MM-OVOD
Multi-Modal Classifiers for Open-Vocabulary Object Detection
Motivation
直接用类别名加模板送入pretrained text encoder,然后用text embbeding代替传统检测器中的分类器的方法存在3个弊端:
- 可能存在语义歧义,且完全依赖预训练的文本编码器对于class name的内部表征,无法区分同一词汇表示的多种概念
- 有的情况下用户并不知道class name,反而exemplar images更容易获取
- 多模态输入时,exemplar images可以作为文本描述的很好的补充(比如复杂的图案,文本难以描述,但图像更直观)
Methodology
使用Detic作为baseline,centernet2作为检测器
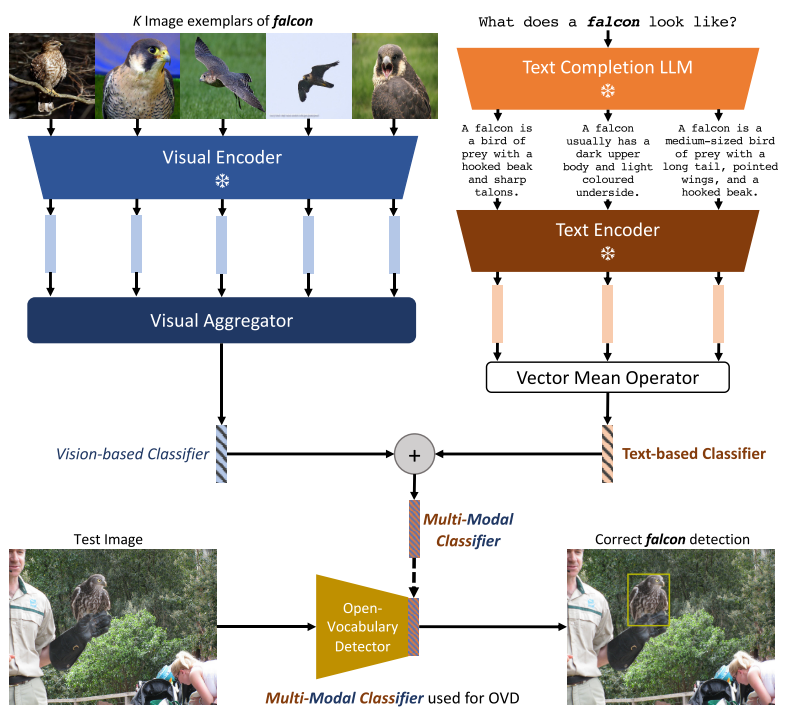
Text-based Classifiers from Language Descriptions
- 使用“What does a(n) {class name} look like?”作为prompt,利用GPT3对每个类别生成10个描述
- 送进CLIP的文本编码器提取文本特征
- 使用10个文本特征的平均特征作为这个类别的text-based classifier
- 在训练detector时,对于训练集里的类别,文本特征是提前抽好的,CLIP部分是冻结的
- 需要注意,文本端直接使用了平均特征,而没有像图像分支使用一个transformer结构的aggregator对特征进行聚合(实验发现这样做对OVOD的性能并没有提升)
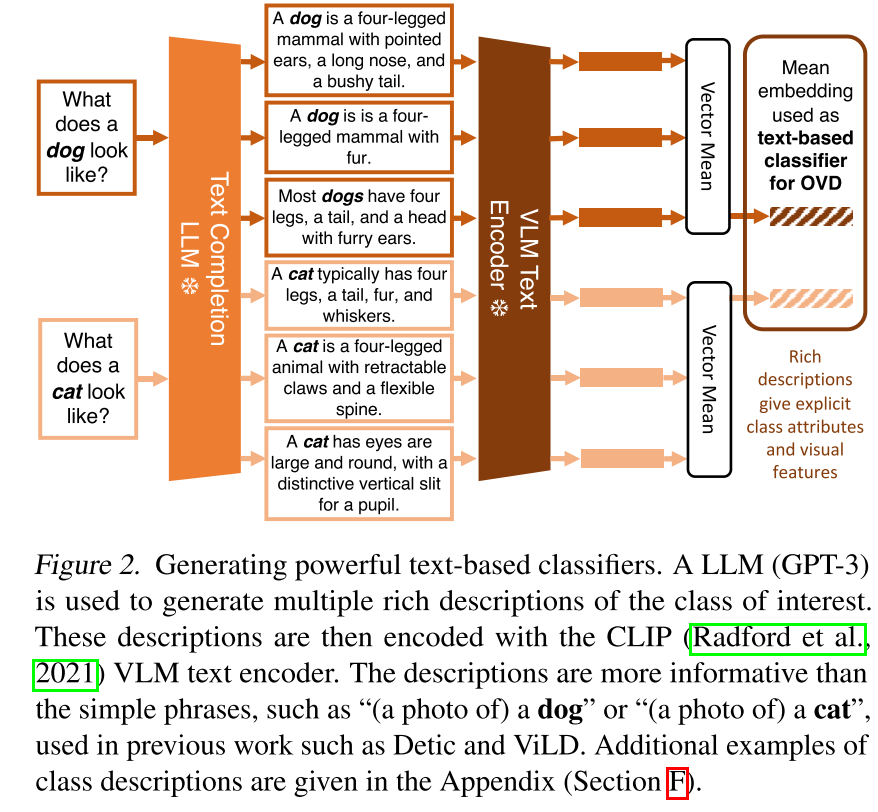
Vision-based Classifiers from Image Exemplars
- CLIP的视觉编码器用于提取图像特征,训练过程中保持冻结
- 使用transformer结构来作为visual aggregator对图像特征进行聚合,将CLS token作为vision-based classifier
