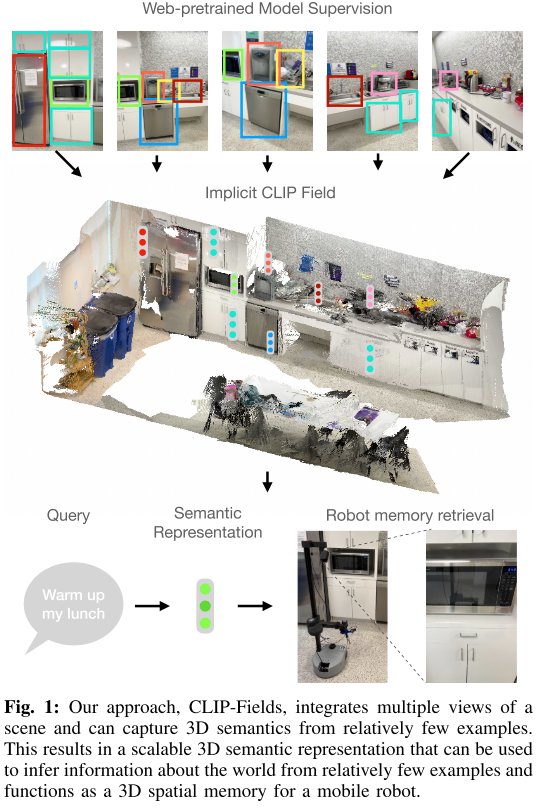
CLIP-Fields
CLIP-Fields: Weakly Supervised Semantic Fields for Robotic Memory
- CLIP-Fields提出了隐式的场景表示,可以用于segmentation, instance identification, semantic search over space, and view localization
- 使用CLIP, Detic, and Sentence-BERT来提供弱监督来建立semantic neural fields,不需要直接的人工标注监督
- 更好的few-shot性能
- 使用CLIP-Fields作为scene memory可以使机器人在真实世界实现语义导航
Related Work
[3]Seal: Self-supervised embodied active learning using exploration and 3d consistency.中作者发现web-trained detection model结合空间一致性启发式方法可用于标注3D voxel map,voxel map可以用于将标签从一个图像传播到另一个图像。
[12]Semantic abstraction: Open-world 3d scene understanding from 2d vision-language models
Sentence-BERT [23]:
CLIP models are pretrained with image-text pairs, but not with image-image or text-text pairs. As a result, sometimes CLIP embeddings can be ambiguous when comparing similarities between two images or pieces of texts
pretrained for semantic-similarity tasks
Instant-NGP [20]
Methodology
Problem Statement
CLIP-Fields to provide an interface with a pair of scene-dependent implicit functions $f, h$:$\mathbb{R}^{3} \rightarrow \mathbb{R}^{n}$
- $f(P)$是代表P点semantic features的特征向量,与pre-trained language特征空间对齐
- $h(P)$是代表P点visual features的特征向量,与pre-trained vision-language models特征空间对齐
For ease of decoding, we constrain the output spaces of $f, h$ to match the embedding space of pre-trained language and vision-language models, respectively
“spatial memory” or “geometric database”都指的是f,h这两个函数,联系了场景坐标和场景信息
如果我们给定一个数据集$\{(P, f(P), h(P) | P ∈ scene\}$,那么场景相关函数$f,h$将很容易构造
有了函数$f,h$,就很容易实现下游任务:
- Segmentation: $f$
- Object Navigation: $f$ or $h$
- View Localization: $h$
Dataset Creation
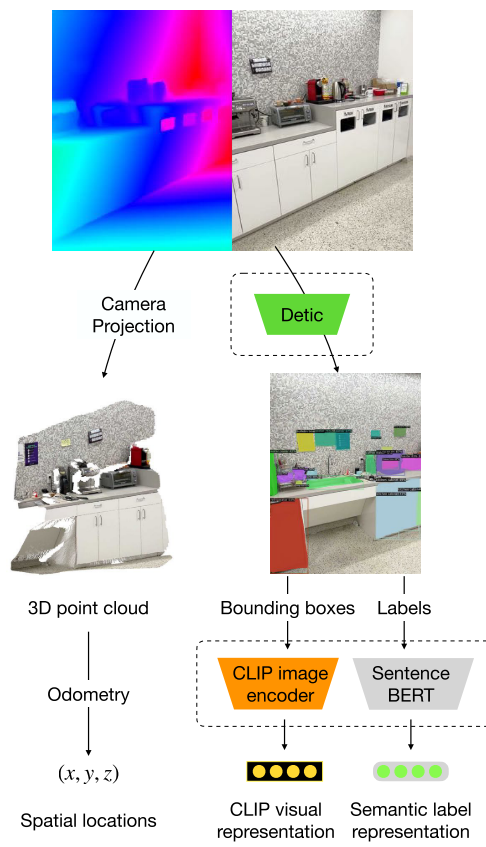
对于场景的数据:We assume that we have a series of RGB-D images of a scene alongside odometry information, i.e. the approximate 6D camera poses while capturing the images.
