KERM
KERM: Knowledge Enhanced Reasoning for Vision-and-Language Navigation
Motivation
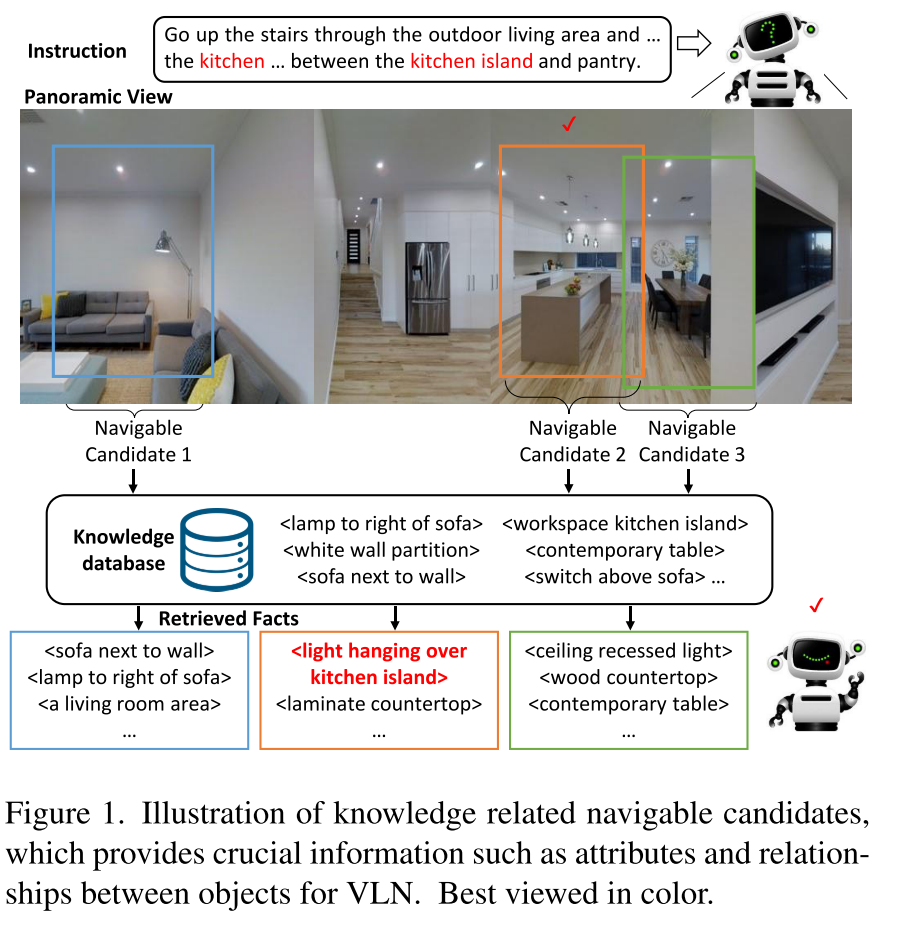
- 知识可以提供与视觉内容互补的关键信息,比如对象和关系的抽象信息,这样的信息对于对齐视角图像中的视觉对象是必不可少的。比如图1中的Navigable Candidate2 和 3,agent可以根据知识< light hanging over kitchen island>来判断出应该去2
- 知识可以提高agent的泛化能力,指令和navigable candidate是在有限的可见环境中学习的,利用知识有利于迁移到未见过的环境
- 知识增加了VLN模型的能力。随着丰富的概念信息被注入到VLN模型中,许多概念之间的相关性被学习。学习到的相关性有利于视觉和语言对齐,特别是对于具有高级指令的任务
KERM将以区域为中心的知识与导航视图融合,为每一个navigable candidate检索事实(语言描述的知识),作为视觉内容的补充,以获得更好的action prediction
Methodology
本方法是在离散导航的仿真环境(REVERIE, R2R, SOON)中实现的,仿真环境中提供了navigation connectivity graph, 表示为$\mathcal{G}=\{\mathcal{V}, \mathcal{E}\}$,其中$\mathcal{V}$代表navigable nodes,$\mathcal{E}$代表边。给定自然语言指令,agent探索环境最终到达目标位置。在每一个导航步t,agent都会在当前位置节点观察到一个全景视图,每个全景视图由36张单视角图(及对应的朝向)组成。
Overview
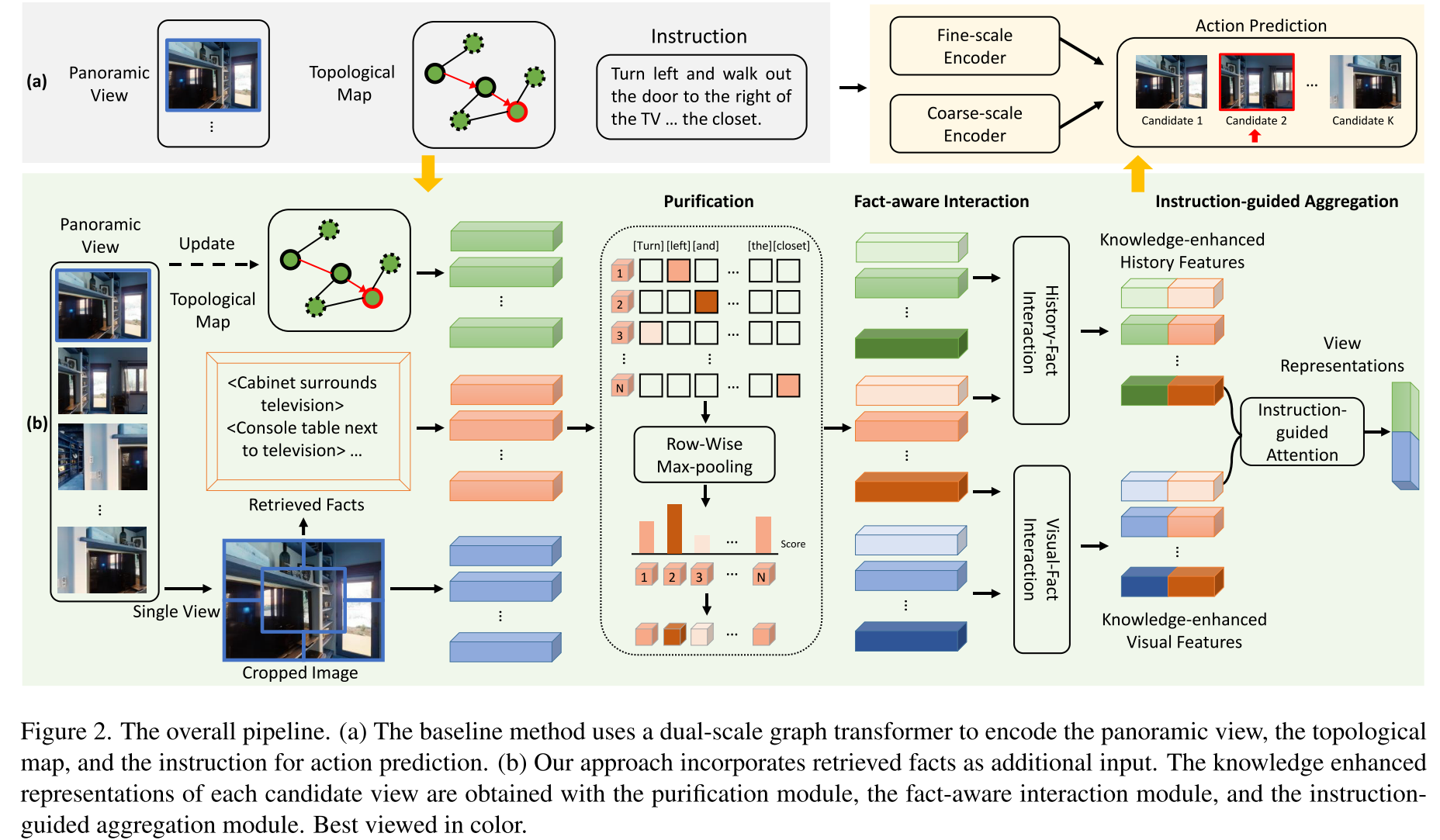
- (a) DUET(a dual-scale graph transformer)对全景视图(panoramic view),拓扑图以及用于动作预测的指令进行编码
- 其中拓扑图是通过将新观察到的信息添加到拓扑地图并更新其节点的视觉表示来随时间构建的
- 拓扑图中的节点有三种类型,边缘为实线的节点表示已经访问过的节点,红色表示当前节点,虚线代表navigable nodes
- 所有36张当前位置的单视角图,拓扑图以及指令都会被一起送入dual-scale graph transformer来预测下一个位置或者输出停止动作
- (b) KERM利用知识来获得上下文表示:
- 首先检索对每个离散视图的视觉特征有补充作用的facts
- 然后,instruction、topological map、visual view features和对应的facts被送到the purification module,the fact-aware interaction module和the instruction-guided aggregation module中,以形成知识增强表示
