3D-Aware Object Goal Navigation via Simultaneous Exploration and Identification
ObjectNav旨在使agent在unseen and unmapped scene下寻找一个特定类别的物体
Motivation
现有的工作主要通过端到端的reinforcement learning或者modular-based methods来解决这一问题
端到端的RL方法以图像序列作为输入,然后直接输出low-level的导航信息,但是受限于低的采样效率和较差的跨数据集泛化性。
modular-based methods通常包含:
- semantic scene mapping module,用于聚合RGBD观察和来自语义分割网络的输出以形成语义场景图(semantic scene map)
- RL-based goal policy module,这一模块将语义场景图(semantic scene map)作为输入,并学习在线更新目标位置
- local path planning module,用于驱动agent到达目标位置
现有的modular-based methods主要构建2D maps,scene graphs或neural fields来作为scene maps,这类构建方式都没有很好的利用环境的3D的空间信息。
使用3D场景表示可以自然的提高ObjectNav在3D场景中的表现,但是3D scene representation会为ObjectNav policy learning带来挑战:
- 构建和查询跨楼层场景的细粒度3D表示需要大量的计算成本,这会显著减慢RL的训练
- 3D场景表示相对2D来说,带来了更复杂和更高维的观察,导致较低的采样效率并阻碍navigation policy的学习
Related Work
GoalNav with Visual Sequences
直接利用RGBD序列输入的方法
GoalNav with Explicit Scene Representations
modular-based methods利用显式的场景表示作为机器人观察环境的代理(proxy)
scene graph
- [34] Learning hierarchical relationships for object-goal navigation 2020
- [56] Soon: Scenario oriented object navigation with graph-based exploration CVPR 2021
2D top-down map
- [14] Learning to map for active semantic goal navigation. ICLR 2022.
- [35] Poni: Potential functions for objectgoal navigation with interaction-free learning. CVPR 2022
Embodied AI tasks with 3D Scene Representation
具身智能任务用到大部分3D场景表示都是局部有限空间,e.g., near one table or drawer.
Under large scale environments, such as floor-level scenes in ObjectNav, the existing methods would suffer from complex 3D observation and large computational costs.
Methodology
任务设定
