3D-LLM
3D-LLM: Injecting the 3D World into Large Language Models
MLLMs如Flamingo,BLIP-2能够对2D image进行理解和推理,但是无法与3D物理世界接地,因此无法利用3D中的丰富信息,如空间关系,物理和交互等。
通过将场景的3D表示作为输入,使3D-LLM具有2个优势:
- 关于整个场景的长期记忆可以存储在整体3D表示中,而不是片段的部分视图观察
- 3D属性(如affordances和空间关系)可以从3D表示中推理出来,远超出了基于语言或基于2D图像的LLM的能力范围
本文的贡献点:
- 3D data paired with language description难以获取,本文提出了一个数据生成pipeline来生成大规模的3D data paired with language,最终得到300k的3D-language data(多任务)
- 如何提取能和语言特征对齐的3D特征?
- 使用渲染的2D多视图图像的特征构造3D特征
- 将3D转换为2D,然后就可以使用现成的VLMs如BLIP-2
- 如何感知3D空间位置关系
- 3D localization mechanism that bridges the gap between language and spatial locations

Related Work
- perceiver[2]
QFormers[31]
3D and language[5, 49, 8, 20, 1, 15, 24, 49, 3, 21, 19]
Methodology
使用LLM来完成3D-language data的收集
使用text-only GPT来产生数据的3种prompt
- boxes-demonstration-instruction based prompting:
- 输入3D场景中房间和物体的bounding boxes(AABB,坐标轴对齐), 以提供场景的语义和空间位置信息,使用不同指令来生成多种数据,并使用0-3个few-shot demonstration examples
- bbox的表示?坐标轴定义?需要看真实的prompt模板(appendix)
- ChatCaptioner based prompting:
- 将不同视角的图像输入BLIP-2,然后ChatGPT提问,BLIP-2回答
- [52] Chatgpt asks, blip-2 answers: Automatic questioning towards enriched visual descriptions, 2023.
- 例子中的far right,near left和多视角图像的对应关系?
- Revision based prompting:
- 用于不同类型3D data间的转换,比如有了caption,基于caption进行QA

用到的主要数据集:
- Objaverse:使用ChatCaptioner来对Objaverse生成3D-related descriptions,800K 3D objects
- Scannet:1k 3D indoor scenes,It provides semantics and bounding boxes of the objects in the scenes.
- Habitat-Matterport (HM3D):HM3DSem [47] further adds semantic annotations and bounding boxes for more than 200 scenes of HM3D.
3D-LLM
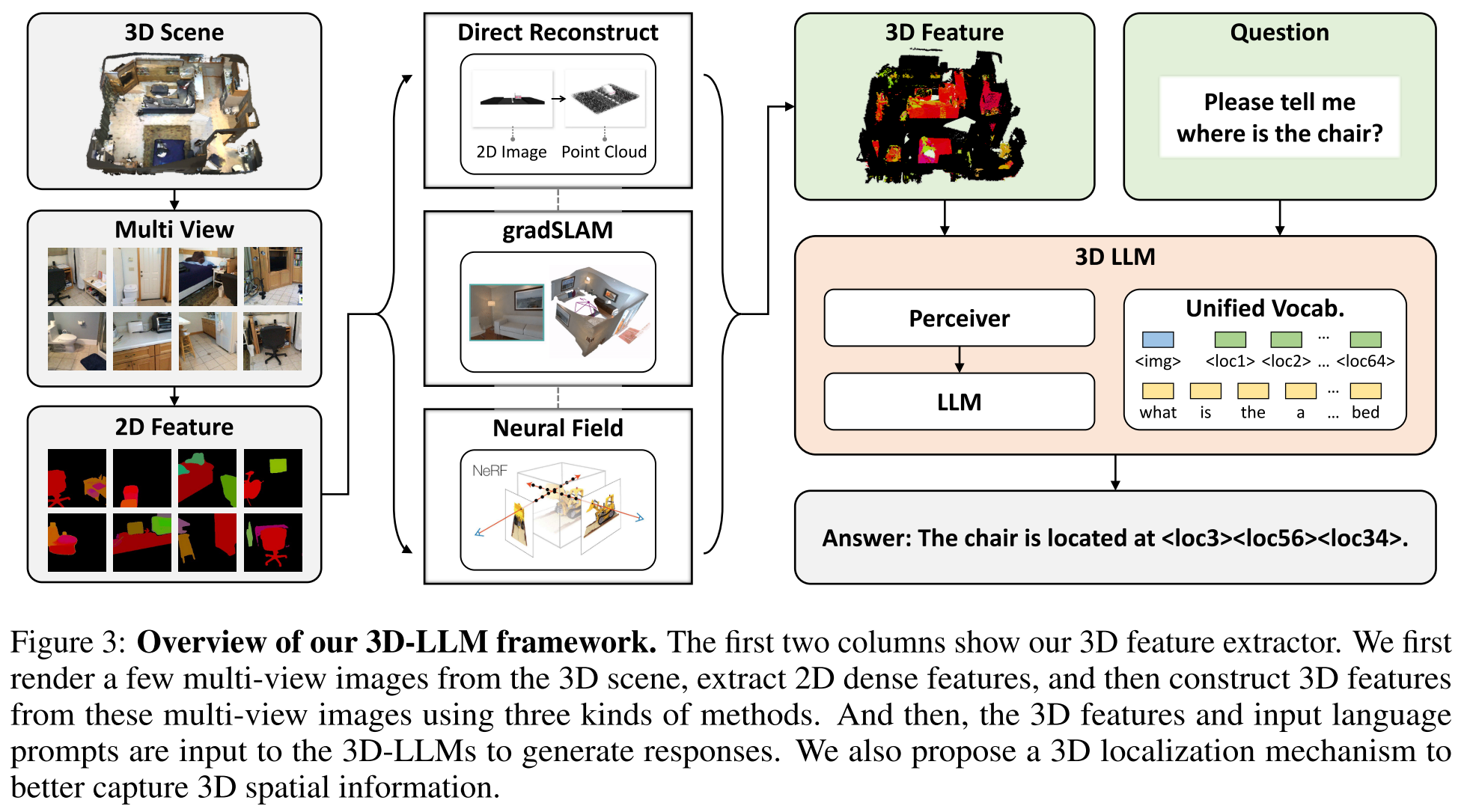
3D Feature Extractor
