Natural-Language Map (NLMap)
Open-vocabulary Queryable Scene Representations for Real World Planning
用于LLM的上下文场景表示,Open-vocabulary Queryable,使LLMs-based planner更好接地,提供scene-scale
affordance grounding
Motivation
prior attempts to apply LLMs to real-world robotic tasks are limited by the lack of grounding in the surrounding scene
NLMap serves as a framework to gather and integrate contextual information into LLM planners, allowing them to see and query available objects in the scene before generating a context-conditioned plan.
ObjectNav重复探索的模式是低效的
Though a robot can avoid building a semantic representation by finding objects each time they are required, e.g., with Object Goal Navigation, this repeated exploration can be inefficient
Persistent Scene Representation可以避免重复的探索,但以往工作仅能定位构图阶段预定义的目标类别,无法实现开放词汇
- 如何连接semantic scene representation和planning
- 使用LLM最大的问题在于,LLMs are not grounded in the physical world
Related Work
Semantic Scene Representations
VLMaps [21]
Object Goal Navigation
- 本文任务与ObjectNav的区别与联系
Our work differs fromObject Goal Navigation since the eventual goal is not purely finding objects, but using object presence and location information for planning.
Our work can use the representation from a single exploration for many downstream planning tasks without the need to run Object Goal Navigation every time.
Planning with Scene Representations
Methodology
解决的两个核心问题:
如何保持一个开放词汇的场景表示,能够定位任意的对象
how to maintain open-vocabulary scene representations that are capable of locating arbitrary objects
如何将开放词汇场景表示和LLMs-based planner进行结合,使planner能够理解场景
how to merge such representations within long-horizon LLM planners to imbue them with scene understanding
整体流程:
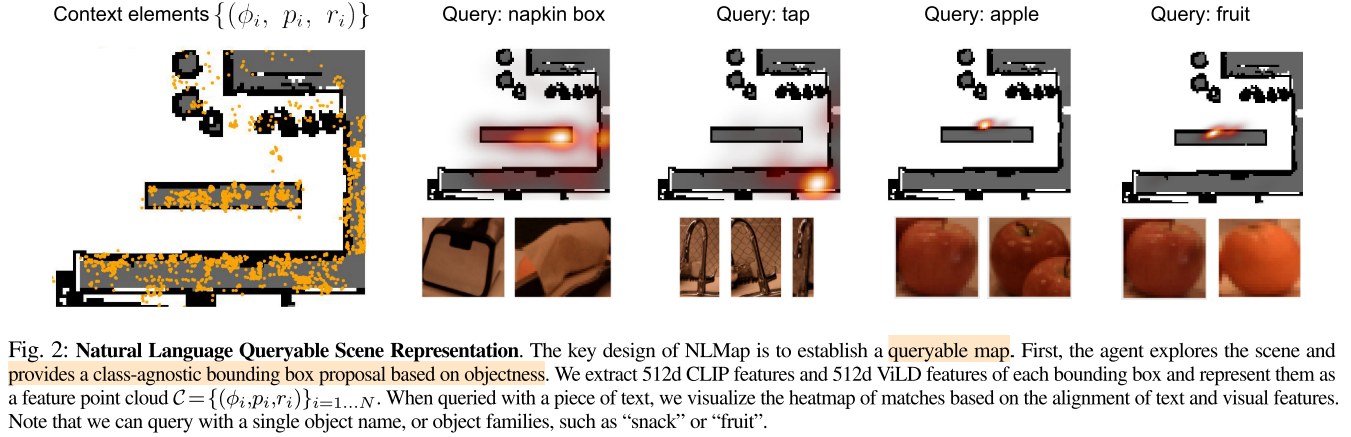
首先让机器人探索场景并收集观察结果。与类别无关的区域提议网络提出感兴趣的区域并利用VLMs提取特征。特征和对象边界框通过多视图融合算法聚合,以获得open-vocabulary scene representations
当人类发出指令时,LLMs会将指令解析为相关对象的列表。然后查询场景表示以了解这些对象的可用性和位置。可执行选项是根据找到的内容生成的。最后,机器人根据指令和找到的物体规划并完成任务。
After exploring the scene, when a human gives the robot an instruction, the robot will propose potentially involved objects in the scene and query the gathered scene representation for their locations and availability

Scene Representation
在探索期间,NLMap在所有观察到的RGB图像上使用类别无关的区域建议网络(ViLD中的)来得到的潜在对象区域$I$,利用ViLD和CLIP提取区域特征,使用一个三元组(特征,位置,尺寸)来描述一个对象:
$c_i=(\phi_i,p_i,r_i)$
其中$\phi_i=[\Phi_{clip_img}(I_i),\Phi_{vild_img}(I_i)]$ ,场景中的所有对象三元组构成了场景内容$\mathcal{C}$

