language map representation,根据自然语言定位出landmarks(“the sofa”)或spatial references(“between the sofa and the TV”)
Building a Visual-Language Map
how to build a VLMap?
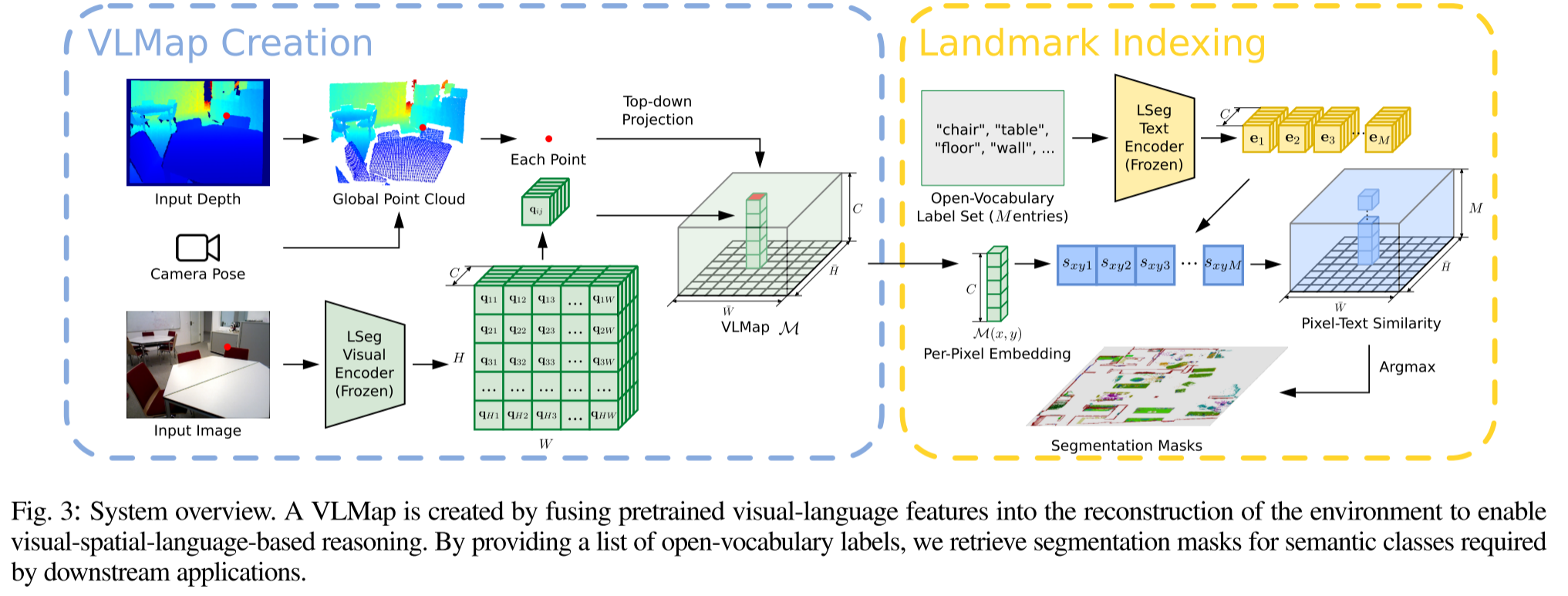
fuse pretrained visual-language features with a 3D reconstruction
将VLMaps表示为$\mathcal{M}∈\mathbb{R}^{\bar{H}\times \bar{W} \times C}$,其中$\bar{H}$和$\bar{W}$代表了top-down视角的grid map尺寸,$C$则代表了每个网格单元对应的特征向量维度。
对于每个RGB-D frame,将所有的像素$\mathbf{u}=(u,v)$全部back-project到local depth point cloud(world frame):
- $\mathbf{P}_k=D(\mathbf{u})K^{-1}\mathbf{\tilde{u}}$
- $\mathbf{P}_W=T_{Wk}P_k$
- 其中$\mathbf{\tilde{u}}=(u,v,1)$, $K$代表深度相机的本质矩阵,$D(\mathbf{u})\in \mathbb{R}$是像素$\mathbf{u}$的深度值,$T_{Wk}$代表从world coordinate frame to the k-th camera frame的空间变换,$\mathbf{P}_k \in \mathbb{R}^3$代表3D point的在k-th frame中的位置,$\mathbf{P}_W \in \mathbb{R}^3$是3D point在world coordinate frame中的位置,上述两个式子的作用是将像素投影到3D的世界坐标系。
然后将$\mathbf{P}_W$投影到地平面上,获得像素$\mathbf{u}$在grid map中对应的位置
- $p_{\text {map }}^{x}=\left\lfloor\frac{\bar{H}}{2}+\frac{P_{W}^{x}}{s}+0.5\right\rfloor, p_{m a p}^{y}=\left\lfloor\frac{\bar{W}}{2}-\frac{P_{W}^{z}}{s}+0.5\right\rfloor$
- 在建立grid map后,使用LSeg来对RGB image $\mathcal{I}_k$进行编码,并转换到grip map上:
- $f(\mathcal{I}):\mathbb{R}^{H\times W\times 3} \rightarrow \mathcal{F}_k \in\mathbb{R}^{H\times W\times C}$
- 将image pixel $\mathbf{u}$的特征$\mathbf{q}=\mathcal{F}_k(\mathbf{u}) \in \mathbb{R}^C$投影到对应的grid cell location
- 多个3D点都会被投影到同一个grid cell中,作者直接将投影到同一位置的特征进行平均
- the resulting features contain the averaged embeddings from multiple views of the same object