建立与language features对齐的3D features
首先从渲染的图片中提取pixel-aligned dense features(follow [26]Conceptfusion: Open-set multimodal 3D mapping)
然后使用三种方法来从渲染图像的特征建立3D特征
Direct Reconstruction:利用ground-truth camera matrixes直接从rgbd图像(3D data渲染得到的)重建点云,特征被直接映射到3D点云上
This method is suitable for rendered rgbd data with perfect camera poses and intrinsics
Feature Fusion:使用gradslam将2D feature映射到3D maps中,3D maps中融合了深度,颜色和特征
- [26] Conceptfusion: Open-set multimodal 3D mapping
- [28] gradslam: Dense slam meets automatic differentiation. arXiv, 2020.
This method is suitable for 3D data with noisy depth map renderings, or noisy camera poses and intrinsics
Neural Field:使用neural voxel field来建立3D表示,每个voxel都具有desity,color和feature,然后使用MSE loss对齐射线中的3D特征和像素中的2D特征。
- [20] 3D concept learning and reasoning from multi-view images, 2023.
This method is for 3D data with RGB renderings but no depth data, and noisy camera poses and intrinsics
通过这些方法,就可以得到$
Training 3D-LLMs
使用2D VLMs来作为backbone作为初始化,而不是从头训练
使用Perceiver架构来处理不同模态的桥接(Perceiver可以处理任意input size的数据),将3D点云数据视作打平的图像数据,送入perceiver,输出固定的尺寸的特征
- Perceiver: General perception with iterative attention. In International Conference on Machine Learning, 2021.
we use pretrained 2D VLMs as our backbones, input the aligned 3D features to train 3D-LLMs with our collected 3D-language dataset
3D Localization Mechanism
将xyz三个维度的sin/cos位置编码concat到3D features中,每个位置编码维度为$D_v/3$
region to be grounded可以表示为AABB形式边界框的离散tokens序列
边界框的连续角坐标被均匀离散为体素整数,作为location tokens $
After adding these additional location tokens, we unfreeze the weights for these tokens in the input and output
embeddings of language models. ?
