PROTO-CLIP
PROTO-CLIP: Vision-Language Prototypical Network for Few-Shot Learning
Motivation
在机器人感知的setting下:
- object model-based方法建立物体的3D模型,并用3D模型来进行物体识别,但真实世界中难以获取大规模的3D模型
- object catagory-based方法识别有限类别的物体,很难对每个类别都收集大量的图像
- ImageNet和Visual Genome这类Internet data和robot manipulation存在domain gap
因此从少量的图片示例中学习如何识别一个新的物体对于scale up机器人可识别的物体非常重要
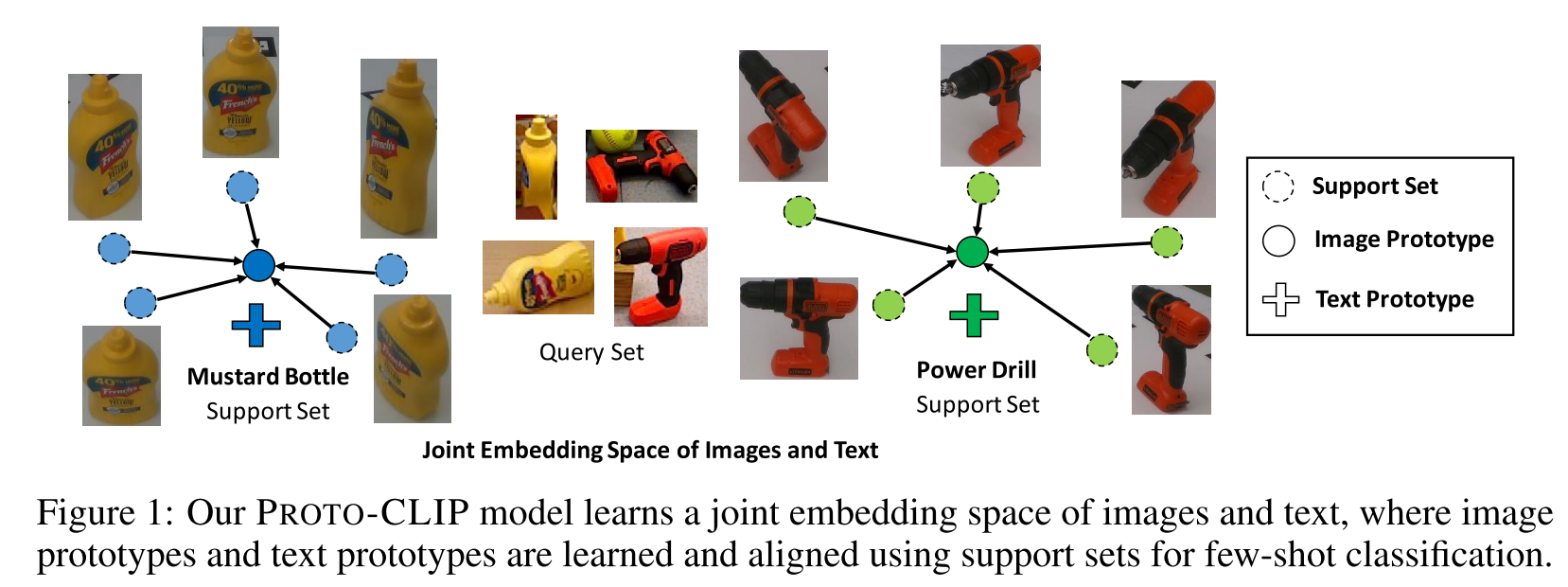
基于few-shot training images同时adapt图像和文本编码器,在adapt过程中对齐图像原型和文本原型,以提升few-shot classification性能
Related Work
CLIP-based Few-Shot Learning
N-way, K-shot Setting
N个类别,每个类别K张图像,$N\times K$张图像用于训练
模型训练好后就可以用于N个类别的测试
将原始的CLIP称作Zero-shot CLIP,
Linear-probe CLIP则表示在CLIP的图像特征基础上训练一个logistic regression classifier
adapt the text encoder
CoOp: 可学习的text prompt
[8] Learning to prompt for vision-language models. IJCV2022
adapt the image encoder
Clip-adapter: 在图像编码器端加两层linear transformertions,文本编码器加残差连接进行few-shot learning
[9] Clip-adapter: Better vision-language models with feature adapters 2021
Tip-adapter: 建立key-value cache model,keys是CLIP的图像特征,values是类别标签的one-hot vectors(也可以替换为可学习参数,提高分类准确率)。
[10] Tip-adapter: Training-free adaption of clip for few-shot classification 2022

Meta-learning-based Few-Shot Learning
setting:
每个类别都包含support set和query set,在训练期间,support set和query set的类别标签都是可用的,测试时只有support set可用,目标是预测query set的标签
