Object Goal Navigation using Goal-Oriented Semantic Exploration
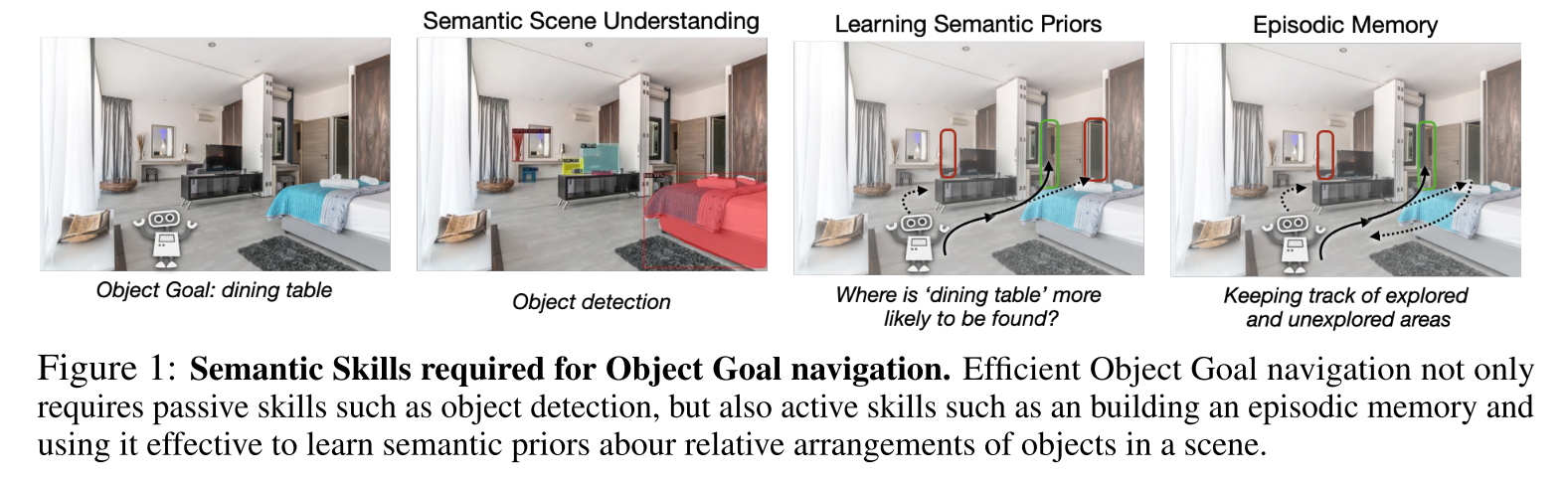
Motivation
object goal navigation:在未知环境中导航到一个给定物体类别的实例对象位置
假设要求agent在未知环境中导航到“dining table”,在语义理解方面,该任务不仅涉及对象检测,即“dining table”看起来像什么,但也要了解“dining table”在哪里更有可能被找到。
- long-term episodic memory可以使agent有效探索和跟踪环境
- 学习语义先验可以使agent使用episodic memory来决定接下来探索哪个区域,以便在最少的时间内找到目标对象。
Methodology
Object Goal Task Definition
寻物导航任务的目标是导航到给定对象类别的实例,例如“椅子”或“床”
agent初始化在环境中的随机位置,并接收目标对象类别($G$)作为输入
在每个时间步t, agent接收视觉观察$s_t$(第一人称视角的RGB图像和深度图像)和传感器姿态读数$x_t$,并采取导航动作$a_t$(前进,向左,向右,停止)
如果到目标对象的距离小于某个阈值$d_s(=1m)$,且agent采取停止动作时,the episode is considered successful(episode的最大时间步为500)
Overview
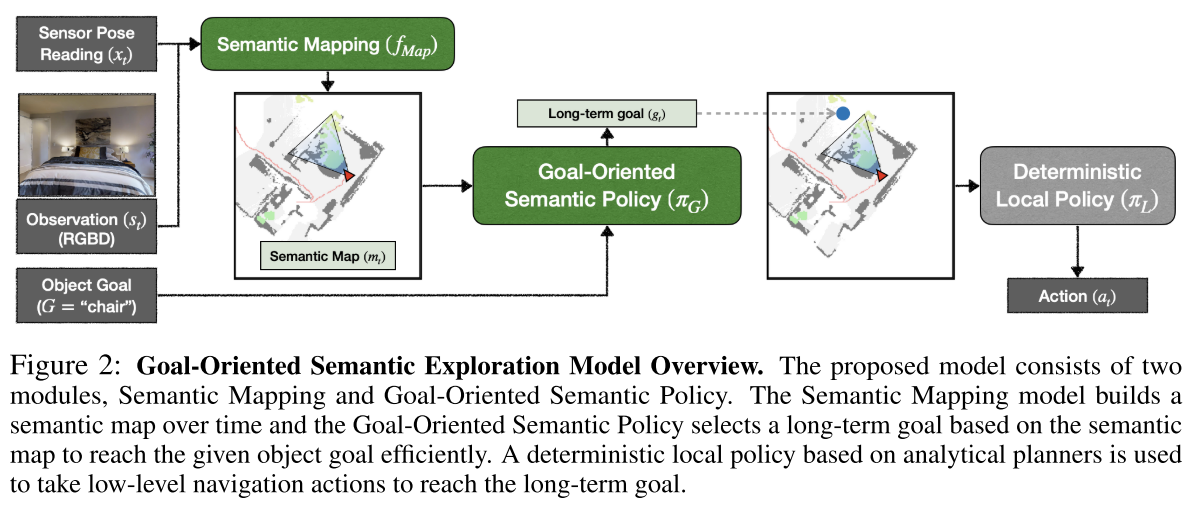
Goal-Oriented Semantic Exploration(SemExp)包含两个可学习模块Semantic Mapping and Goal-Oriented Semantic Policy
通过当前的传感器位姿(需要知道定位信息或通过里程计计算)与观测图像,Semantic Mapping构建出Top-down视角的语义地图,然后结合目标信息,训练一个Goal-Oriented Semantic Policy,在语义地图中进行长期目标的位置推测,然后Deterministic Local Policy执行局部规划导航(输出低级动作指令)到相应位置