Experiment
训练在8*A100
推理在8*8 V100
LLMs除了新加的location tokens之外都是冻结的,BLIP-2则是微调QFormer的部分,3D feature为1408-dim
训练时对所有任务的held-in datasets进行混合训练,使用standard language modeling loss
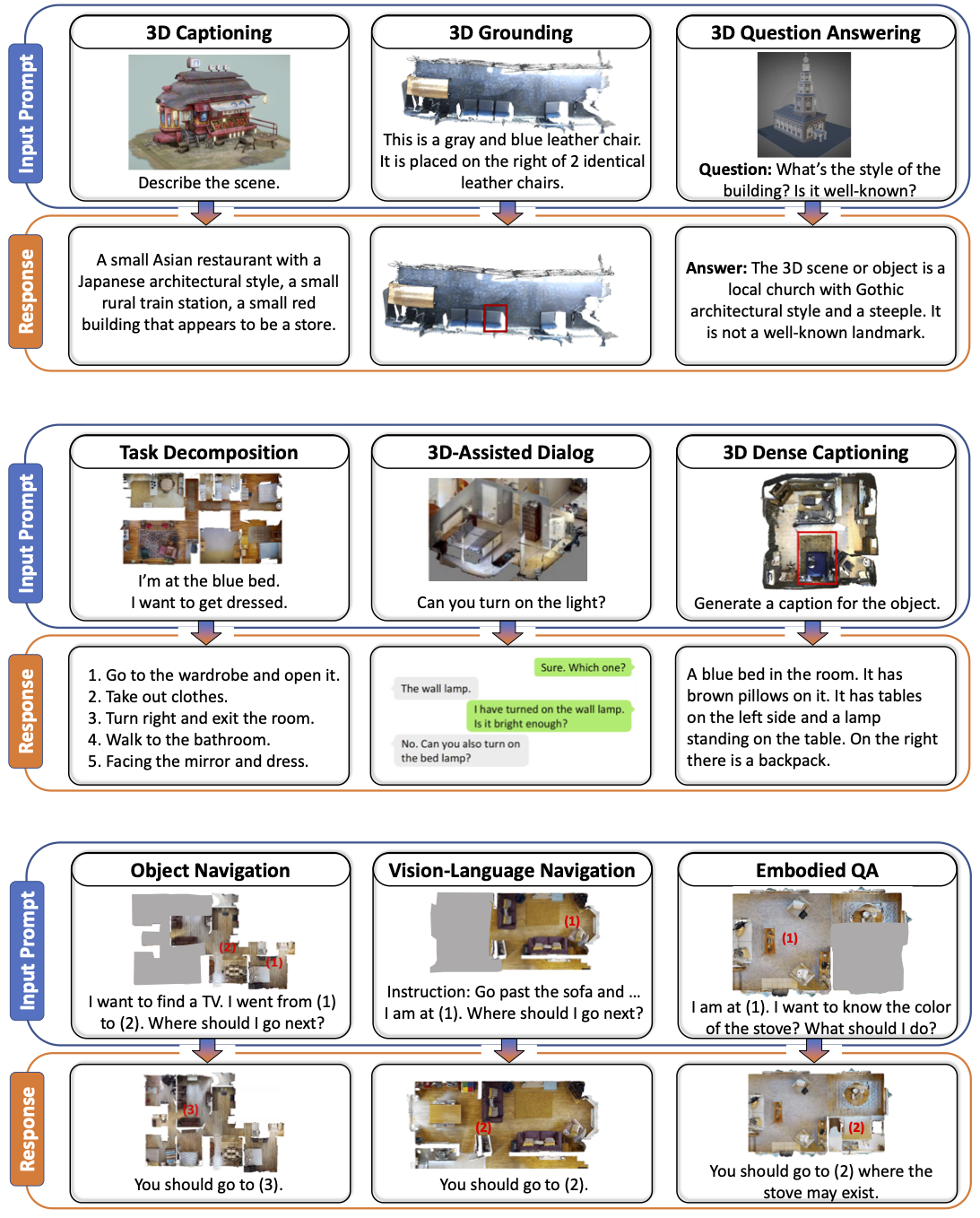
Object Navigation
将导航过程建模为对话,在每个time step,都会从观察到的部分场景在线建立3D features,将3D features,agent当前位置,以及历史位置送到3D-LLM中来预测一个3D waypoint(agent下一步应该去的位置),然后用DDPPO来输出low-level action。当到达位置时3D-LLM会预测’stop’.
在HM3D和Habitat上进行实验