- 最后利用dual-scale graph transformer预测action
Fact Acquisition
high-level的关于物体和关系的抽象知识对于模型关联视觉物体和指令中提及的概念非常重要,有利于对candidate views和instructions的匹配,作者首先基于Visual Genome dataset构建了知识库,然后来利用CLIP来检索每个视图对应的facts
Knowledge Base Construction
为了获取丰富多样的区域描述,作者利用Visual Genome dataset的区域描述来构建知识库。在VG数据集中,属性标注采用”attribute - object”的pair形式,关系标注则采用”subject - predicate - object”的三元组形式。作者将所有的”attribute - object” pairs和”subject - predicate - object” triplets转换为对应的同义词规范形式,在去重后最终获得了630K个facts作为知识库。
Fact Retrieval
将每个视图crop成5个子区域,并利用CLIP来检索每个子区域对应的facts,每个子区域得到top-5相似的facts。

Knowledge Enhanced Reasoning
在每一个step,the visual features, the history features, the instruction features和the fact features都被送进KERM进行action预测
- visual features: 由CLIP-I进行编码,每个单视图对应5个子区域的特征
- fact features: 由CLIP-T进行编码,每个单视图对应5*5=25个fact features
- historical information和the layout of the explored environment则是由拓扑图的所有节点来表示
- instruction features由multi-layer transformer进行编码
Purification Module
由于每个视图对应的fact features并不是都是agent完成当前导航任务所需要的,因此作者提出了instruction-aware fact purification module来滤除低相关性的信息,并抓取与当前导航任务最相关的关键信息。
- 具体来说,首先计算每个fact和navigation instruction中每个token的相关性,通过the fact-instruction relevance matrix $A$来计算相关性:
$A=\frac{\left(E_{n} W_{1}\right)\left(L W_{2}\right)^{T}}{\sqrt{d}}$