与CLIP-based Few-Shot Learning的N-way, K-shot Setting区别在于CLIP-based Few-Shot Learning N-way, K-shot Setting并不对训练集进行划分,train和test是在相同的类别上进行的,而Meta-learning-based approaches则是使用训练集类别来训练一个meta-learner,在novel classes上利用对应的support sets进行adapt
Meta-learning-based approaches train a meta-learner with the training classes $C_{train}$ that can be adapted to the novel classes $C_{test}$ using their support sets.
- Non-episodic approaches use all the data in Ctrain for training such as k-NN and its ‘Finetuned’ variants
- Episodic approaches construct episodes, i.e., a subset of the training classes, to train the meta-learner
- Prototypical Networks
- Matching Networks
- Relation Networks
- Model Agnostic Meta-Learning (MAML)
- Proto-MAML
- CrossTransformers
- In this work, we consider training and testing in the same classes following previous CLIP-based few-shot learning methods [8, 9, 10].
Others
- 机器人环境的fsl数据集:
- [15] Fewsol: A dataset for few-shot object learning in robotic environments
Methodology
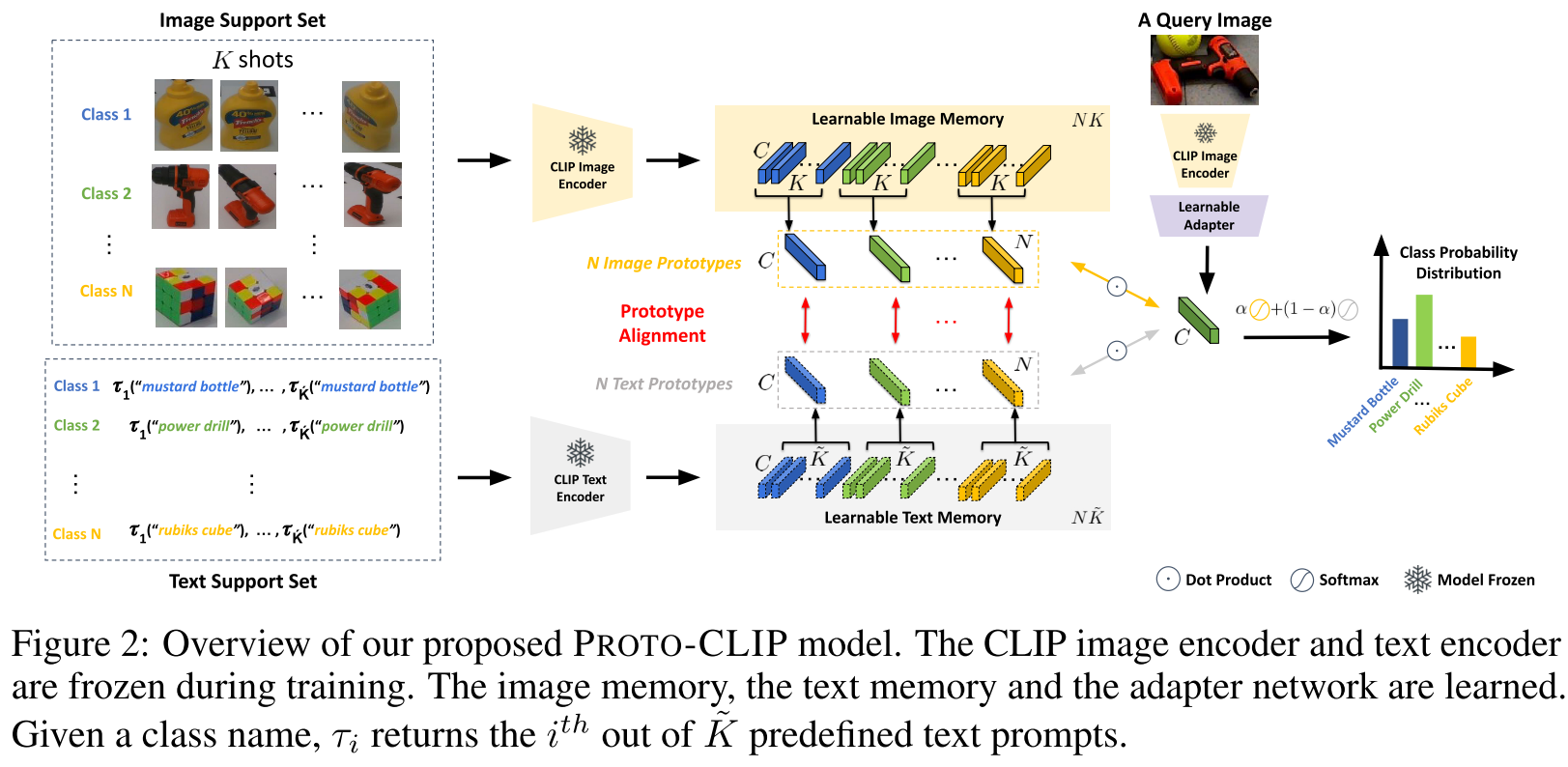
本文直接考虑N-way K-shot classification
CLIP模型全程冻结,利用CLIP模型的图像编码器和文本编码器获得分类概率,最终的条件分类概率表示为image probability和text probability的加权和,用超参$\alpha$来控制。
