Meta Omnium
Meta Omnium是一个跨多个视觉任务的数据集,包括识别,关键点定位,语义分割和回归。提供统一框架,用于以一致的方式在广泛的视觉应用中评估meta-learners
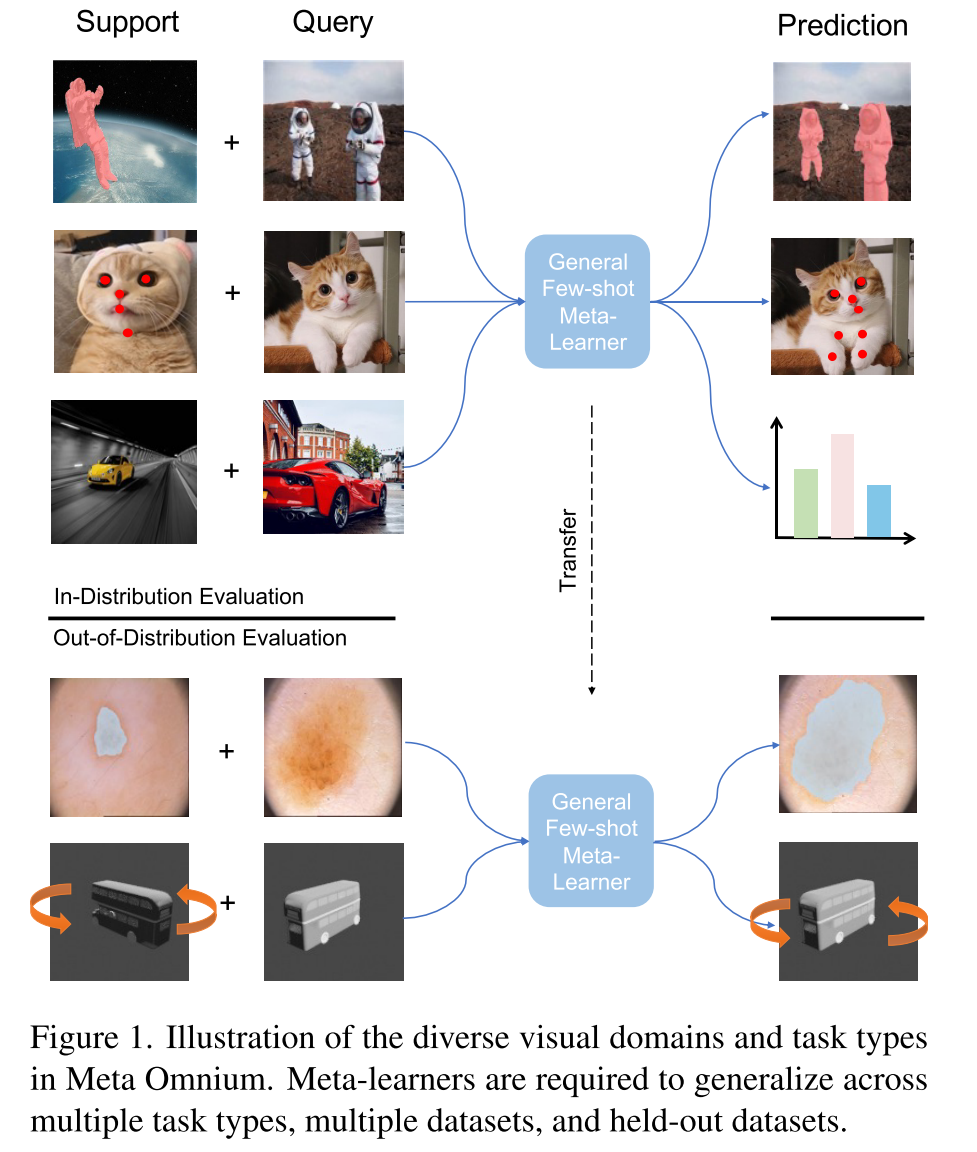
- 现有的benchmarks仅测试meta-learners在分类或密集预测等任务中学习的能力。Meta Omnium独特地测试了元学习者跨多种任务类型学习的能力。
- 涵盖多个视觉领域(从自然图像到医学和工业图像)
- 提供了全面评估分布内和分布外泛化的能力
- 明确的超参数调整和模型选择协议,以促进元学习算法之间的公平比较
- 具有适中的计算成本,使其可用于资源适度的大学和大型机构的研究
传统的within-task meta-learning benchmarks更多地依赖于共同的表征学习而不是learning-to-learn,Meta Omnium更好地测试了learning-to-learn的能力,因为组成的任务需要更多样化的表征
baseline具有最小的task-specific decoders,评估learning-to-learn的能力,而不是融入先验
Data Splits and Tasks
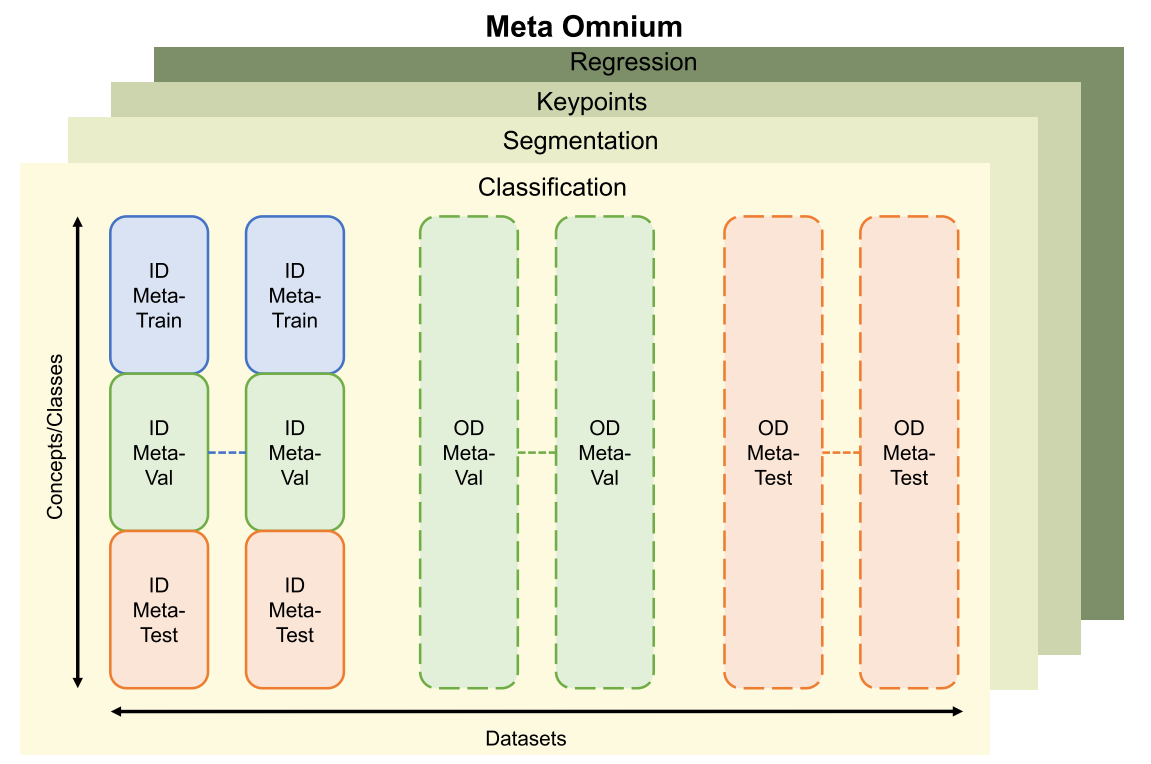
对于每个主要任务(分类,分割,关键点定位),数据集都被分为seen datasets(用于meta-training),unseen datasets(用于out-of-domain meta-validation and meta-testing)。
seen datasets按照类别将其划分为meta-train/val/test
unseen不划分,数据集中所有类别都会被用于validation和testing
- 每个任务对应多个数据集,实线框代表seen datasets,虚线框代表unseen datasets
- The seen (ID) datasets are divided class-wise into meta-train/meta-val/meta-test splits.
- The unseen datasets are held out for out-of-distribution (OD) evaluation.
- Meta-training is conducted on the ID-meta-train split of the seen datasets (blue).
- Models are validated on ID validation class splits, or OOD validation datasets (green).
- Results are reported on the ID test class splits and OOD test datasets (orange).
- 另外还保留了regression task来评估新任务上的泛化性,regression任务中的数据集在meta-training时并没有被使用
两种训练范式:
- Single-task meta-learning:在一个特定task family内进行训练和测试,评估meta-learning的效果
