Learning to Explore using Active Neural SLAM
Motivation
未知环境中导航的核心问题是探索,即,如何有效地访问尽可能多的环境,最大化覆盖环境范围以给予在未知环境中找到目标的机会,或在有限的时间预算上对环境进行有效的预建图。
为了在未知环境中进行高效主动探索,agent需要知道:
- where it has been before (i.e. Mapping)
- where it is now (i.e. Pose Estimation)
- where it needs to go (i.e. Planning)
如何训练自主探索的agents?
- 一种方法是使用端到端的深度强化学习,但是使用端到端的方式隐式的学习mapping,pose estimation和planning是昂贵的,且样本效率低下,因此强化学习的方法不适用于large environment中
本文提出的方法通过learning的方法来学习:
室内环境的结构特点
对状态估计误差的鲁棒性;
灵活的输入模态
Task Setup
探索任务的目标是在固定时间预算内最大化探索覆盖范围,覆盖范围定义为地图中已知可穿越的总面积。
使用Gibson和Matterport datasets
以往的工作假设了简单的agent motion,比如假设agent在网格上动作,且转向都为90度,或者虽然是细粒度控制,但是假设了motion和pose是没有噪声的。因此本文收集了真实世界的运动和传感器数据,以在仿真中建立更真实的agent motion and sensor noise models
Actuation and Sensor Noise Model
用$(x,y,o)$来表示agent pose,其中$x,y$代表位置坐标,以米为单位,$o$代表agent的朝向,以弧度为单位,从$x$轴逆时针测量。
假设agent一开始的位置为$p_0=(0,0,0)$,agent要执行动作$a_t$,每个动作是通过向robot发出控制指令来完成的,假设对应的控制指令为$\Delta u_a=(x_A,y_a,o_a)$,执行完动作后的实际agent pose为$p_1=(x^{\star},y^{\star},o^{\star})$, The actuation noise(动作噪声)代表了动作之后的实际pose $p_1$和预期的pose $(p_0+\Delta u)$之间的差:
$\epsilon_{a c t}=p_{1}-\left(p_{0}+\Delta u\right)=\left(x^{\star}-x_{a}, y^{\star}-y_{a}, o^{\star}-o_{a}\right)$