Querying the Representation
为了完成由人类指令指定的任务,机器人需要查询场景表示来获得相关信息
首先将自然语言指令解析成relevant object name list,然后使用object name作为key去查询对象位置
- 使用few-shot prompt对LLM进行提示,利用LLM提取出完成指令所需要寻找的对象
然后根据在场景中找到的对象生成可执行选项,然后按照instruction进行计划和执行

查询时同时使用CLIP embedding和ViLD embedding(做ensemble,就是使用相似度更高的),因为前者能更好地检测分布外对象,而后者对常见对象更鲁棒。以下是相似度矩阵$D$的计算过程:
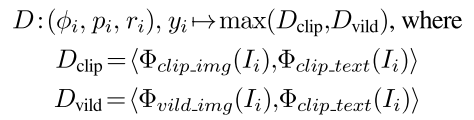
- the top k nearest neighbor elements for object name $y_i$ can be found in the scene representation $\mathcal{C}$,根据相似度矩阵设置阈值过滤掉低置信度的目标

- These top context elements are associated with ROIs, multiple of which may correspond to the same real-world 3D
object instance. 因此引入Multi-view fusion algorithm来对context elements聚合为3d object locations并通过一个聚合阈值来滤除并不存在的物体。
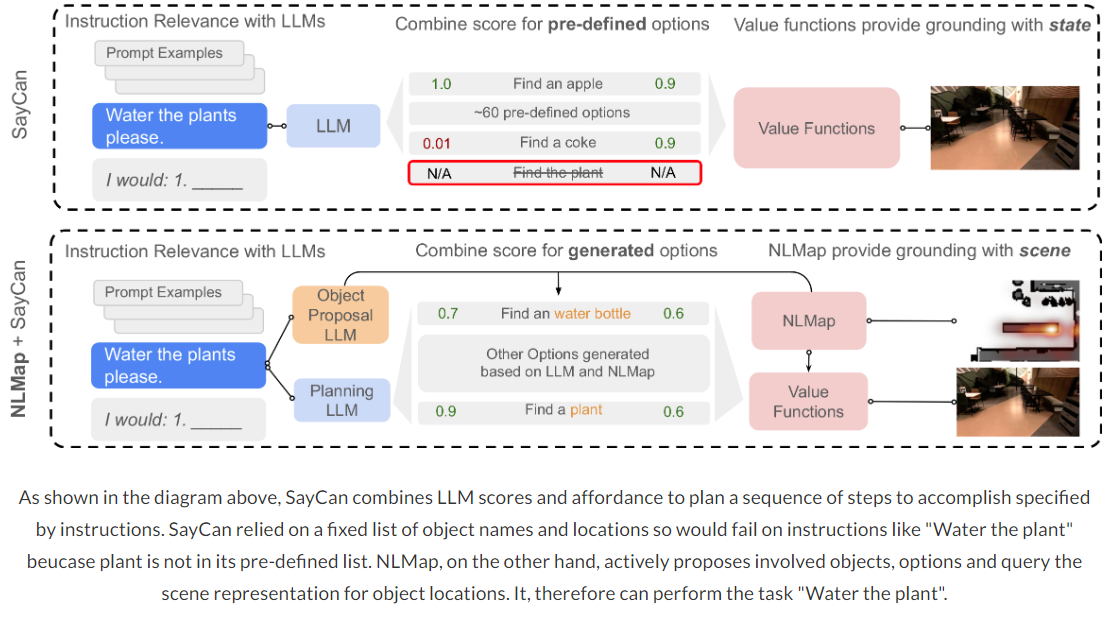
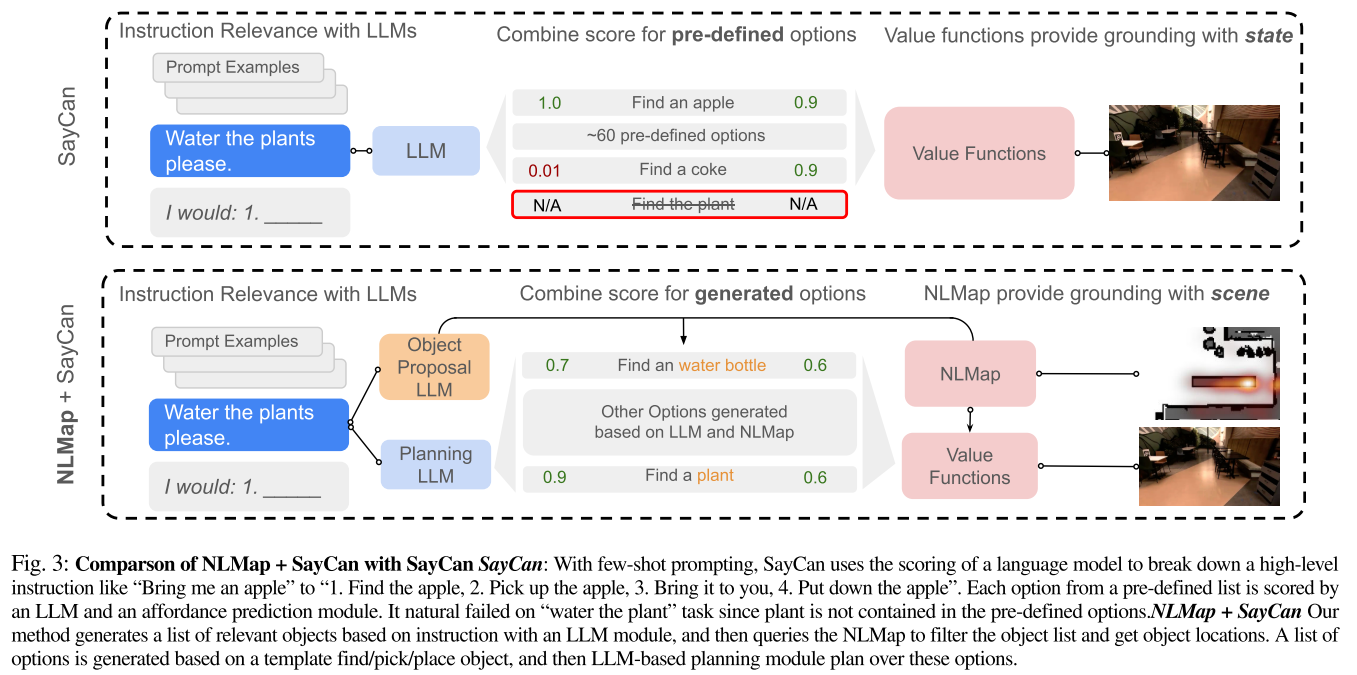
Combining NLMap and SayCan
开放词汇的场景表示可以与LLMs-based Planner结合使用,使机器人能够在真正不受控制的环境中操作
- SayCan relies on a hard-coded list of object names, locations, and executable options so its capability is largely limited by the lack of contextual grounding
- 借助CLIP可以帮助Generate executable options,生成更多可执行选项(具体怎么操作的没明白)
- Ground LLM planner with context:利用NLMap可以感知场景中可用的指令相关的对象,作为prompt的一部分输入LLM可以使LLM更好的接地
Prompt
附录