Semantic Map Representation
SemExp会在内部维护一个语义地图$m_t$和agent姿态$x_t$
地图$m_t$是大小为$K\times M\times M$的矩阵,$M\times M$代表了地图大小,每个网格代表了真实世界$5cm\times 5cm$的区域,$K=C+2$,$C$代表语义类别的总数,前两个通道表示障碍物和已探索区域,其余通道各自表示对象类别。通道中的每个元素表示相应的位置是障碍物、探索过的还是包含相应类别的对象。地图会全零初始化为$m_0=[0]^{K\times M\times M}$
agent pose被初始化为$x_0=(M/2,M/2,0.0)$,即地图中心朝东
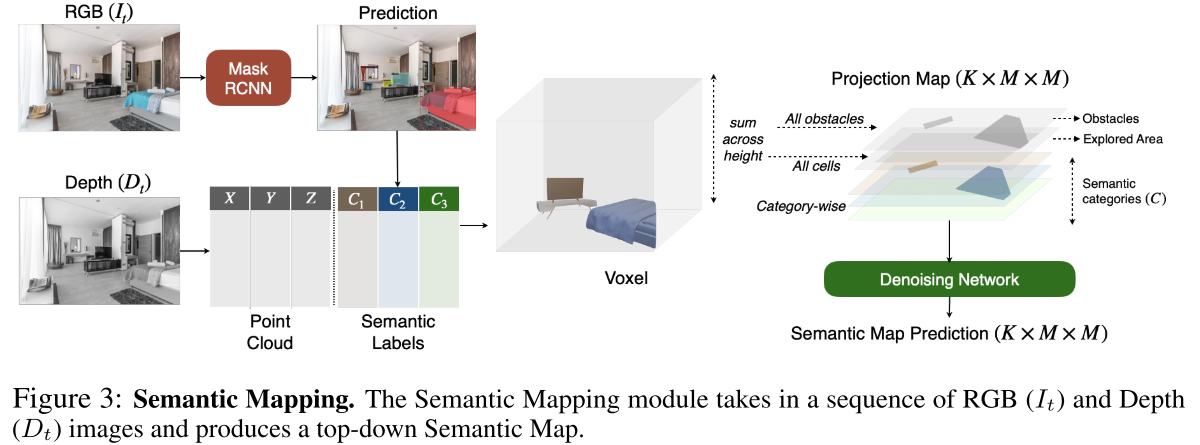
Semantic Mapping
- 使用预训练的Mask-RCNN检测到物体
- 将语义类别映射到点云中
- 使用可微分几何计算将点云中的每个点投影到3D空间中以获得voxel representation(带有语义的像素映射)
- 对所有障碍物、所有单元和每个类别的voxel representation的高度维度求和(3D to 2D,变为top-down 2D semantic map),得到了投影语义图(图中的Projection Map)的不同通道,不同类别的物体映射到不同的地图层中
- 经过Denoising Network过滤噪声,生成最后的语义地图
- 使用具有交叉熵损失来训练语义分割以及semantic map prediction
Goal-Oriented Semantic Policy
该模块的主要作用是根据地图预测最终的目标。若在探索过程中直接发现目标(semantic map中这一物体类别对应的层有非0元素),则直接将该目标作为导航点,进行规划导航;若当前没有观测到目标(semantic map中这一物体类别对应的层为全0),则根据目标的类别和当前的语义地图,推测最有可能找到的位置作为导航点。
推测目标可能的未知需要该策略网络可以学习物体间的相关布置关系(空间关系),是一种语义先验。本文使用神经网络来学习这种语义先验,将语义地图、智能体当前和过去的位置以及对象目标作为输入,并在自上而下的地图空间中预测一个长期目标
