Object-Centric Learning with Slot Attention
和DETR中的decoder非常接近
每个slot可以理解为一个特征向量,本文聚焦于如何从 CNN 的 feature map 中聚类/抽象出 set of slots
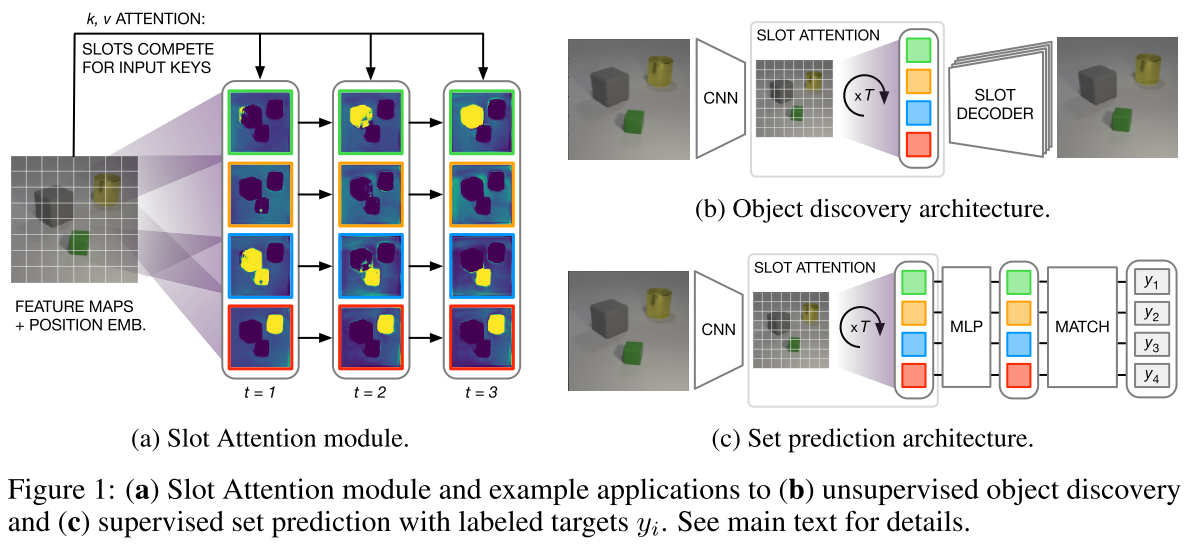

Slot Attention module模块本质上基本就是 multi-layer weight-sharing transformer decoder (去掉 self-attention)
inputs是$N\times D_{input}$的feature map
从一个高斯分布中采样出K个$D_{slots}$维的可学习参数,作为slots(可以理解为 DETR 的 object queries,K个slot)的初始化(可以理解为从VAE学到的高斯分布采样得到的)
- 这里的attn其实就是transformer decoder中的cross-attention
- 计算 updates,注意这里是 WeightedMean,而不是 transformer 里的 WeightedSum,但只是相差了常数系数
- 利用 GRU和updates 对之前的 slots 进行更新。 ablation中其实看到 GRU 的作用并不太明显
- 关键区别在于 attention 的归一化维度不同,slot attention 沿 slot 维度归一化,换言之对于每个 pixel,各 slot 对其 attention 之和为 1(即各 slot 互斥的瓜分各个 pixel,这也是论文中“the slots compete for input keys”所想表达的意思);而 transformer decoder 的 cross attention 沿 inputs 维度归一化,即每个 slot 对 inputs 中各 pixel 的 attention 之和为 1,slot 之间是互不相关的。
- 另外要注意的是,由于 slots 从高斯分布中采样,优化的其实只有 mu, sigma 两个参数,而非 DETR 里直接优化。每次调用 Slot Attention module 时,slots 都要重新采样,而不是从一而终的用固定的 object queries。
1 | # simplified slot attention module |
1 | # simplifed transformer decoder layer |
Local Slot Attention for Vision-and-Language Navigation
Motivation
当前的基于transformer的解决VLN的模型中存在两个问题:
- 模型独立地处理每个视图,而不整体的考虑
- self-attention中没有对空间进行限制,可能引入额外噪声,在大范围内进行self-attention的计算代价较大
PREVALENT中一个视点的所有36个视图在每个时间步彼此关注,以整合来自整个场景的信息。这不仅在计算上是昂贵的,而且违背常识,因为具有大空间距离的区域通常是不相关的。来自远程视图的这种信息可能成为干扰导航决策的噪声。
在Recurrent VLN-Bert中,仅关注候选视图。这减少了内存的使用,但是也将agent的感受野限制在了孤立的candidate view中,视觉线索可能在candidate view中被裁剪或模糊,并且不能对应于语言指令。
Methodology
The state of navigation is composed of the history of visual perceptions and the embedding of language instructions.