$P\left(y=k \mid \mathbf{x}^{q}, \mathcal{S}\right)=\alpha \underbrace{P\left(y=k \mid \mathbf{x}^{q}, \mathcal{S}_{x}\right)}_{\text {image probability }}+(1-\alpha) \underbrace{P\left(y=k \mid \mathbf{x}^{q}, \mathcal{S}_{y}\right)}_{\text {text probability }},$
使用prototypical networks来建模给定query图像$\mathbf{x}^q$和support set $S=\{\mathbf{x}_i^s,y_i^s\}^M_{i=1}$时class label $y$的条件概率分布
$\begin{aligned}
P\left(y=k \mid \mathbf{x}^{q}, \mathcal{S}_{x}\right) & =\frac{\exp \left(-\beta\left|g_{\mathbf{w}_{1}}\left(\mathbf{x}^{q}\right)-\mathbf{c}_{k}^{x}\right|_{2}^{2}\right)}{\sum_{k^{\prime}=1}^{N} \exp \left(-\beta\left|g_{\mathbf{w}_{1}}\left(\mathbf{x}^{q}\right)-\mathbf{c}_{k^{\prime}}^{x}\right|_{2}^{2}\right)}, \\
P\left(y=k \mid \mathbf{x}^{q}, \mathcal{S}_{y}\right) & =\frac{\exp \left(-\beta\left|g_{\mathbf{w}_{1}}\left(\mathbf{x}^{q}\right)-\mathbf{c}_{k}^{y}\right|_{2}^{2}\right)}{\sum_{k^{\prime}=1}^{N} \exp \left(-\beta\left|g_{\mathbf{w}_{1}}\left(\mathbf{x}^{q}\right)-\mathbf{c}_{k^{\prime}}^{y}\right|_{2}^{2}\right)},
\end{aligned}$- 其中$g_{\mathbf{w}_{1}}(\cdot)$代表CLIP图像编码器+adapter network(可学习参数$\mathbf{w}_1$)的组合,用于计算query图像的特征
- $\mathbf{c}_{k}^{x},\mathbf{c}_{k}^{y}$are the “prototypes” for class k computed using images and text, respectively.