移动机器人通常配备估计姿态的传感器,假设传感器估计的动作后的姿态为$p_1’=(x’,y’,o’)$, The sensor noise定义为传感器估计的姿态和实际姿态的差:
$\epsilon_{s e n}=p_{1}^{\prime}-p_{1}=\left(x^{\prime}-x^{\star}, y^{\prime}-y^{\star}, o^{\prime}-o^{\star}\right)$
使用三个默认导航操作:
- 向前:向前移动25cm,$u_{Forward}=(0.25,0,0)$
- 右转:就地顺时针旋转10度, $u_{right}=(0,0,-10*\pi /180)$
- 左转:就地逆时针旋转10度, $u_{left}=(0,0,10*\pi /180)$
实际执行时,向前的平移操作会有旋转动作噪声,而旋转会有平移动作噪声
对于每个动作$a$,我们针对动作噪声和传感器噪声拟合单独的混合高斯模型,3种动作,每种动作对应2种噪声,总共6个混合高斯模型。这些高斯混合模型中的每个分量是3个变量x、y和o的多变量高斯。对于每个模型,我们收集了600个数据点。使用交叉验证选择每个高斯混合模型中的分量的数量。
Methodology
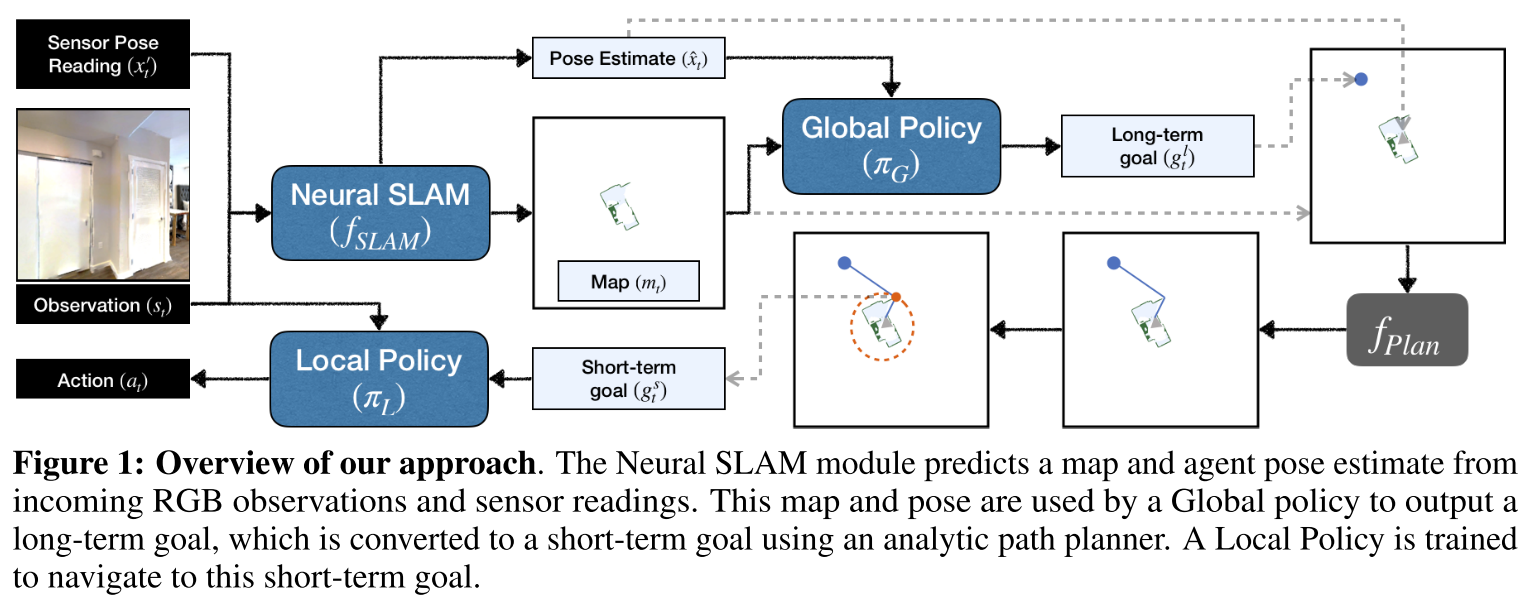
由3个部分组成:
- Neural SLAM Module,根据当前的观察和先前的预测来预测环境地图和agent pose
- 使用卷积对visual obervation进行encode,然后再反卷积decode出map
- 学习structured map和pose representations
- 通过有监督学习进行训练,使用binary cross-entropy loss for map prediction and mean-squared loss for pose prediction.
- Global Policy,使用预测的地图和agent pose来生成long-term goal,并使用当前地图上的分析路径规划(如 Dijkstra 或 A*)将其转换为short-term goal
- 使用CNN产生long-term goal
- 在course time-scale运行,每25步运行一次
- 使用强化学习进行训练,将探索区域的增加作为reward
- Local Policy,根据当前观察输出导航操作以实现short-term goal
- CNN+GRU
- 在fine time-scale运行,每步都输出一个low-level navigation action
- 使用二元交叉熵损失+imitation learning进行训练
Map Representation
The Active Neural SLAM model在内部维护空间地图$m_t$和agent姿态$x_t$.