Goal-Oriented Semantic Policy通过RL进行训练,以减小与goal直接的距离作为奖励,进行最终目标位置的推测。注意这里推测的频率,并不是每运行一步进行一次推测,而是每经过25步进行一次推测,以减小采样复杂度,为探索留有更多时间。
Deterministic Local Policy
使用Fast Marching Method基于语义地图的obstacle channel规划出从当前未知到long-term goal的路径,在每个时间步都会更新地图,重新规划到long-term goal的路径。
Experiment
dataset
- Gibson,使用Gibson tiny set中train split用于训练,val split用于测试,因为test split是为在线评估提供的
- 没有用val set做超参调整
- 3d scene graph: A structure for unified semantics, 3d space, and camera中提供了Gibson tiny set的语义标注
- 训练和测试集包括总共86个场景(25个Gibson tiny和61个MP3D)和16个场景(5个Gibson tiny和11个MP3D)
- RGBD观察空间为$4\times640\times480$
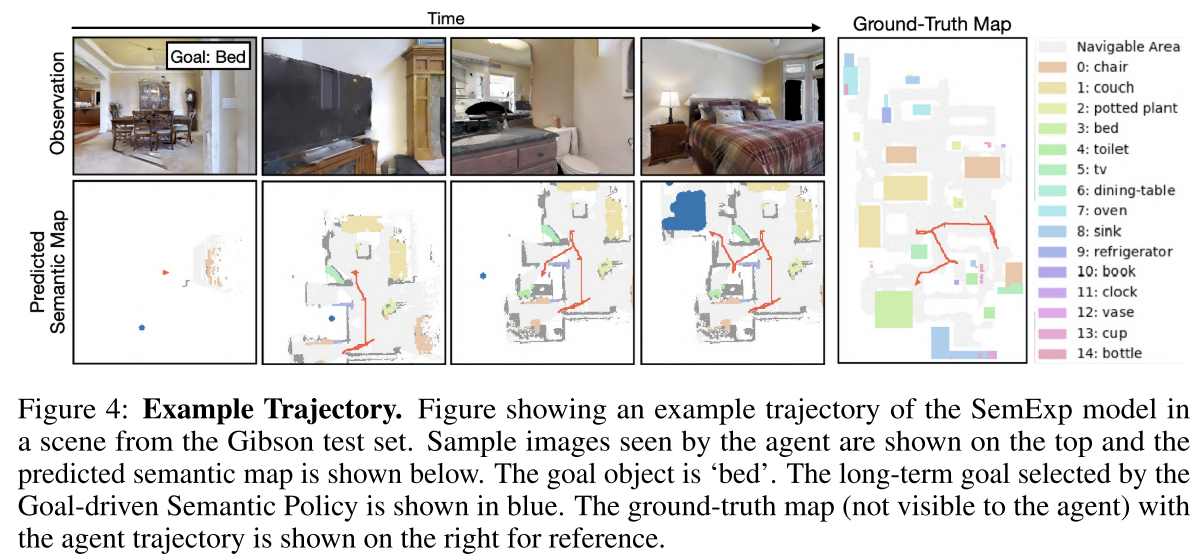
- 对于对象目标,使用Gibson 、MP3D和MS-COCO数据集之间常见的对象类别, 包括6个object goals类别:‘chair’, ‘couch’, ‘potted plant’, ‘bed’, ‘toilet’ and ‘tv’
- 虽然本文使用6个类别对象目标,但我们构建了一个包含15个类别的语义映射(如图4右侧所示),以编码更多信息来学习语义先验。
Architecture and Hyperparameter details
denoising network是一个5层的全卷积
We train the denoising network with the map-based loss on all 15 categories for Gibson frames and only 6 categories on MP3D frames.
