Enhancing CLIP with GPT-4: Harnessing Visual Descriptions as Prompts
Motivation
VLMs通常通过设计与数据集相关的prompt来zero-shot的适配下游数据集
将CLIP用于一个特定domain时,一种直白的prompt engineering方式是:
to classify bird images, one could construct a prompt ‘a photo of ${classname}$, a type of bird’.
但这样的prompt实际上并非最优方式:
- 不能引入有效的专家知识,无法获取target domain的domain expertise
- high variance:prompt小的变化就会引起性能的较大变化
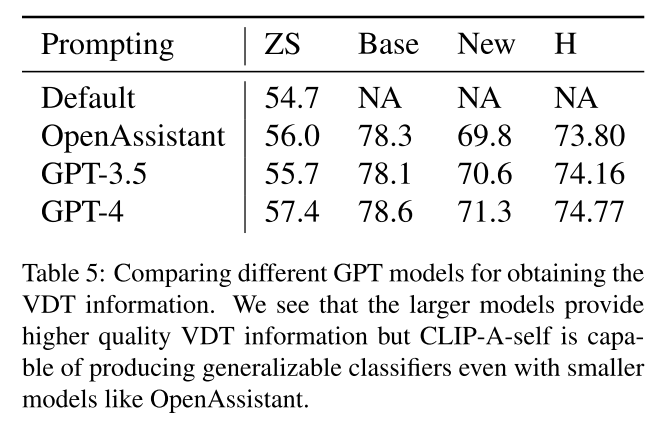
- 判别性的信息仅仅只有$classname$,而仅依赖$classname$无法完成一些类别的zero-shot的识别,比如name中带有green的green heron但是在外形上更接近black bittern而不是green woodpecker
因此需要引入visually descriptive textual (VDT) information
we define VDT as a set of sentences that describe the visual features of the class under consideration including shape, size, color, environment, patterns, composition, etc.
对于CUB,数据集中提供了domain expertise,其他数据集没有,因此引入LLM来构建复杂prompt,作者采用GPT-4来构建关于类的视觉描述性文本信息,prompt中特别强调了形状、颜色、结构和组成性等视觉线索。
对于high variance问题:作者使用Prompt ensembling the VDT sentences reduce CLIP’s performance sensitivity to small changes in the prompt.
Methodology
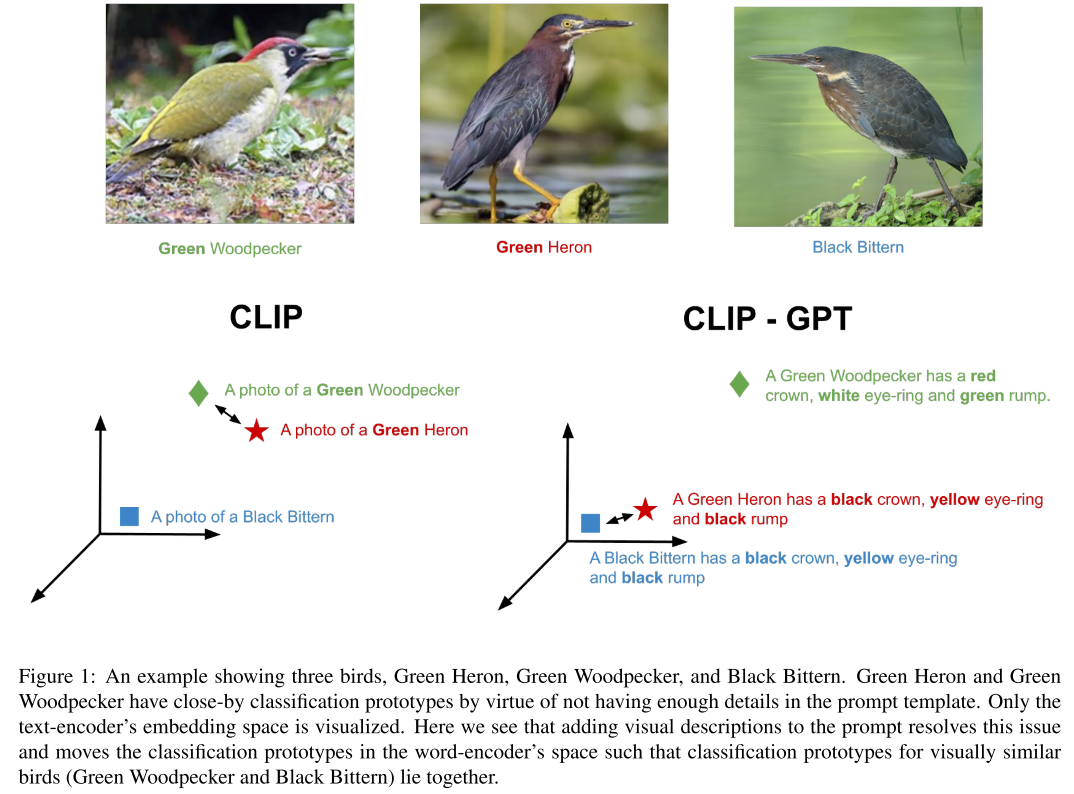
CLIP-A-self Overview
- self-attention based adapter learns to select and aggregate the most relevant subset of Visually Descriptive Text (VDT) to generate more generalizable classifiers.
