Navigating to Objects in the Real World

任务难点:
- 机器人需要具备区分自由空间和障碍物的空间场景理解能力
- 检测物体的语义场景理解
- 还需要学习语义探索先验。例如,如果一个人想在这个场景中找到厕所,我们大多数人都会选择走廊,因为它最有可能通向厕所。向agent教授这种常识或语义先验是富有挑战的。
- 在探索场景寻找所需物体的同时,机器人还需要长期情景记忆来记住已探索和未探索的区域。
本文关注了真实世界中的寻物导航问题,比较了经典,端到端和模块化学习三种方法

Methods Overview
三类方法:
- Classical: 经典方法是使用深度传感器构建几何地图,以启发式方式探索环境,例如frontier exploration(前沿探索),探索最近的未探索区域(将最近的未探索区域作为navigation goal,因此与语义目标无关),并使用analytical planner在看到目标物体时立即达到探索目标和目标物体。
- End-to-end Learning: 端到端学习方法通过深度神经网络直接根据原始观察来预测动作,该神经网络由图像帧的视觉编码器和随后的记忆循环层组成。
- Modular Learning: 模块化学习方法通过使用深度投影预测的语义分割来构建语义图,使用面向目标的语义策略作为语义图和目标对象的函数来预测探索目标。(模块化学习方法保留了经典方法的框架,replace analytical modules for specific subtasks with learned ones)
- perception (object detection, mapping, pose estimation, SLAM)
- encoding goals
- global waypoint selection policies
- planning
- local obstacle avoidance policies