其中$W_1$和$ W_2$都是可学习参数,$d$代表特征维度,$E_n$代表fact features,$L$代表instruction features,也就是计算点乘时加入了两个可学习参数矩阵。
- 然后对$A$进行row-wise max-pooling来计算每个fact和instruction的相关性
$\alpha_n=max\{A_{n,i}\}^M_{i=1}$
- 然后利用相关性对fact features进行加权(达到”purified”的目的)
$E^{‘}_n=\alpha_nE_n$
visual region features和history features也经过相同的注意力方式进行purify
Fact-aware Interaction Module
在获得purified features后,作者使用多层的跨模态transformer(包括cross-attention和self-attention)进行vision-fact,history-fact之间的交互,得到增强后的vision features和history features
Instruction-guided Aggregation Module
最后使用instruction-guided attention来将vision-fact features聚合到一个统一区域的特征(利用注意力对5个子区域特征进行加权求和,权重是子区域特征和指令特征的相似度),history-fact features同理,然后利用FFN将统一区域特征和历史特征进行融合,最后送入dual-scale graph transformer进行action prediction
Training and Inference
Pretraining
利用4个任务预训练KERM模型
- Masked language modeling
- Masked view classification:利用分类模型来获得view image的标签,然后再用于训练KERM
- Single-step action prediction(SAP)
- Object grounding
Fine-tuning and Inference
- imitation learning method
- SAP
Experiment
- REVERIE
- 指令比较简洁,平均包含21个词
- 每张全景图都有bbox标注,agent在导航的最后需要选取正确的bbox
- path length is between 4 and 7 steps
- SOON
- 指令描述了目标地点和目标对象
- 指令平均包含47个词
- 没有物体的bbox标注,agent需要预测目标对象的中心点位置
- path length is between 2 and 21 steps
- R2R
- 提供了每一步的指令
- 不要求预测物体位置
- The average length of instructions is 32 words
- The average length of paths is 6 steps