ConceptFusion
https://concept-fusion.github.io/

Motivation
建立环境的3D map是许多机器人任务的核心,大部分方法建图时都受限于:
- Closed-set setting,仅能处理训练时预定好的类别
只能由class name或text prompt进行查询(单模态)
ConceptFusion的三个贡献:
open-set multimodal 3D mapping that constructs map representations queryable by text, image, audio, and click queries in a zero-shot manner
- A novel mechanism to compute pixel-aligned (local) features from foundation models that can only generate image-level (global) feature vectors
- A new RGB-D dataset, UnCoCo, to evaluate open-set multimodal 3D mapping. UnCoCo comprises 78 common household/office objects tagged with more than 500K queries across modalities
Related Work
CLIP将图像整体和文本对齐
LSeg, OpenSeg, OVSeg等工作则是通过训练或微调来实现更精细的区域-文本对齐,可能导致不常见类的遗忘
MaskCLIP为了保留CLIP的知识,提出了zero-shot的方式,但在对象边界和长尾概念上表现不佳
VLMaps[44] Visual language maps for robot navigation. ICRA 2023
LM-Nav[45] Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action. In CoRR, 2022
CoWs[46] Clip on wheels: Zero-shot object navigation as object localization and exploration. 2022
NLMap-Saycan[47] Open-vocabulary queryable scene representations for real world planning. 2022
OpenScene[48] Open-scene: 3d scene understanding with open vocabularies. 2022
[49] Language-driven open-vocabulary 3d scene understanding.
[50] Feature-realistic neural fusion for real-time, open set scene understanding
[51] Semantic abstraction: Open-world 3D scene understanding from 2D vision-language models. In Proceedings of the 2022 Conference on Robot Learning, 2022.
Methodology
Fusing pixel-aligned foundation features to 3D
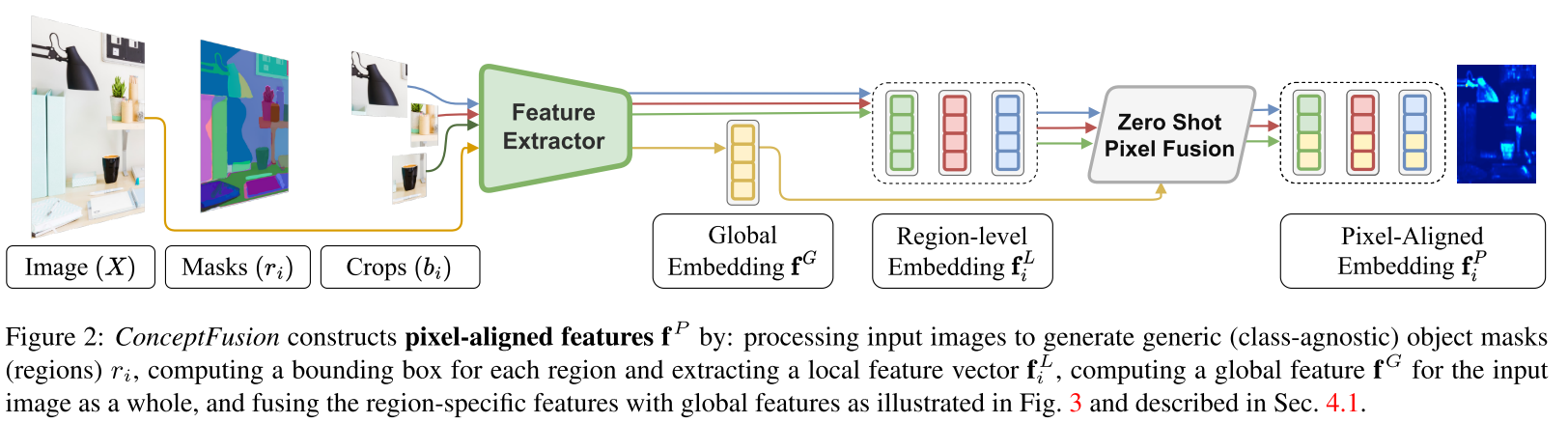
Map representation
使用点云来表示3D map,每个点的属性包括:
- vertex position
- normal vector
- confidence count
- 3D color vector
- concept vector
Frame preprocessing
在获得一帧RGB-D输入后,首先计算vertex-normal maps并估计相机位姿,然后为每个像素点都计算semantic context embedding。
Feature fusion