- 使用GPT-4生成视觉描述文本,K个类别,每个类别对应的N个句子被送进CLIP的text encoder,得到$N\times K$个句子的embedding,然后使用Self-attention从每个类别的N个句子生成对应类别的adapted classifier embedding
Language Model Prompt Design
Visual Descriptive Sentences
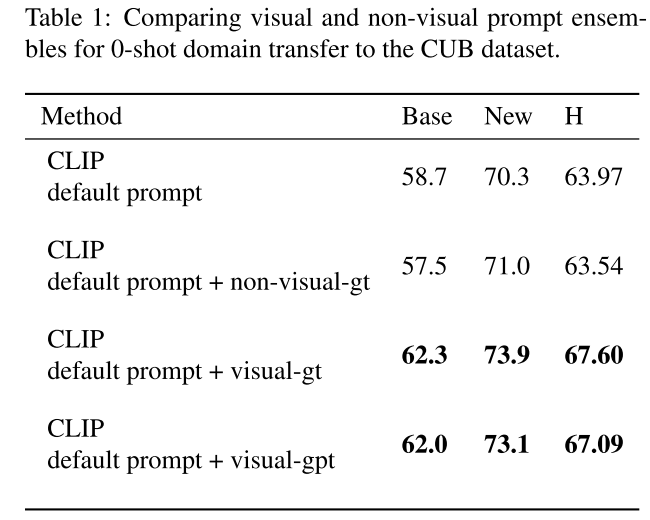
什么类型的信息添加到prompt template会提高zero-shot性能?
作者在CUB上进行了实验,比较了视觉描述和非视觉描述,结论是只有视觉相关的描述有用,而且GPT-4产生的视觉描述和GT视觉描述对结果的提升相近
visual descriptions of different body parts of the bird
non-visual descriptions of bird calls, migration patterns, behavioral patterns, and habitat
Prompting LLMs for visually descriptive information
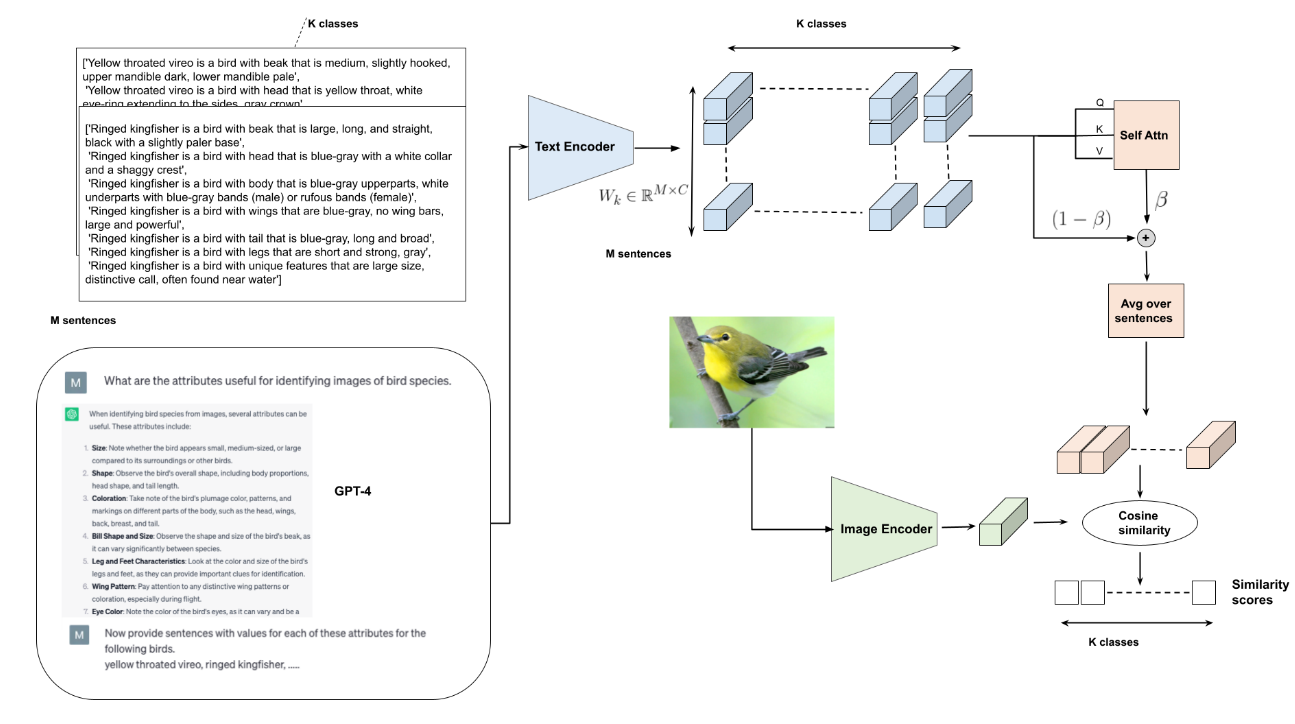
CoT prompting:
- First, we ask GPT-4 to list all the attributes that may be necessary to discriminate between images of the K classes under consideration.
- Second, we ask GPT-4 to provide the values for all these attributes for all the K classes as sentences
使用了GPT-4,但似乎没有使用多模态输入,还是文本对话,如下图所示


Simple few-shot adapters for visual sentences
使用交叉熵训练的Few-shot adapter有一个基本问题,即很难从该类的仅几个图像中识别出判别性特征,从而导致根据虚假的视觉特征,如环境、共同出现的对象等来识别对象。作者认为引入VDT可以解决这个问题,作者设计了两种adapter来加有效的利用VDT:
- CLIP-A-mlp is a 3-layer MLP that takes the average of sentence embeddings as input.
- CLIP-A-self adapter is a self-attention layer that applies attention over the embeddings of the different sentences for each class and averages the output.
使用CE loss对adapter进行训练
Experiment