- $\beta \in \mathbb{R}^+$ is a hyperparameter to sharpen the probability distributions
代码:
1 | def P(zq_imgs_flat, z_img_proto, z_text_proto, alpha, beta): |
class $k$的prototypes表示为:
$\mathbf{c}_{k}^{x}=\frac{1}{M_{k}} \sum_{y_{i}^{s}=k} \phi_{\text {Image }}\left(\mathbf{x}_{i}^{s}\right), \mathbf{c}_{k}^{y}=\frac{1}{\tilde{M}_{k}} \sum_{j=1}^{\tilde{M}_{k}} \phi_{\text {Text }}\left(\operatorname{Prompt}_{j}\left(y_{i}^{s}=k\right)\right),$
- $M_k$代表label为$k$的图像样本数量,$\tilde M_k$代表label $k$对应的prompts数量
- prototype被表示为多个example的特征做平均
Learning the memories and the adapter
adapter采用基于卷积的方式,参数量更少,两种adapter各有优势(见实验部分)
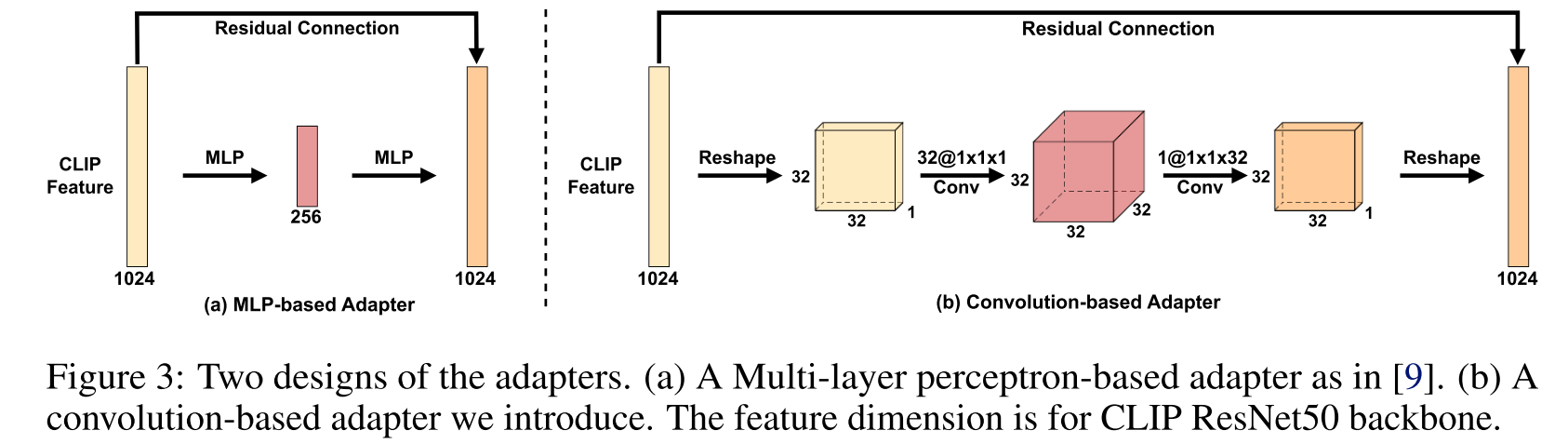

Loss Functions
query图像的分类损失
$\mathcal{L}_{1}\left(\mathbf{W}_{\text {image }}, \mathbf{W}_{\text {text }}, \mathbf{w}_{1}\right)=-\log P\left(y^{q}=k \mid \mathbf{x}^{q}, \mathcal{S}\right)$