agent要求在未知环境中寻找特定类别的物体。agent会被随机初始化在某一位置,且agent是没有预先进行环境建图的,另外还会为agent提供一个特定类别的ID。在每个时间步t,agent都会接收无噪声的传感器读数,包括:
- egocentric RGB-D image
- 相对于起始状态的3-DoF pose (2D position and 1D orientation)
预测的动作空间是离散的,包括:
- move_forward
- turn_left
- turn_right
- stop
给定500步的有限时间预算,agent在到达指定类别的对象的1米之内时终止移动。
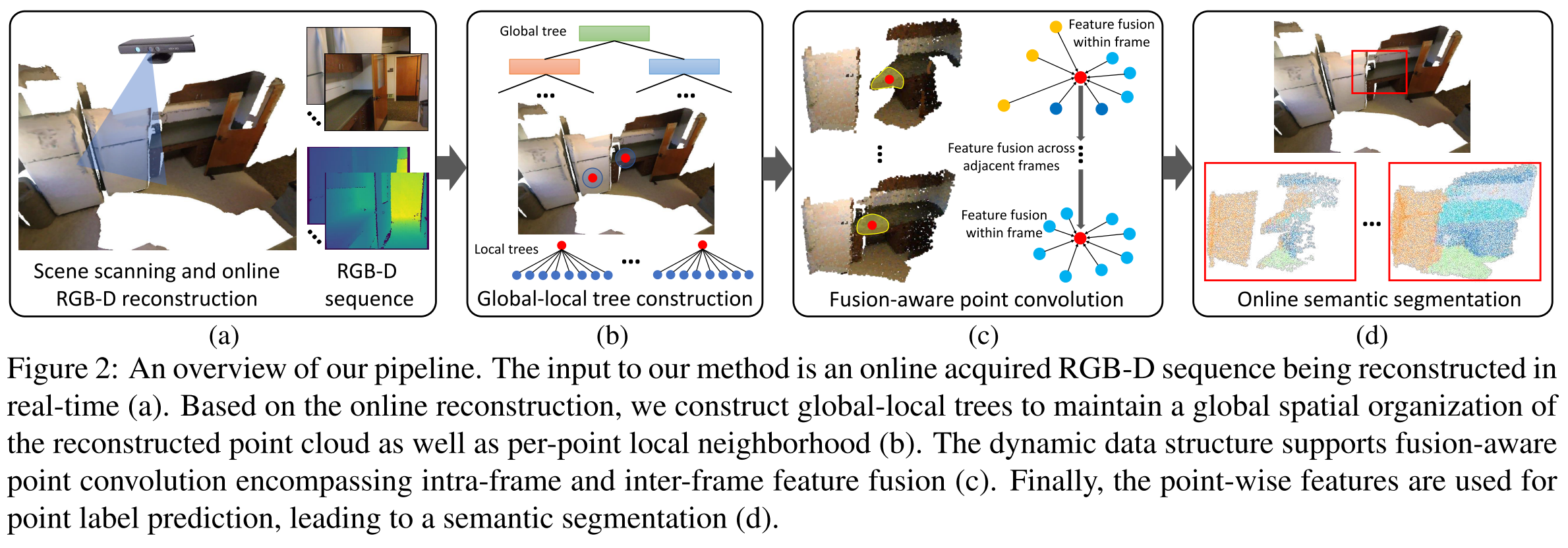
Method Overview
- 将RGBD+Pose作为输入,在线建立基于点的场景表示$\mathcal{M}_{3D}$, 然后进一步投影得到2D语义图$\mathcal{M}_{2D}$。
- 给定场景表示$\mathcal{M}_{3D}$和2D语义图$\mathcal{M}_{2D}$,simultaneously performs two complementary policies: the exploration policy and identification policy at a fixed time cycle of 25 steps
- the exploration policy预测了一个long-term离散的角点目标$g_e$,驱动智能体探索周围的环境
- the identification policy在每一步评估3D点$\mathcal{M}_{3D}$,当语义预测confident and consistent时,则输出目标对象goal $g_f$
- 当存在目标对象时则直接靠近目标对象,否则往角点目标靠近
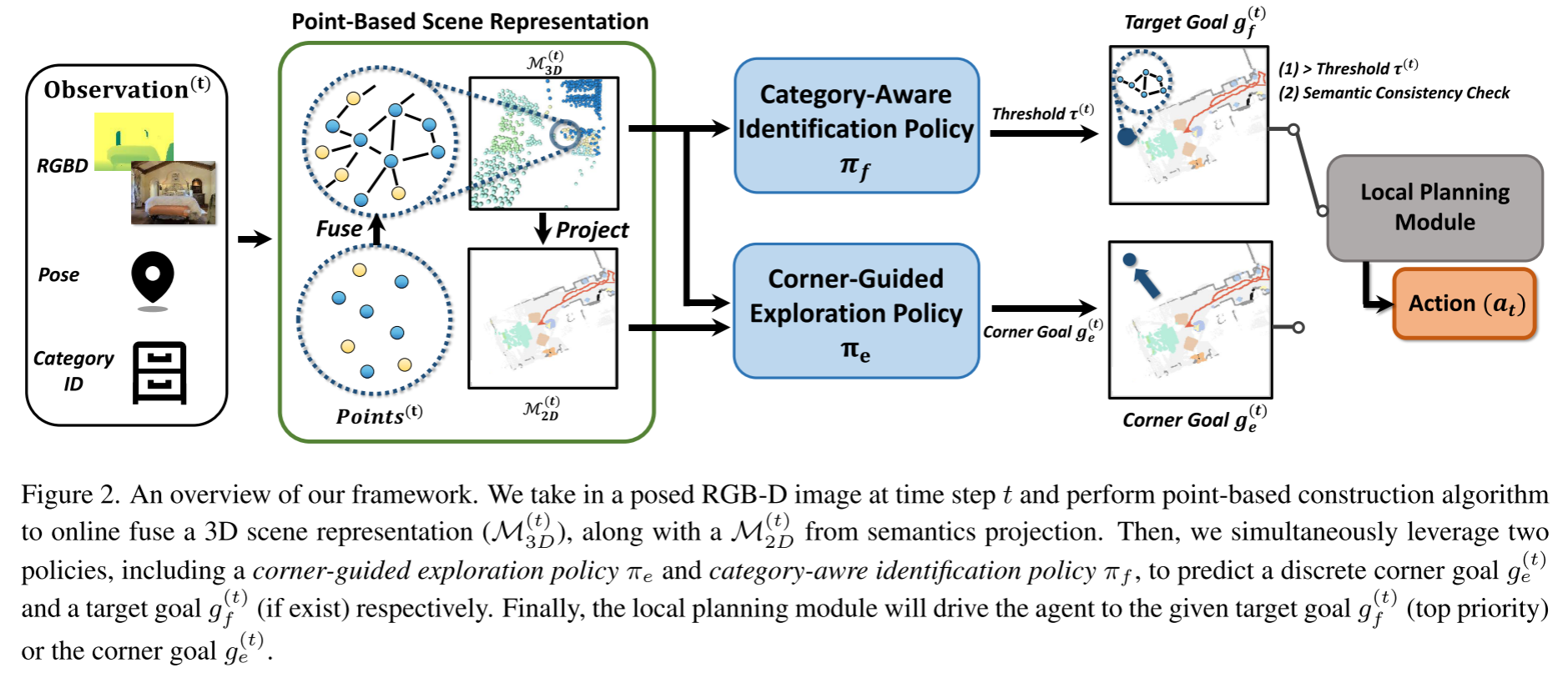
Navigation-Driven 3D Scene Construction
在导航的过程中,agent会不断接收新的观测结果,用于持续增量的构建一个细粒度的3D scene representation,将空间信息和语义信息整合到一起。作者扩展了基于点的在线构建算法以在线组织3D点,并进一步增强语义融合和一致性估计。
3D Scene Representation
在时间步$t$时,将3D场景用点云表示为$P^{(t)}=\left\{\left(P_{l}^{(t)}, P_{s}^{(t)}, P_{c}^{(t)}\right)\right\} \in \mathbb{R}^{N^{(t)} \times(M+4)} $
其中$N^{(t)}$代表点的个数,对于每个点$i$,$(M+4)$个通道可以拆分为:
- 3维的$P^{(t)}_{i,l}$,代表点位置
- $M$维的点语义表示$P^{(t)}_{i,s}$
- 1维的the point-wise spatial semantic consistency information $P^{(t)}_{i,c}$
Online 3D Point Fusion
在时间步t给定新的RGB图像$I^{(t)}_c$和深度图像$I_d^{(t)}$,agent可以通过它们的对应姿态将所有深度图像反向投影到3D世界空间中来获得点位置$P^{(t)}_{l}$,然后利用基于点的构造算法组织这些点。
有了位姿(朝向和位置),加上输入的RGB-D图像,就可以还原每个点在3D世界空间中的位置
CVPR2020 Fusion-aware point convolution for online semantic 3d scene segmentation