The state of the agent includes its pose, which is the embedding of its current heading and elevation
Panoramic Action Space
全景动作空间:每个viewpoint被表示为由3 × 12views组成的全景图,每个视图对应于特定的航向角和俯仰角,FOV(视角范围)为60度,分辨率为$640\times 480$,航向角范围为0到360度,间隔为30度,俯仰角为0、30或-30度。
candidate view:在36个views中,有些view是朝向另外的viewpoint的,被称为candidate view
- 本文利用ResNet-152 model pre-trained on the Place365 dataset来对view预提取特征,每个view被编码为2048维的tensor
- 为了表示每个view的位置特征,采用重复32次的$(sin(𝜓𝑖),cos(𝜓𝑖),sin(𝜔𝑖),cos(𝜔𝑖))$的四元数作为第i个候选视图的角度特征,其中𝜓𝑖,𝜔𝑖分别表示其相对于agent的当前朝向的航向角和俯仰角,这一角度特征的维度为128,角度特征将和图像特征进行拼接,维度为2176,作为view feature,最后得到属于一个viewpoint的feature map shape为(36, 2176)
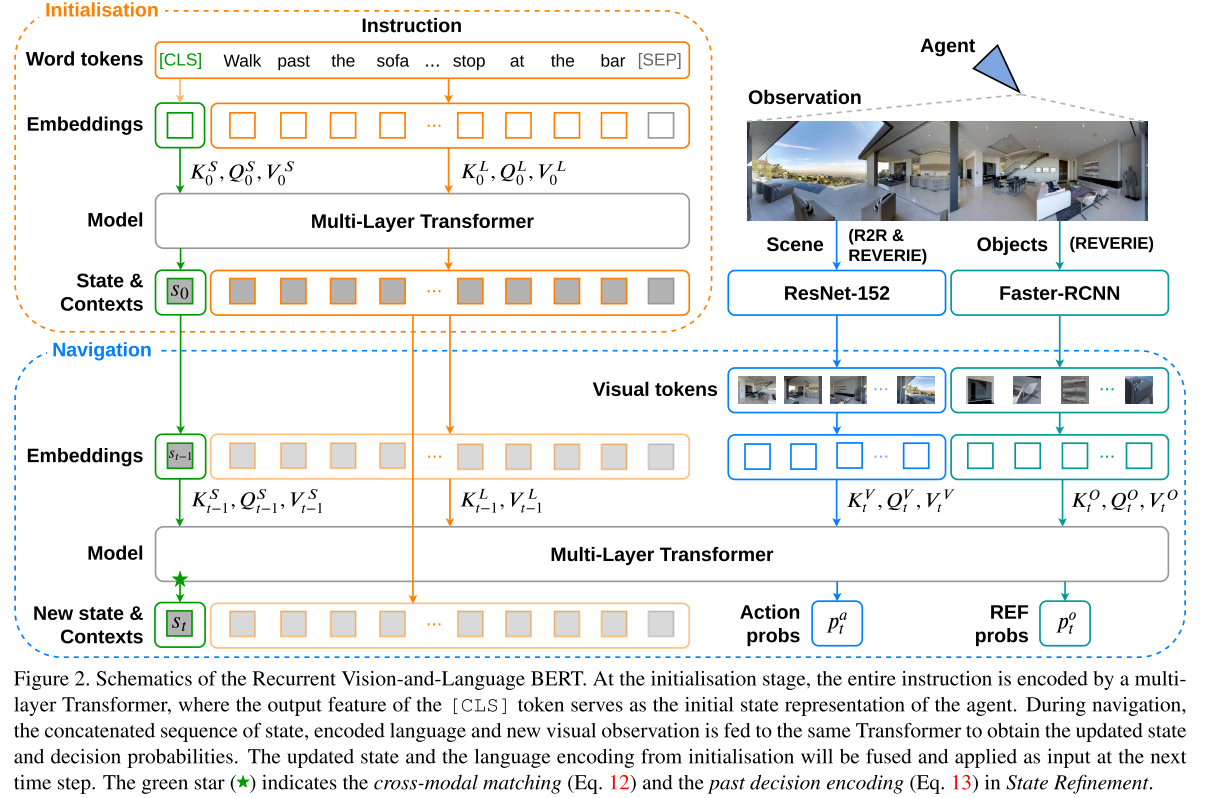
Revisiting Recurrent VLN-Bert
- 通过BERT对language instructions进行编码,并把[CLS] token($L_{cls}$)作为initial navigation state, [CLS] token会在导航过程中不断更新,其他token(表示为$L_{/cls}$)固定不变
- 在action selection阶段,multi-layer cross-attention module中将view features和state embedding ([CLS] token)拼接起来作为queries, instruction embedding的固定token($L_{/cls}$)作为context(keys and values), 然后计算cross-attention
$\mathrm{L}_{c l s}^{X}, \mathrm{~V}_{t}^{X}=\text { Attention }_{\text {cross }}\left(\left[\mathrm{L}_{c l s} ; \mathrm{V}_{t}\right], \mathrm{L}_{/ c l s}\right)$
cross-attention module的输出被分为两部分作为[$\mathrm{L}_{c l s}^{X}$; $\mathrm{~V}_{t}^{X}$]。$\mathrm{L}_{c l s}^{X}$表示[CLS]token的embedding(即state embedding),并且$\mathrm{~V}_{t}^{X}$表示视觉输入的embedding。
- multi-layer self-attention module整合candidate views的信息到[CLS] token中,最后一层self-attention layer的[CLS] token对所有candidate views的attention weights就是action selection score,agent选择得分最高的candidate view移动或停止