- After applying some human effort, our IED(Image Exemplars Dictionary) contains at least 40 image exemplars for 1110 (92% of LVIS classes) and at least 10 image exemplars for all LVIS classes.
- The visual aggregator is trained offline i.e. it is not updated during detector training
- 使用对比学习对visual aggregator进行离线训练,最小化同类embedding距离,最大化不同类embedding距离
- 损失函数采用contrastive InfoNCE loss
- visual aggregator训练期间,对于类别c,在每次迭代时,由冻结CLIP图像编码器对两组不同的K个样本进行采样、增强和编码。这两个集合分别输入到visual aggregator,从类c的可学习[CLS]token输出2个embedding进行对比学习
- visual aggregator应该很好地泛化,并且不针对特定的下游OVOD词汇表进行训练,因此使用数据集用于图像分类ImageNet-21k-P,其中包含11 K类的11 M图像。
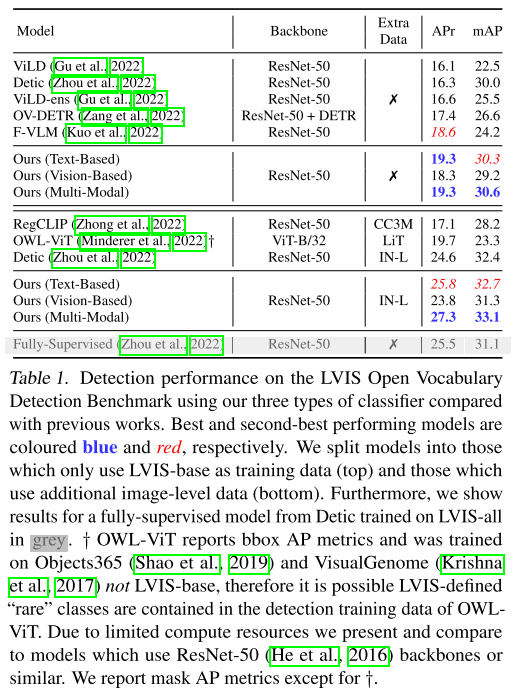
Constructing Classifiers via Multi-Modal Fusion
除以模,然后相加
we simply compute the vector sum of our l2-normalised text-based and vision-based classifiers
$\mathbf{w}_{\mathrm{MM}}^{c}=\frac{\mathbf{w}_{\mathrm{TEXT}}^{c}}{\left|\mathbf{w}_{\mathrm{TEXT}}^{c}\right|_{2}}+\frac{\mathbf{w}_{\mathrm{IMG}}^{c}}{\left|\mathbf{w}_{\mathrm{IMG}}^{c}\right|_{2}}$
Experiments
Datasets and Evaluation Protocol
LVIS数据集包含MS-COCO数据集中10万张图像中1203个类的类、边界框和mask标注