Mask RCNN是冻结的
Matterport并不包含语义图中所有15个类别的标签
Goal-driven Semantic Policy是5层卷积和3层全连接构成的
In addition to the semantic map, we also pass the agent orientation and goal object category index as separate inputs to this Policy. They are processed by separate Embedding layers and added as an input to the fully-connected layers.
整个网络通过PPO算法进行训练,使用了86个并行线程,每个线程使用训练集中的一个场景。
Metrics
- Success
Success weighted by Path Length
DTS: Distance to Success,检测当到达最大迭代步数时的位置到目标的距离
Results
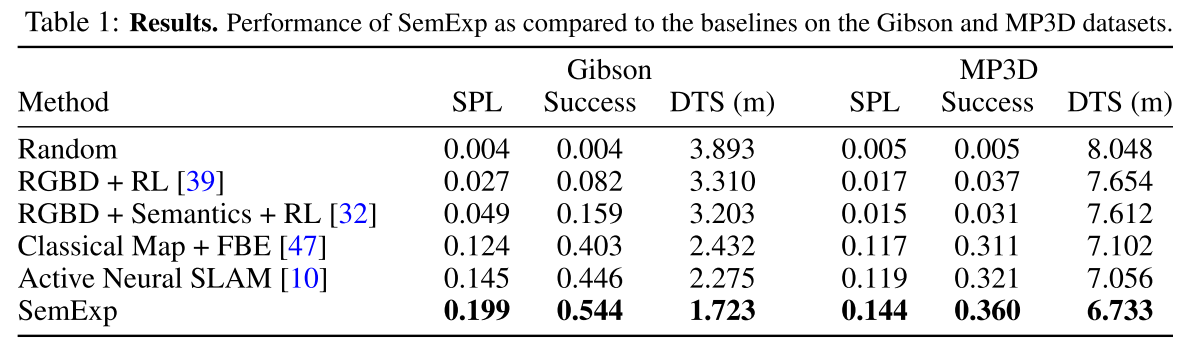
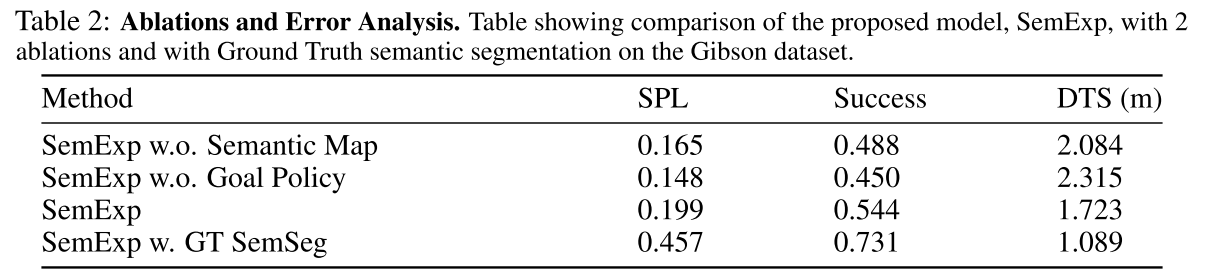
两个主要来源的错误,语义分割不准确和无法找到目标对象。
为了量化这两种错误模式的影响,作者使用GT语义分割来评估所提出的模型(参见SemExp w.表2中的GT SemSeg)使用habitat simulator中的“Semantic”传感器。73.1%对54.4%的成功率,这意味着通过更好的语义分割可以提高大约19%的性能。其余27%的事件大多是未找到目标对象的情况,这可以通过更好的语义探索来改善。
真实世界20次实验成功13次