作者使用易于获取的设备(如iPhone Pro或iPad)来获取数据集
Dataset creation process
(左边分支)利用RGB-D和相机内参外参,将深度图像转换为3D point cloud(每个点的坐标都用世界坐标系表示)
右边分支:
使用Detic对RGB图像进行Open-vocabulary object detection,然后得到一系列的对象对应的:language labels,label masks和confidence scores
然后将像素的标签和置信度back-project到世界坐标点上,We label each back-projected point in the world with the associated language label and label confidence score.
另外,将反投影后的世界坐标系点对应的RGB view的CLIP特征以及点和相机之间的距离作为这个点的label
Additionally, we label each back-projected point with the CLIP embedding of the view it was back-projected from as well as the distance between camera and the point in that particular point
Note that each point can appear multiple times in the dataset from different training images
到此获得了两组labels,分别来自
- Detic(language labels,label masks和confidence scores),表示为$D_{label}=\{(P,label_P,conf_P)\}$, $label_P,conf_P$分别代表detector-given label and the confidence score to such label for each point
- CLIP(CLIP特征以及点和相机之间的距离), 表示为$D_{image} = \{(P, clip_P, dist_P)\}$, $clip_P$代表$P$点对应的反投影前的图像CLIP特征(?还是对应Detic检测出来的区域CLIP特征?),$dist_P$代表在拍摄当前image时的相机和$P$点的距离
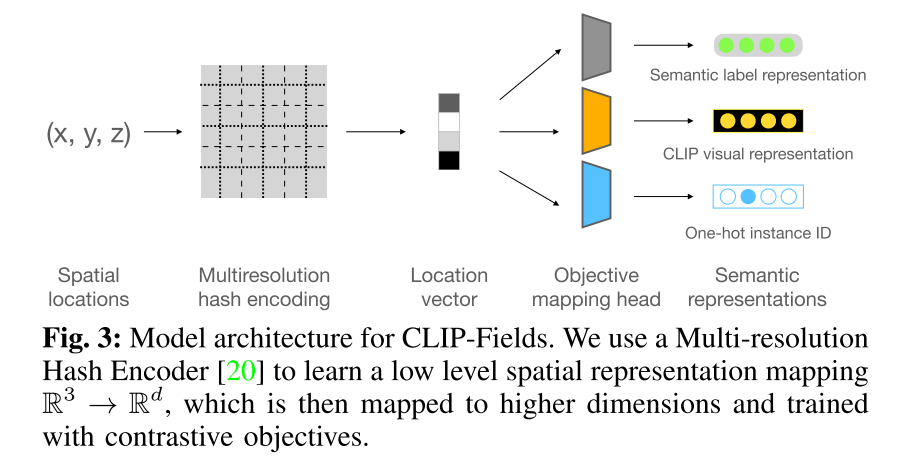
Model Architecture
CLIP-Fields可以划分为两个部分:
- g: $\mathbb{R}^{3} \rightarrow \mathbb{R}^{n}$, 将每个空间位置$(x,y,z)$映射到一个特征向量(Location vector),本文使用Instant-NGP中引入的multi-resolution hash encoding (MHE)方法来参数化表示$g$这一映射,$d=144$
- MHEs build an implicit representation over coordinates with a feature-pyramid like structure, which can flexibly maintain both local and global information, unlike purely voxel-based encodings which focuses on local structures only.