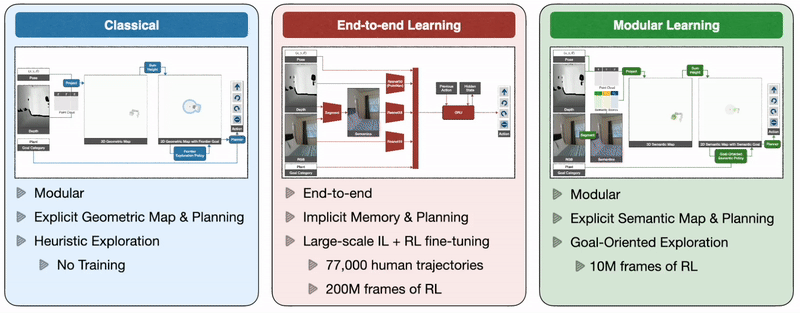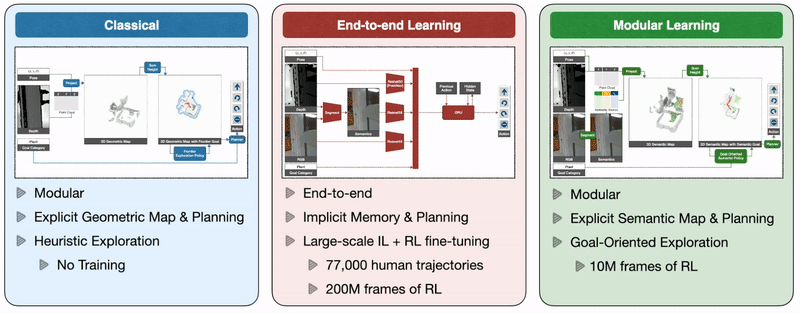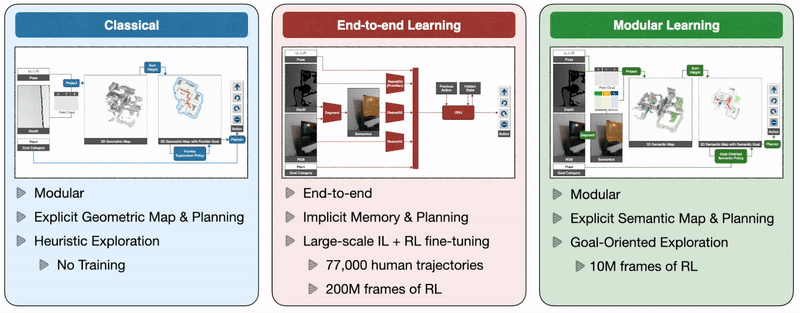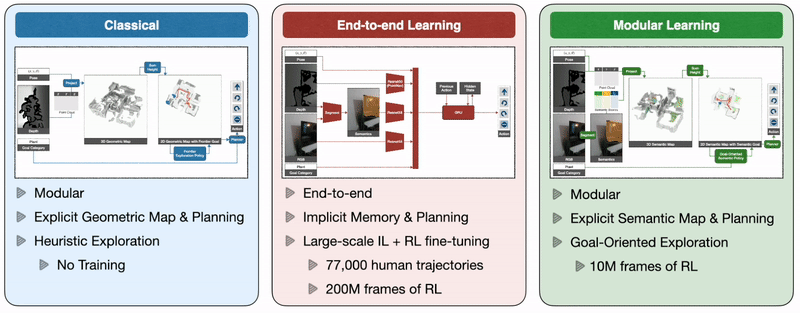
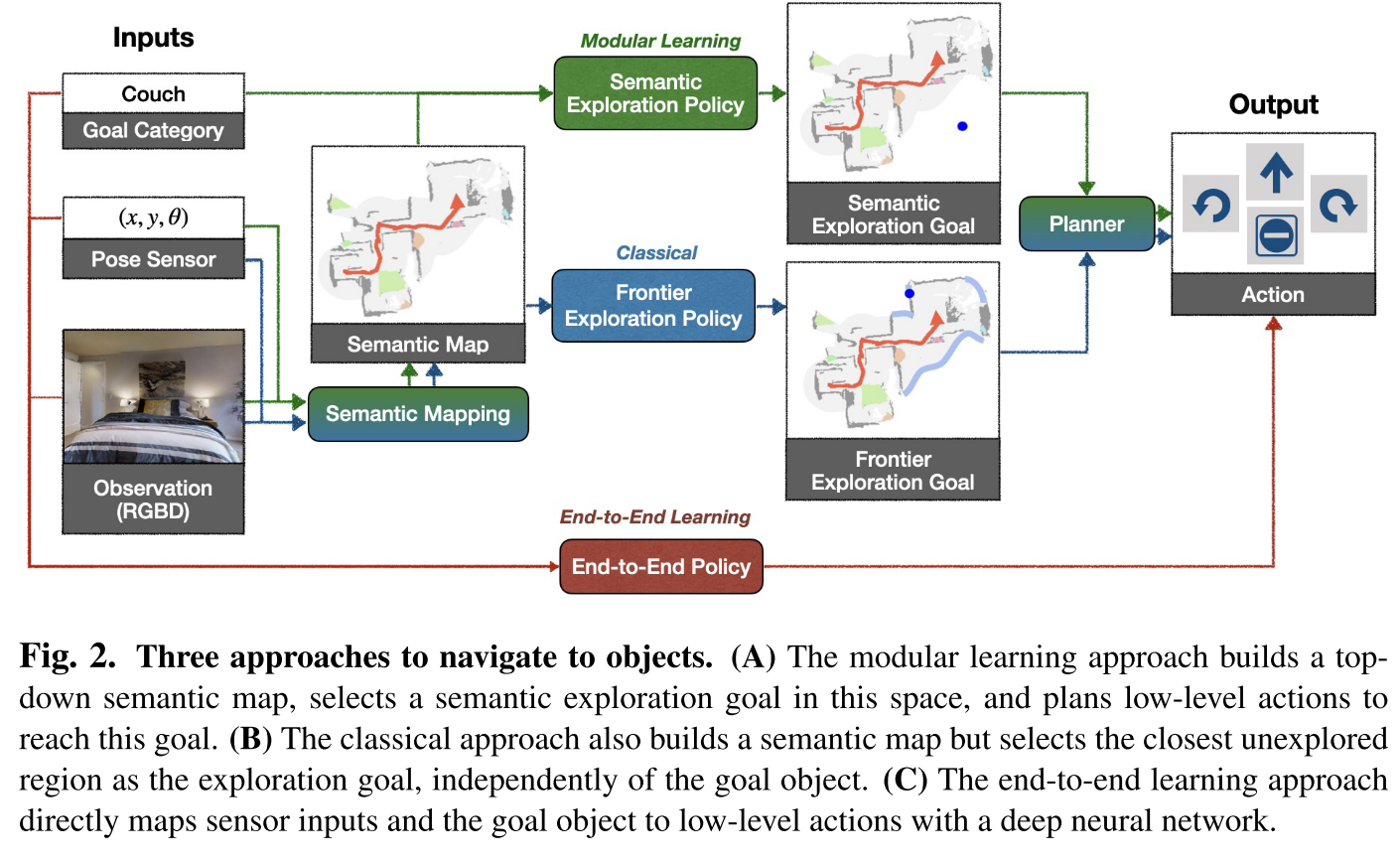
Classical and Modular Learning Approaches
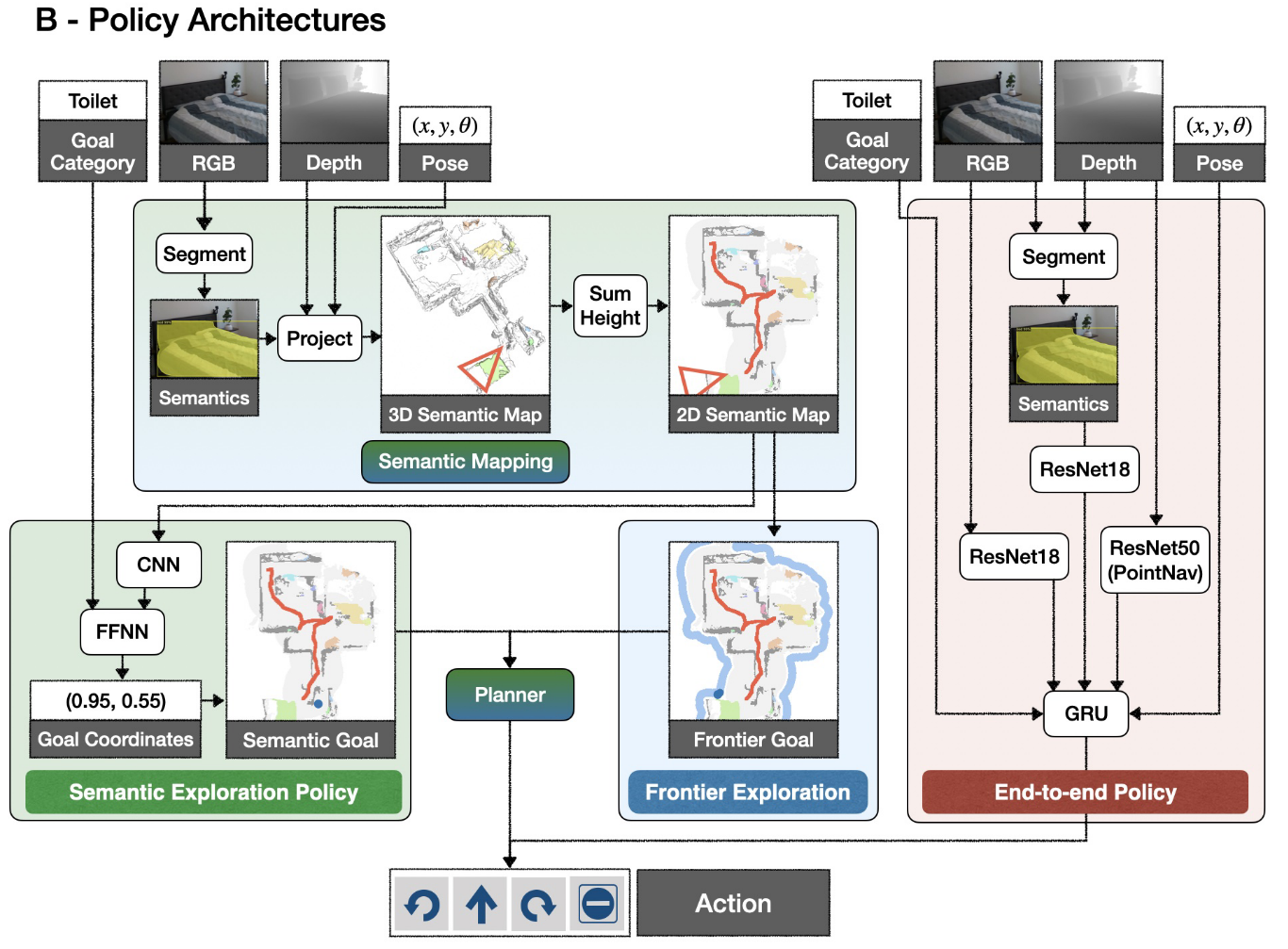
Extending Classical Approaches to Navigate to Objects
将传统的SLAM方法扩展到寻物导航需要进行object detection,keeping objects in memory, and exploring
semantically towards objects- Semantic SLAM methods [19, 20, 21, 22, 23, 24] naturally extend SLAM to detect objects and keep them in memory in a spatial semantic map but offer no solution for efficient semantic exploration.
- 在经典的goal-agnostic exploration的许多启发式方法中,作者选择frontier-based exploration [18] (1997的方法)(向最近的未探索区域导航)来代表经典探索方法,因为它在以前的工作中特别有效。
上图表示了经典方法的pipeline,包含了:
- semantic mapping to keep seen objects in memory
- frontier exploration to select high-level goals
- path planning to select low-level actions
本文关注的设定是:navigating to a single object starting with zero information about the environment — the setting we evaluate in this paper — we don’t even need to keep objects in memory in a semantic map in the classical approach
Modular Learning to Navigate to Objects
- frontier exploration很有效,但是忽略了对象目标,因此是次优的
- 利用家中物体布局的统计规律来更有效地探索(猜测目标更有可能在哪)
- Object goal navigation using goal-oriented semantic exploration[62]作为代表方法
Semantic Map Representation
与Object goal navigation using goal-oriented semantic exploration[62]中一致
Semantic Mapping Module
使用Mask-RCNN with ResNet50 backbone pretrained on MS-COCO for object detection and instance segmentation.然后利用深度信息将第一视角的语义分割结果投影到3D点云中去,并将点云转换为3D semantic voxel map,使用agent pose将其从机器人的坐标系变换到语义地图的坐标系,并且最后对高度求和以计算2D语义地图。
Frontier Exploration Policy
frontier exploration: each step, we select the boundary between the explored and unexplored region of the map, i.e., the frontier, and within this boundary select the point closest to the robot in geodesic distance.