- Multi-task meta-learning:在所有的task families上进行训练,评估meta-learning的效果
两种评估方式:
- Within-distribution generalization (ID): How well do meta-learners generalize to novel test concepts within
the seen datasets? - Out-distribution generalization (OOD): How well do meta-learners generalize to novel concepts in unseen datasets?
Datasets and Metrics
Classification
选择Meta-Album中的10个datasets,每个数据集包含19-706类,图片大小为$128 \times128$,每个类别有40张图像。其中3个数据集被保留用于out-of-distribution meta-validation,4个数据集用于out-of-distribution meta-test
Segmentation
- 将FSS1000用于in-distribution,包含10000张图像,1000个类
- FSS1000结合VizWiz用于OOD meta-validation,包含862张图像,22个类
- modified Pascal5i(包含7242张图像,6个类)和医学图像数据集PH2(包含200张图像,3个类)用于meta-testing
- 所有图像都被resize为$224\times 224$
- 在进行few-shot learning时排除了与FSS1000数据集类别重叠的类,因此所有数据集之间没有重叠的类
Keypoints
- animal-pose for in-distribution,包含5个动物类别,超过4k张图像中的6k个实例,每个动物都被从原图像中crop出来。cat和dog用于训练,horse和sheep用于in-domain validation,cow用于in-domain testing
- synthetic animal-pose for OOD meta-validation,用从随机背景上的各种视点和照明渲染的动物CAD模型生成合成图像。在最终的数据集中只保留马和老虎类别。
- MPII human-pose for OOD meta-testing,包括约40k人超过25k张带有人体关节点标注的图像
- 所有图像都被resize到$128\times128$
Regression
ShapeNet1D,预测航向角,总共包含30个类别,我们从测试集中保留了3个类别
ShapeNet2D,具有航向角和俯仰角的2D旋转,ShapeNet2D的测试集总共包含300个类别,每个类别30张图像
Distractor,预测目标物体位置,它总共包含12个类别,测试集有2个类别,每个类别包含1000个对象,每个对象有36个图像
Pascal1D,预测航向角,整个Pascal1D包含来自10个类别的65个对象。测试集包含15个对象,每个对象具有100个图像
所有图像都被resize到$128\times128$