- We primarily use the MHE over other implicit field representations because we found that they train significantly faster in our datasets.
- individual heads(即下图中的Objective mapping head)
- simple two-layer MLPs with ReLU nonlinearities
- map the 144 dimensional outputs of g into higher dimensions which depend on the associated objective
- $head_s$: outputs a vector that matches a natural language description of what is at the point in space
- $head_v$ :outputs a vector that matches the visual appearance
- Optionally, we can include an instance identification head if we have the appropriate labels to train it.
Objectives
对于特定的一个场景,使用对比损失对CLIP-Fields进行训练
使用label confidence对语义预测的对比损失进行加权(对于semantic label,如SentenceBERT 的label embeddings)
- 使用从相机到点的距离的负指数对来自CLIP embedding的visual label产生的对比损失进行加权
- 通过学习的温度值来缩放predicted embeddings和GT embeddings的点积
Semantic Label Embedding
- 首先使用可以用于比较语义相似性的预训练语言模型将每个标签转换为语义向量,例如CLIP的text encoder或Sentence-BERT
- 本文使用Sentence-BERT for these language features with $n = 768$
- semantic label loss:
- $\mathrm{L}_{\mathcal{L}}(P, f(P))=-\mathrm{c} \log \frac{\exp \left(f(P)^{T} \mathcal{F}\left(\text { label }_{P}\right) / \tau\right)}{\sum_{P^{-}} \exp \left(f(P)^{T} \mathcal{F}\left(\text { label }_{P^{-}}\right) / \tau\right)}$
- $P^-$代表具有与$P$点不同语义标签的点,$f$代表semantic encoding function(就是$head_s \circ g$),$\mathcal{F}$代表pre-trained semantic language encoder, $c$代表confidence,$\tau$代表温度
Visual Feature Embedding
将每个点的视觉特征表示为这个点出现在的RGB frame对应的CLIP embedding的加权组合,权值为点到相机的距离
We define the visual context of each point as a composite of the CLIP embedding of each RGB frame this point was included in, weighted by the distance from camera to the point in that frame.
we limit the image embedding to only encode what is in the associated object’s bounding box. Detic, for example, produces embeddings for region proposals for each detected objects, which we use.
In this paper’s experiments, we use the CLIP ViT-B/32 model embeddings, giving the visual features 512 dimensions.
$\mathrm{L}_{\mathrm{C}}(P, h(P))=-e^{-d_{P}} \log \frac{\exp \left(h(P)^{T} \mathrm{C}_{P} / \tau\right)}{\sum_{P^{-}} \exp \left(h(P)^{T} \mathrm{C}_{P^{-}} / \tau\right)}$
Auxilary objectives like Instance Identification
- 将点的表征投影到one-hot向量以表示instance
- 仅在具有human labeled instance identification data时使用,the projection dimension is number of identified instances, plus one for unidentified instances.
- Instance identification one-hot vectors are trained with a simple cross-entropy loss
Training
正负样本的定义:
- For the label embedding head
- the positive example is the semantic embedding of the label associated with that point
- negative examples are semantic embeddings of any other labels.
- For the visual context embedding head
- the positive examples are the embeddings of all images and image patches that contain the point under consideration
- the negative examples are embeddings of images that do not contain that point.
对比学习训练
- we also note that a larger batch size helps reduce the variance in the contrastive loss function:
- We use a batch size of 12, 544 everywhere since that is the maximum batch size we could fit in our VRAM of an NVIDIA Quadro GP100 GPU
Discussion
A new CLIP-Field is trained per scene
It remains to be explored whether learned CLIP-Fields could potentially generalize to new scenes, or to changes within a scene