- 然后计算language embedding$\mathrm{L}_{/c l s}^{X}$和visual embedding点乘获得多模态特征,再经过linear projection得到下一个时间步的navigation state(即用这一state替代$L_{cls}$,完成状态更新)
Slot Attention
将shape为(36,2176)的feature map(见Panoramic Action Space中的定义)作为Slot Attention mudule的input keys$I_{key}$
由于候选视图表示可导航方向,因此它们应该是导航任务的viewpoint的最显著部分,利用这一先验知识,使用candidate views来初始化slots,然后slots作为slot attention module的input queries $I_{query}$
对于slots来说,只需要更新visual information而不需要更新角度特征,所以将angle feature从feature map中去除,作为input values $I_{value}$

Local Attention Mask
如果slot(candidate view)更靠近上下文视图,希望注意力权重更高,如果slot和上下文视图距离较远,则希望注意力权重更低。因此作者采用了一个简单的local attention mask来限制注意力的范围,使slot attention更稳定。
- 36个views被视作$3\times 12$的网格
- 举例来说,通过应用$3\times 3$局部掩模,candidate view仅关注周围的$3\times 3$区域。

Experiment
Datasets
The R2R dataset contains 10,567 panoramic views of 90 real-world in-door environments and 7,189 trajectories, each one is attached with three instructions written in natural language
Metrics
- Navigation Error(NE), the shortest path length between the agent’s final position and the goal location.
- Success Rate (SR), the percentage of the agent successfully stops within 3 meters of the goal location.
- Oracle Success Rate (OSR), as long as the agent is ever within 3 meters ofthe goal location in its trajectory, it is considered successful.
- Success rate weighted by Path Length (SPL), trades-off success rate against trajectory length, higher SPL means more efficient navigation and less exploration.
single NVIDIA 2080 Ti