这种探索策略表现出深度优先搜索行为:一旦机器人朝一个方向前进,最近的未探测区域就在它的前面,直到障碍物挡住了路。一旦看到目标对象,即对象目标的语义映射的通道具有非零元素,我们就停止探索并选择所有非零元素作为目标。
Semantic Exploration Policy
根据当前语义图和目标对象来决定goal
This requires learning semantic priors on the relative arrangement of objects and areas in homes.
Planner
Fast Marching Method [108]
Experiments
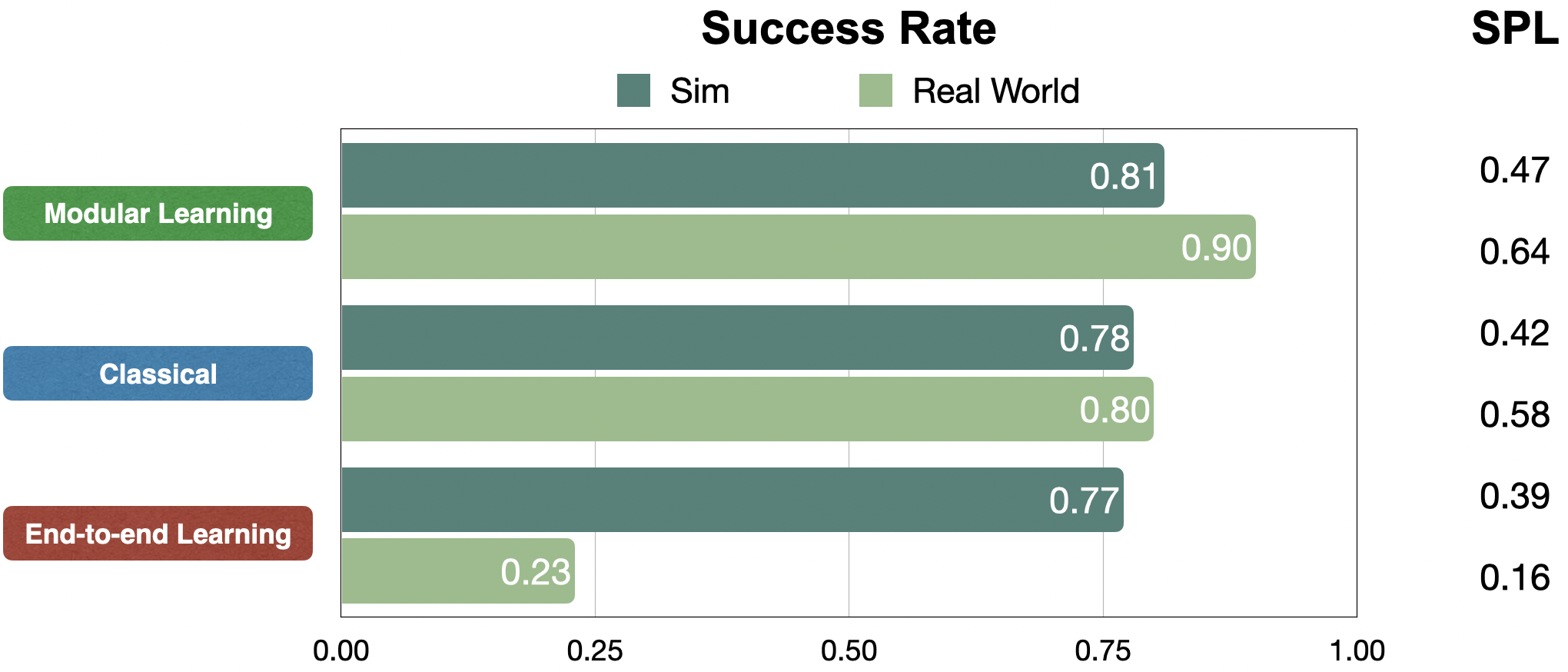
本文在6个不同场景的6个目标类别上进行实验,对比了三类方法