- $\mathbf{W}_{\text {image }}$代表image memory,$\mathbf{W}_{\text {text }}$代表text memory,$\mathbf{w}_{1}$代表adapter network的可学习参数
- $P\left(y^{q}=k \mid \mathbf{x}^{q}, \mathcal{S}\right)$是前面提到的条件概率分布
在训练阶段将image prototypes和text prototypes进行对齐
$\{\mathbf{c}_{1}^{x},\mathbf{c}_{2}^{x},…,\mathbf{c}_{N}^{x}\}$表示image prototypes,$\{\mathbf{c}_{1}^{y},\mathbf{c}_{2}^{y},…,\mathbf{c}_{N}^{y}\}$表示text prototypes
基于对比学习在特征空间拉近$\mathbf{c}_{k}^{x},\mathbf{c}_{k}^{y}$之间的距离,并拉远与其他prototypes间的距离,使用InfoNCE loss:
$\mathcal{L}_{2}^{k}\left(\mathbf{c}_{k}^{x},\left\{\mathbf{c}_{k^{\prime}}^{y}\right\}_{k^{\prime}=1}^{N}\right)=-\log \frac{\exp \left(\mathbf{c}_{k}^{x} \cdot \mathbf{c}_{k}^{y}\right)}{\sum_{k^{\prime}=1}^{N} \exp \left(\mathbf{c}_{k}^{x} \cdot \mathbf{c}_{k^{\prime}}^{y}\right)}, \mathcal{L}_{3}^{k}\left(\mathbf{c}_{k}^{y},\left\{\mathbf{c}_{k^{\prime}}^{x}\right\}_{k^{\prime}=1}^{N}\right)=-\log \frac{\exp \left(\mathbf{c}_{k}^{y} \cdot \mathbf{c}_{k}^{x}\right)}{\sum_{k^{\prime}=1}^{N} \exp \left(\mathbf{c}_{k}^{y} \cdot \mathbf{c}_{k^{\prime}}^{x}\right)}$
训练时的总loss function:
$\begin{array}{c}
\mathcal{L}=-\frac{1}{L} \sum_{j=1}^{L} \log P\left(y_{j}^{q}=k \mid \mathbf{x}_{j}^{q}, \mathcal{S}\right)+\frac{1}{N} \sum_{k=1}^{N}\left(\mathcal{L}_{2}^{k}\left(\mathbf{c}_{k}^{x},\left\{\mathbf{c}_{k^{\prime}}^{y}\right\}_{k^{\prime}=1}^{N}\right)+\mathcal{L}_{3}^{k}\left(\mathbf{c}_{k}^{y},\left\{\mathbf{c}_{k^{\prime}}^{x}\right\}_{k^{\prime}=1}^{N}\right)\right)
\end{array}$