Localizing Open-Vocabulary Landmarks
how to use these maps to localize open-vocabulary landmarks?
- 将input language list定义为$\mathcal{L}=[\mathbf{l}_0,\mathbf{l}_1,…,\mathbf{l}_M]$
- 其中$\mathbf{l_i}$代表i-th category的文本表示
- $M$代表用户定义的类别数量
- 使用CLIP text encoder将文本类别列表转换为特征向量矩阵$E \in \mathbb{R}^{M\times C}$, 每一行代表一个类别的特征向量
- 将grid map $\mathcal{M}∈\mathbb{R}^{\bar{H}\times \bar{W} \times C}$打平变为$Q \in \mathbb{R}^{\bar{H}\bar{W} \times C}$, 每行代表top-down grid map中一个pixel的特征
- 然后计算grid map pixel-to-category similarity matrix $S=Q\cdot E^T$,$S \in \mathbb{R}^{\bar{H}\bar{W} \times M}$
- 然后argmax操作获得grid map上的语义分割结果
Generating Open-Vocabulary Obstacle Maps
how to build open-vocabulary obstacle maps from a list of obstacle categories for different robot embodiments
通过自然语言来对障碍物类别进行描述(定义一个障碍物类型列表),然后在运行时定位障碍物以生成用于碰撞避免和最短路径规划的二进制地图。
一个典型的使用场景是多个不同的机器人共享相同环境的VLMap,大型移动的机器人可能需要在桌子(或其他大型家具)周围导航,而无人机可以直接在其上方飞行。通过简单地提供两个不同的障碍物类别列表,可以从VLMap中生成两个不同的障碍物地图供两个机器人分别使用,一个用于大型移动的机器人(包含“桌子”),另一个用于无人机(不包含“桌子”)
障碍物地图$\mathcal{O}\in \{0,1\}^{\bar{H}\times \bar{W}}$的获取:
没有障碍物的位置置1,floor和ceiling通过限制高度来去掉
$\mathcal{O}_{i j}=\left\{\begin{array}{ll}
1, & t_{1} \leq P_{W}^{y} \leq t_{2} \text { and } p_{\text {map }}^{x}=i \text { and } p_{\text {map }}^{y}=j \\
0, & \text { otherwise }
\end{array}\right.$定义障碍物类型列表,并按照定位landmark的方法得到障碍物语义分割图
对于不同的机器人选择不同的障碍物子集
Zero-Shot Spatial Goal Navigation from Language
how VLMaps can be used together with large language models (LLMs) for zero-shot spatial goal navigation on real robots from natural language commands?