经典方法和模块化方法的sim-to-real迁移能力较强,而端到端的方法则有较大gap
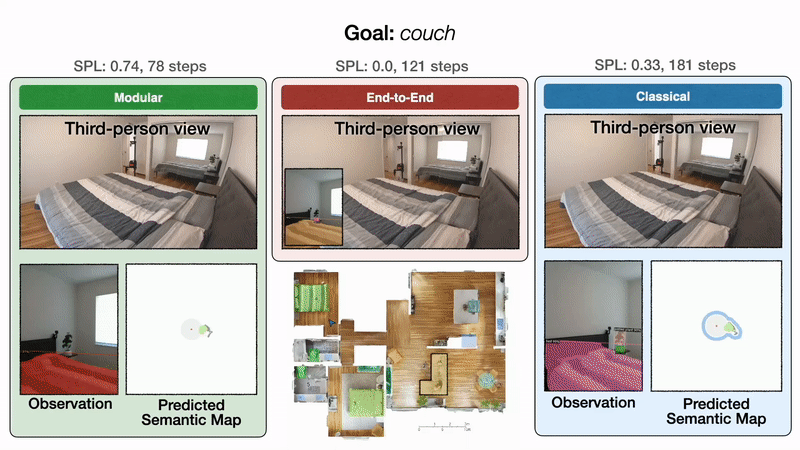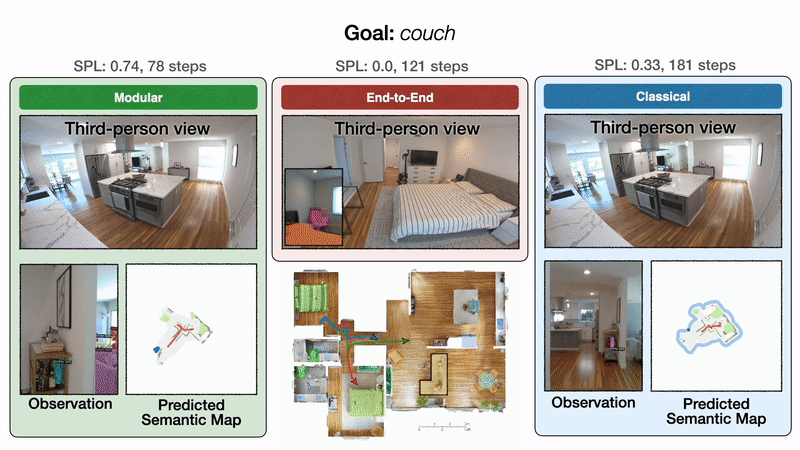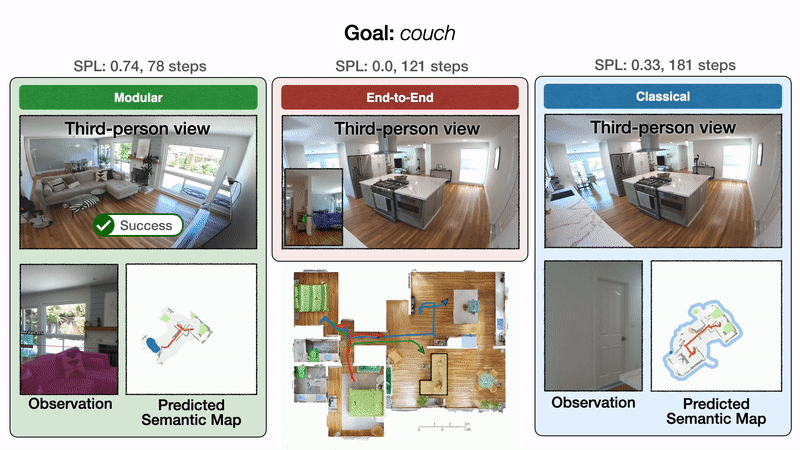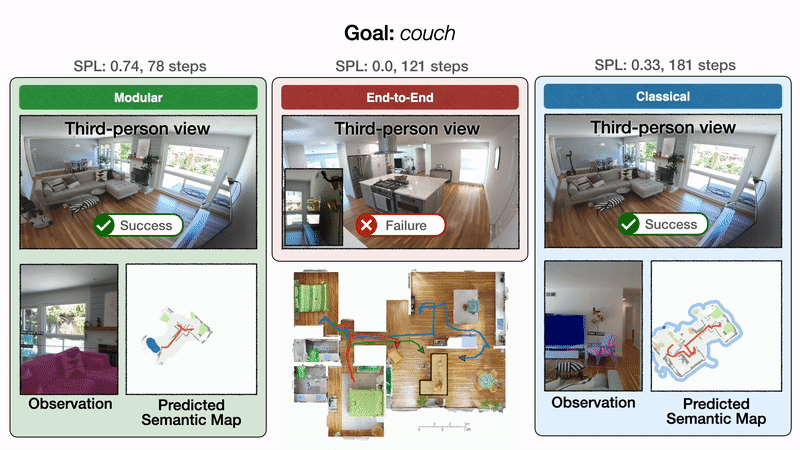
三种方法的trajectory示意图
结论:
Modular Learning is Reliable(90% success rate)
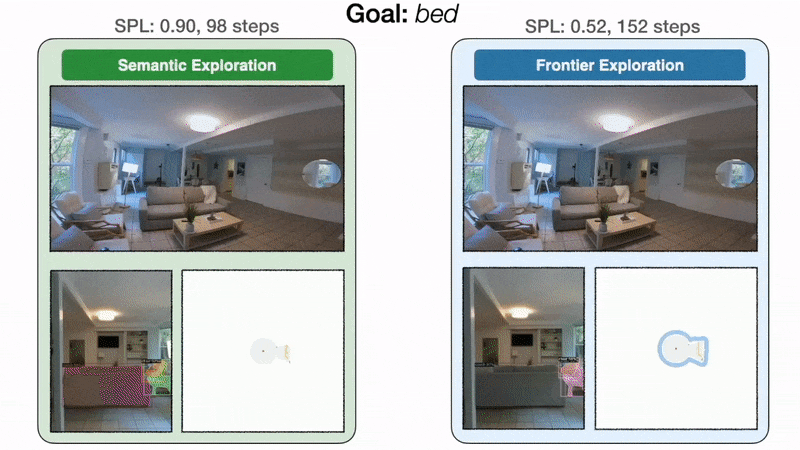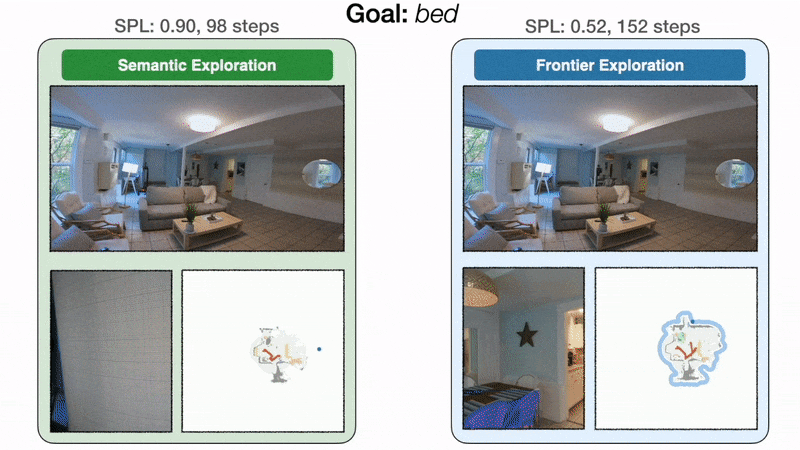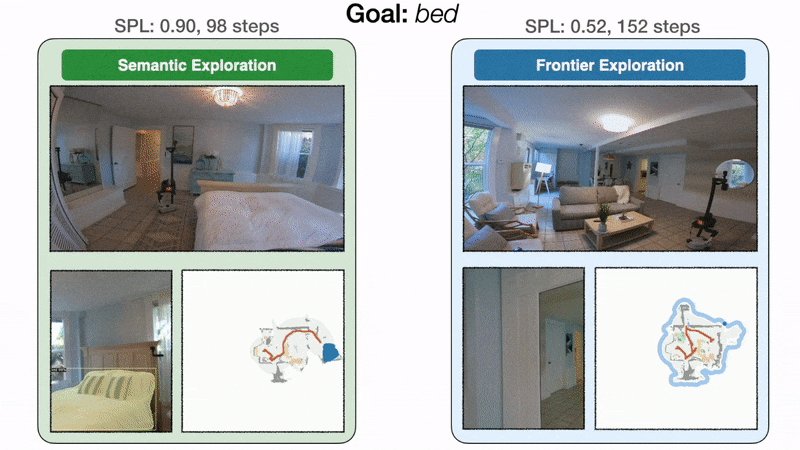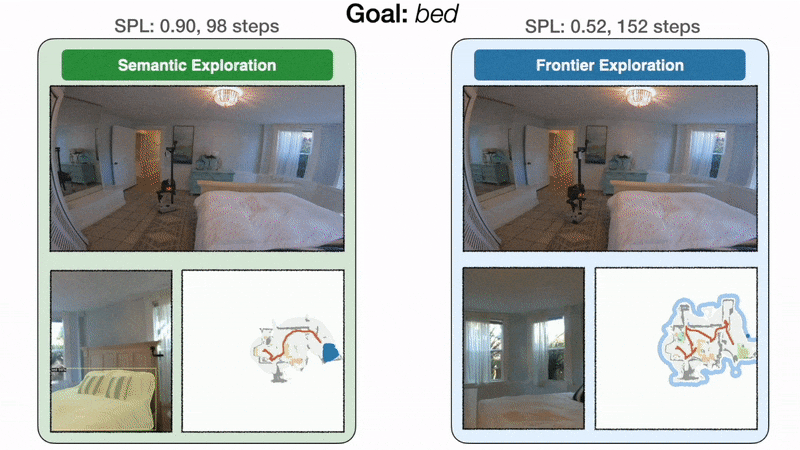
Modular Learning Explores more Efficiently than Classical
- 经典方法在进行frontier exploration的时候是和语义目标无关的
- 与经典方法相比,模块化学习在现实世界中的成功率提高了 10%
- 在左侧,面向目标的语义探索策略直接前往卧室,并以 98 步找到床,SPL 为 0.90。在右侧,由于前沿探索与床目标无关,因此该策略绕道厨房和入口走廊,最终以 152 步到达床,SPL 为 0.52。
End-to-end Learning Fails to Transfer
- only 23% success rate
Analysis
Insight 1: Why does Modular Transfer while End-to-end does not?