spatial map $m_t$是一个$2\times M \times M$的矩阵,$M\times M$代表地图大小,这张空间地图中的每个元素对应于物理世界中一个大小为$25cm^2(5cm × 5cm)$的单元,第一通道中的每个元素表示在相应位置处的障碍物的概率,第二通道中的每个元素表示该位置被探索的概率,当已知某一cell是自由空间或障碍物时,认为这一cell被探索,空间地图被全零初始化为$m_0=[0]^{2\times M \times M}$
$x_t$代表了时间步t时agent的pose(位置和朝向),agent总是被初始化在地图中心,面朝东方(x轴正方向),即$x_0=(M/2,M/2,0.0)$
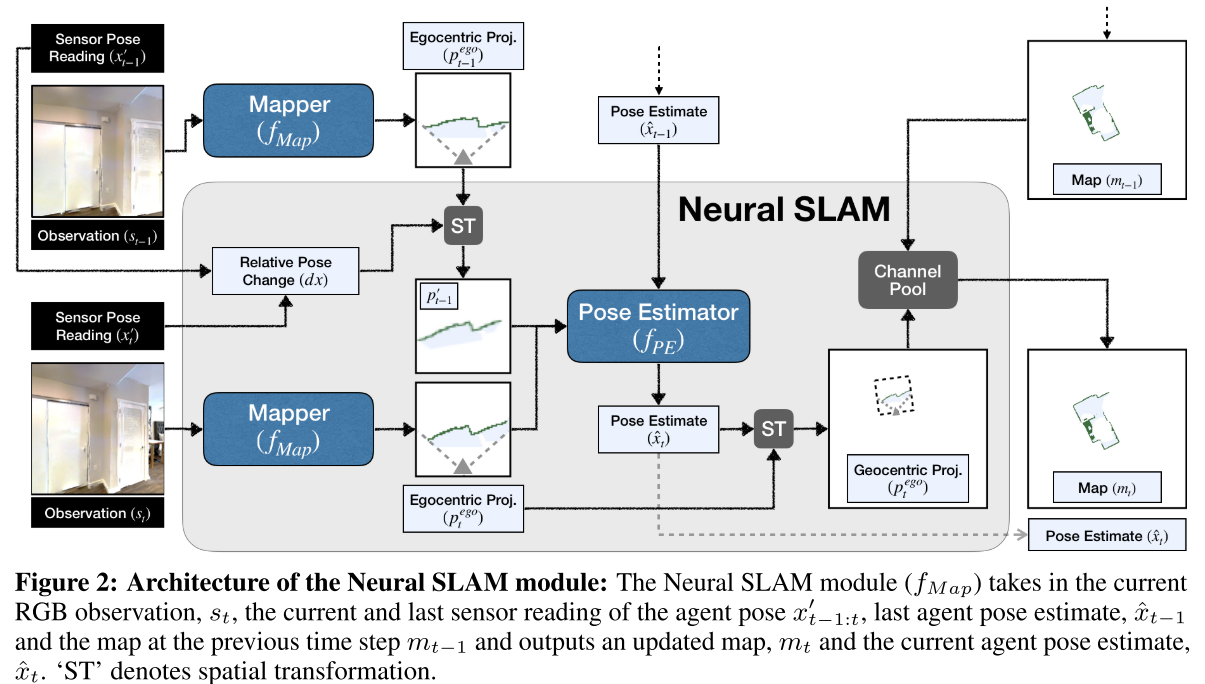
Neural SLAM Module
Neural SLAM Module($f_{SLAM}$)产生自由空间地图(free space maps)
输入:
- RGB图像$s_t$
- 最近两次传感器读数$x’_{t-1:t}$
- 上次估计的位姿$\hat{x}_{t-1}$
- 上次估计的地图$m_{t-1}$
输出:
- 当前估计的位姿$\hat{x}_t$
- 当前估计的地图$m_t$
即$m_{t}, \hat{x}_{t}=f_{S L A M}\left(s_{t}, x_{t-1: t}^{\prime}, \hat{x}_{t-1}, m_{t-1} \mid \theta_{S}\right)$, 其中$\theta_{S}$代表Neural SLAM Module的可学习参数,包含两个组件:
- Mapper($f_{Map}$)输出egocentric top-down 2D spatial map $p_{t}^{e g o} \in[0,1]^{2 \times V \times V}$,$V$是视觉范围,预测当前观测中的障碍物和已探测的区域。
- Pose Estimator($f_{PE}$)基于过去的pose estimation($\hat{x}_{t−1}$)和最近两个egocentric map predictions ($p^{ego}_{t−1:t}$)来预测agent pose($\hat{x}_t$), 本质上是比较当前egocentric map prediction与上一个egocentric map prediction,以预测两个地图之间的姿态变化
基于Pose Estimator给出的姿态估计,将Mapper输出的egocentric map转换为geocentric map,然后与先前的空间地图($m_{t-1}$)聚合以获得当前地图($m_t$)
Global Policy
Global Policy的输入是 $h_{t} \in[0,1]^{4 \times M \times M}$,其中前两个通道代表Neural SLAM Module输出的空间地图$m_t$, 第三个通道是Neural SLAM Module输出的agent位置(这一通道的$M \times M$的地图上,agent位置为1,其他为0),第四个通道代表已访问过的位置(历史上agent经过的所有位置置1)
$\begin{array}{ll}
h_{t}[c, i, j]=m_{t}[c, i, j] & \forall c \in\{0,1\} \\
h_{t}[2, i, j]=1 & \text { if } i=\hat{x}_{t}[0] \text { and } j=\hat{x}_{t}[1] \\