1 | if len(cfg['losses']) == 0 or 'L1' in cfg['losses']: |
文本端
以oxford_pets为例,共37类
1 | template = ['a photo of a {}, a type of pet.'] |
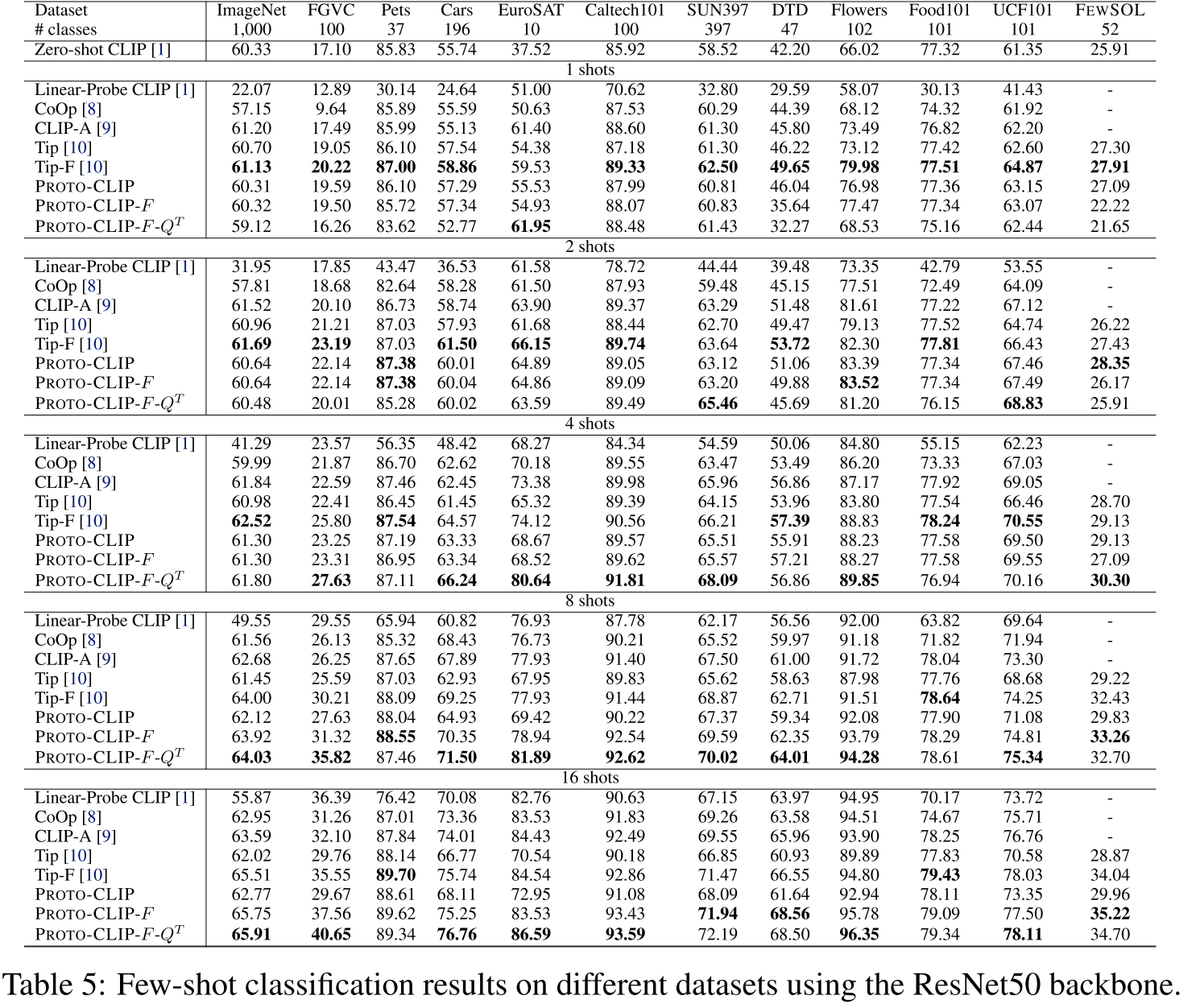
Experiment
Datasets and Evaluation Metric
- ImageNet [5], StandfordCars [24], UCF101 [25], Caltech101 [26], Flowers102 [27], SUN397 [28], DTD [29],
EuroSAT [30], FGVCAircraft [31], OxfordPets [32], and Food101 [33], FewSOL dataset [15]
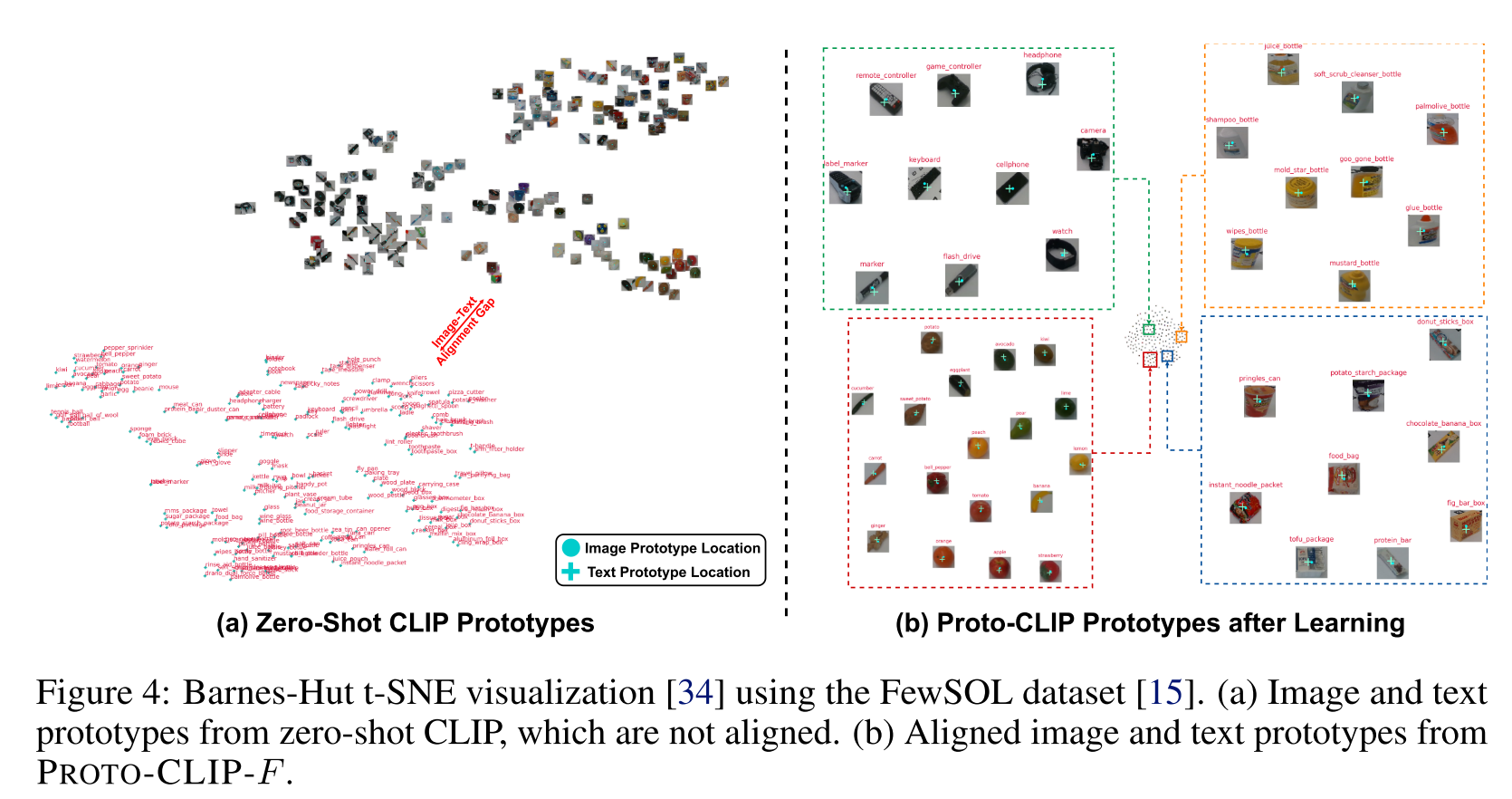
- Tip-F是Tip-Adapter的fine-tuned版本
- PROTO-CLIP代表没有对the image memory and the text memory进行训练,没有使用adapter
- PROTO-CLIP-F代表train the image memory and/or the text memory with the adapter,图片特征是预先抽取的
- PROTO-CLIP-F-$Q^T$代表训练阶段使用了数据增强操作,图片让特征是在训练时抽取的
Limitations
- low-shot情况下表现不佳,不如Tip
- 在每个新的数据集上都需要做hyperparameter grid search,每个数据集都需要不同的设置