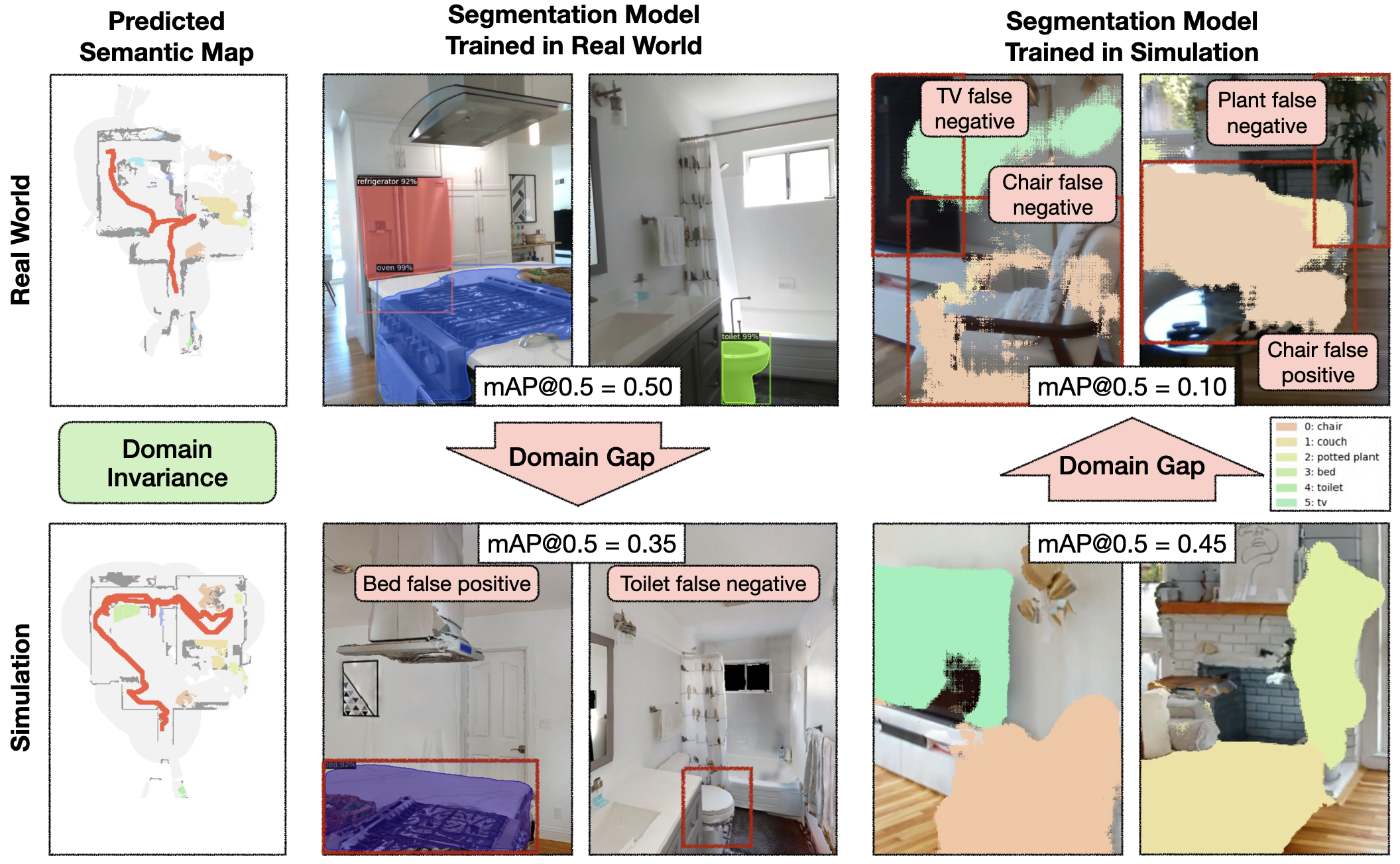
模块化学习方法的semantic exploration policy以语义图作为输入,而端到端策略直接对 RGB-D frames进行操作。The semantic map space is invariant between sim and reality, while the image space exhibits a large domain gap.