h_{t}[3, i, j]=1 & \text { if }(i, j) \in\left[\left(\hat{x}_{k}[0], \hat{x}_{k}[1]\right)\right]_{k \in\{0,1, \ldots, t\}}
\end{array}$
$h_t$经过两个变换后再送进Global Policy
- 从$h_t$中采样得到agent周围大小为$4\times G\times G$的窗口
- 对$h_t$进行max pooling,得到$4\times G\times G$的特征图
这两种变换的结果都被叠加形成一个大小为8 ×G×G的张量,并作为输入传递给Global Policy model
Global Policy model使用卷积神经网络来预测long-term goal($g_t^l$属于$G\times G$的空间),$g_t^l=\pi_G(h_t|\theta_G)$, 其中$\theta_G$代表Global Policy model的可学习参数
Planner
输入为:
- long-term goal ($g^l_t$)
- spatial obstacle map($m_t$)
- agent pose estimate($\hat{x}_t$)
输出:
- short-term goal($g^s_t$)
使用Fast Marching Method (Sethian, 1996)得到当前位置到长期目标位置的最短路径。未探索的区域被视为planning的自由空间。然后将计划路径上距离智能体0.25m内的最远点作为short-term goal
Local Policy
输入:
- current RGB observation ($s_t$)
- the short-term goal ($g^s_t$ )
输出:
- navigational action $a_{t}=\pi_{L}\left(s_{t}, g_{t}^{s} \mid \theta_{L}\right)$, $\theta_{L}$代表Local Policy的可学习参数
short-term goal坐标在传递到Local Policy之前被转换为相对于agent位置的距离和角度,Local Policy利用recurrent neural
network实现。
Experiment
本文基于 Habitat 模拟器,在Gibson和Matterport(MP3D)数据集上进行实验。Gibson 主要由办公室场景组成,而MP3D主要由家庭场景组成。使用Gibson 作为训练测试集,MP3D做为泛化测试集。Gibson 测试集是不公开的,在线测试。
观察空间由大小为$3\times 128\times 128$的RGB图像和大小为$3\times 1$的基础里程计传感器读数组成,里程计的$3\times 1$的读数表示agent的x-y坐标和方向的变化。
动作空间由三个动作组成:前进、左转、右转。
目标是固定时间内最大化覆盖范围。覆盖范围是地图上已知可穿越的总面积。
traversable point:在代理的视野范围内并且距离小于3.2米点就是已知的可穿越的点。
评估指标: 覆盖范围的面积和覆盖范围的百分比
为了分析所有模型在场景大小方面的性能,将Gibson验证集分为两部分,一个由10个场景组成的小集合,可探索区域从16 $m^2$到36$m^2$,一个由4个场景组成的大集合,可探索区域从55 $m^2$到100$m^2$。