long-horizon (spatial) goal navigation:
使用自然语言给出一组landmark descriptions
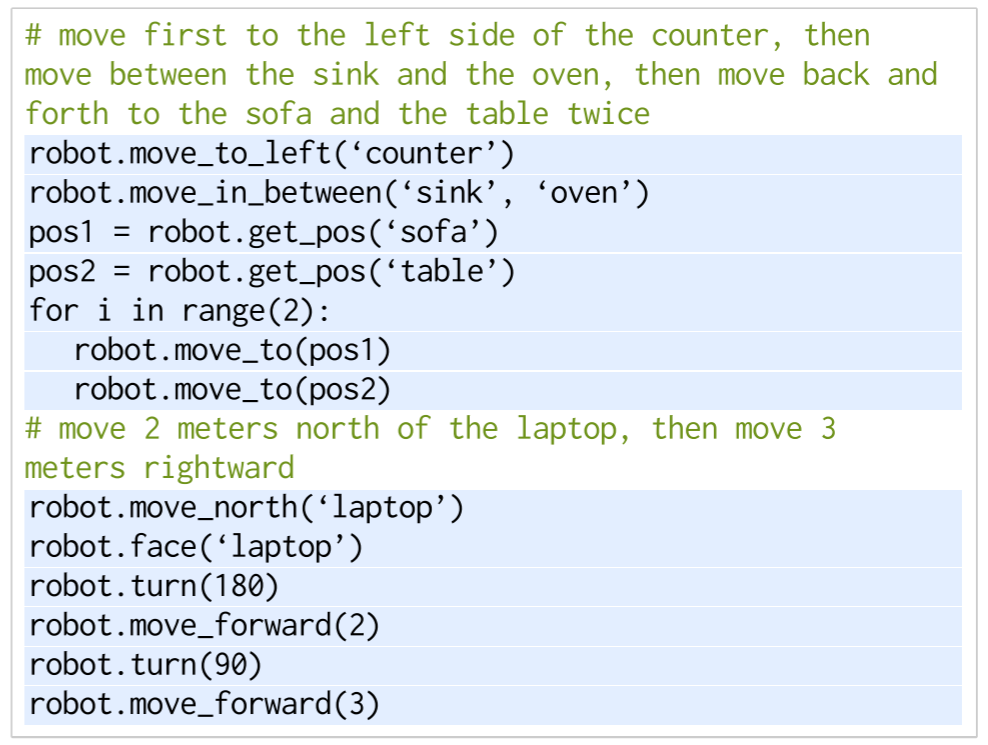
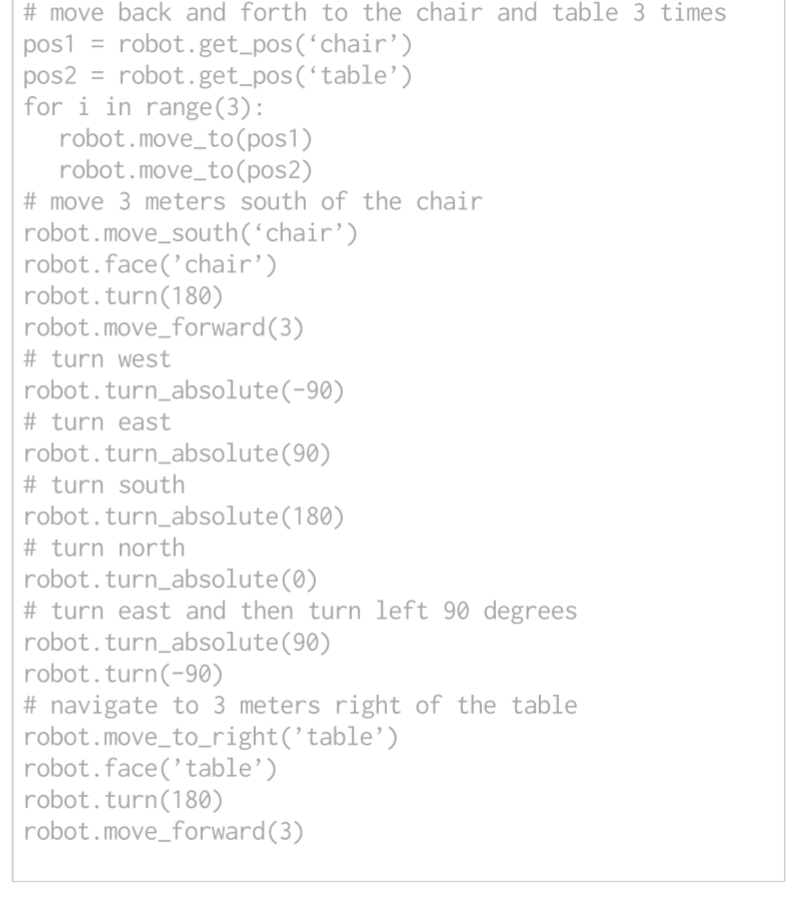
move first to the left side of the counter, then
move between the sink and the oven, then move back
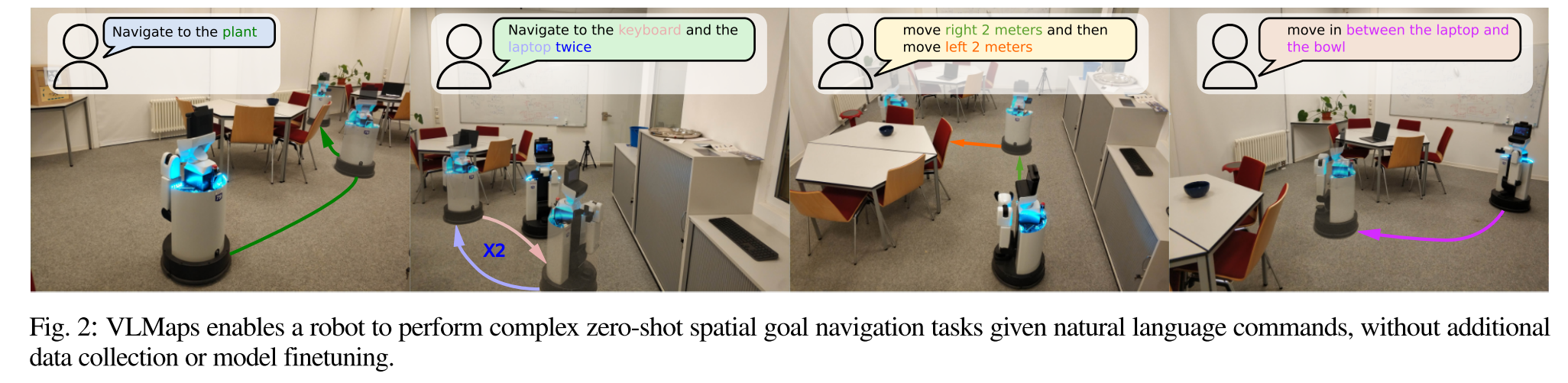
and forth to the sofa and the table twiceVLMaps可以指示精确的空间目标,例如:“在电视机前的沙发中间”或“椅子东边三米处”
- 利用LLM的代码编写能力来生成可执行的Python机器人代码,这些代码可以
- 对参数化的导航原子操作进行精确调用
- 在需要时执行算术
- 生成的代码可以直接在内置Python exec函数的机器人上执行
[43] Code as policies: Language model programs for embodied control 2022
[33] Grounding language with visual affordances over unstructured data 2022
Codex[44] Evaluating large language models trained on code 2021
本文使用code-writing language models来完成mobile robot planning
使用few-shot prompting的方式,提供几个注释和代码配对的例子
The robot code can express functions or logic structures (if-then-else statements or for/while loops) and parameterize API calls (e.g., robot.move_to(target_name) or robot.turn(degrees).
At test time, the models can subsequently take in new commands and autonomously re-compose API calls to generate new robot code respectively
prompt in gray, input task commands in green, and generated outputs are highlighted

- 语言模型可以通过生成的代码调用导航原子操作函数,使用VLMap来定位open-vocabulary landmarks在地图中的位置
- We then navigate to these coordinates using an off-the-shelf navigation stack that takes as input the embodiment-specific obstacle map
- input:目标位置,障碍物地图
Experiment
Simulation Setup
- We use the Habitat simulator with the Matterport3D dataset for the evaluation of multi-object and spatial goal navigation tasks.
- To evaluate the creation of open-vocabulary multi-embodiment obstacle maps, we adopt the AI2THOR simulator due to its support of multiple agent types, such as LoCoBot and drone
- navigate in a continuous environment with actions: move forward 0.05 meters, turn left 1 degree, turn right 1 degree and stop.