语义图空间在模拟和现实之间是不变的,而图像空间则表现出很大的域差距。在此示例中,这种差距导致了在现实世界图像上训练的分割模型,以预测厨房中的床误报。
The semantic map domain invariance(semantic map在sim和real中基本不变)使得模块化学习方法能够很好地从模拟迁移到现实
当将现实世界中训练的分割模型转移到simulator时,图像域之间的巨大gap会导致性能大幅下降,反之亦然。如果语义分割从模拟到现实的迁移很差,那么可以合理地预期在模拟图像上训练的端到端语义导航策略很难转移到现实世界中
Insight 2: Sim vs Real Gap in Error Modes for Modular Learning
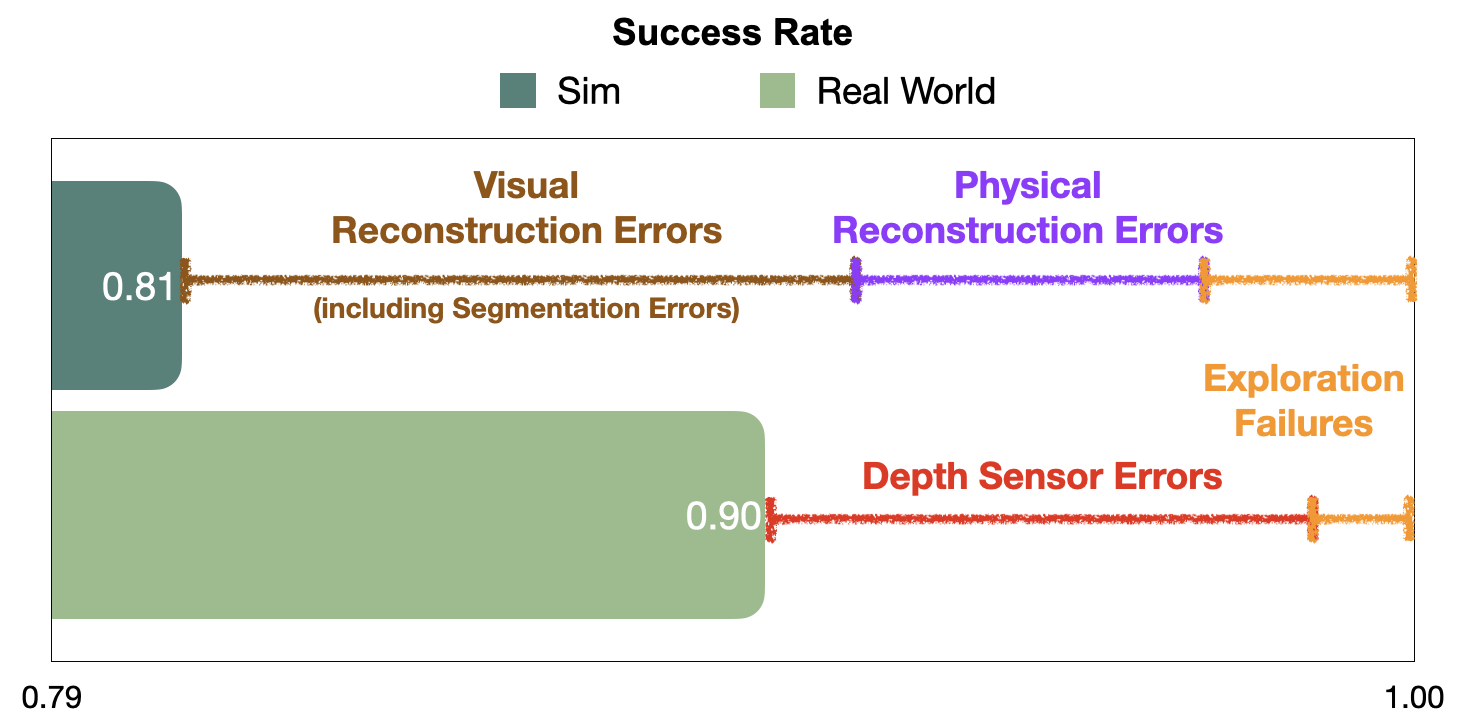
模块化方法真实世界成功率更高
在sim中有许多错误来自于reconstruction errors,现实中不会出现。Visual reconstruction errors represent 10% out of the total 19% episode failures, and physical reconstruction errors another 5%.
visual (imperfect RGB reconstruction that makes semantic segmentation harder in sim than reality) and physical (noisy navigation meshes that make planning harder in sim than reality)
现实世界中失败的原因主要来自于depth sensor errors(在sim中假设了完美的深度估计)
作者提出:
- (A) introduce realistic depth noise models for target deployment robots in sim benchmarks
- (B) improve the visual quality of sim 3D scans
- (C) improve the quality of sim navigation meshes

需要关注的文献:
[67-71]
[87]
[56,59,89]