- 为了创建Habitat的map,作者收集了10个不同场景的12096 RGB-D frames和对应的相机位姿
- 为了创建AI2THOR的map,作者收集了10个不同房间的1826 RGB-D frames和对应相机位姿
- 实验对比的3个baseline
- LM-Nav
- CLIP on Wheels(CoW)
- CLIP-features-based map(CLIP Map)
Multi-object goal navigation
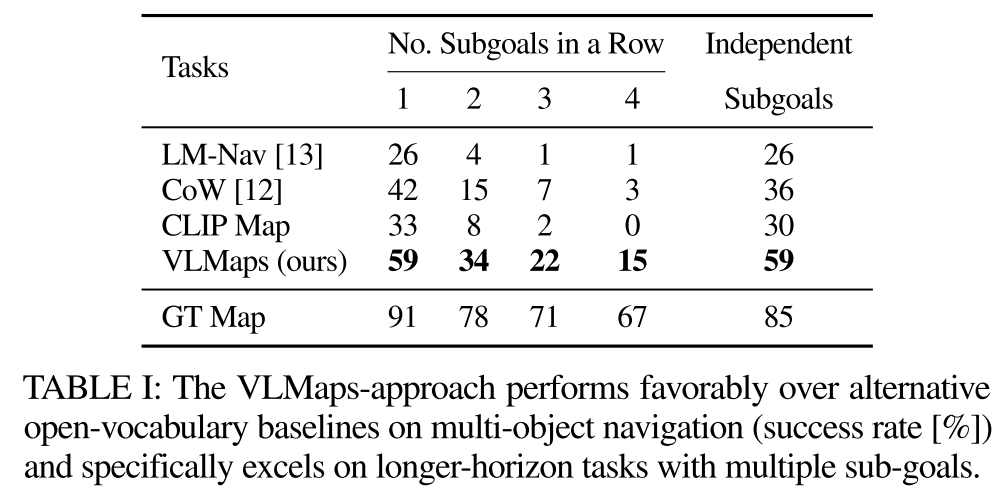
quantitatively evaluate VLMaps approach against recent open-vocabulary navigation baselines on the standard task of multi-object goal navigation
作者收集了91个任务序列来评估object navigation
在每个序列中,随机指定机器人在场景中的起始位置,然后从30个对象类别中选择4个作为子目标对象类型。机器人需要按顺序导航到这四个子目标。当robot到达subgoal时,应该调用stop action来指示进度。当停止位置与正确目标的距离在一米以内时,认为成功导航到了一个子目标
To evaluatethe long-horizon navigation capabilities of the agents, we compute the success rate (SR) of continuously reaching one to four subgoals in a sequence,SR=所有subgoals成功数/total subgoals number(364=91*4)
To obtain more insights into the map-based methods, we visualize the object masks generated by VLMaps, CoW, and CLIP Map, in comparison to GT, in Fig. 4. The masks generated by CoW (Fig. 4d) and CLIP (Fig. 4c) both contain considerable false positive predictions.
Since the planning generates the path to the nearest masked target area, these predictions lead to planning towards wrong goals.

Zero-Shot Spatial Goal Navigation from Language
investigate whether our method can better navigate to spatial goals specified by language commands versus alternative approaches
benchmark由7个场景中的21个trajectories组成, 并手动指定相应的语言指令进行评估, 每个轨迹包含四个不同的空间位置作为子目标。子目标的示例如“east of the table”、“in between the chair and the sofa”或“move forward 3 meters”。也有指令要求机器人重新调整自己,找附近的物体,如“with the counter on your right”。
对于所有基于地图的方法,包括CoW,CLIP Map,ground truth semantic map和VLMaps,应用LLM代码生成技术来实现导航

Cross-Embodiment Navigation
study whether VLMaps with their capacity to specify open-vocabulary obstacle maps can provide utility in improving the navigation efficiency of different robots with different embodiments
- AI2THOR simulator
- LoCoBot and drone
- Success Rate (SR) and the Success rate weighted by the (normalized inverse) Path Length (SPL)
Real Robot Experiments
to demonstrate on real robots that VLMaps can enable zero-shot spatial goal navigation given unseen language instructions
Detail
- 导航的原子操作

完整的prompt

Discussion and Limitation
- 仍然对3D重建噪声和odometry drift(里程计漂移)敏感
- 无法解决当相似物体聚集在一起时产生的对象歧义
- 动态物体