TaPA
Embodied Task Planning with Large Language Models
基于LLMs的具身任务规划
Motivation
受限于数据样本和多样的下游应用,直接在不同的应用环境训练同一个agent是不现实的。LLMs可以在复杂任务的plan generation中为agent提供丰富的语义知识,但LLMs无法感知周围环境,缺乏真实世界的信息,常常会产生无法执行的action sequences。
本文中关注的“不可执行的action”主要指LLMs给出的action提及了不存在的物体,比如人类指令是”Give me some wine”,GPT-3.5产生的action steps为”pouring wine from the bottle to the glass”,但实际的场景中可能并没有”glass”,只有”mug”, 实际上可以执行的指令是”pouring wine from the bottle to the mug”
- construct a multimodal dataset containing triplets of indoor scenes, instructions and action plans
- designed prompts+the list of existing objects in the scene输入到GPT3.5,得到instructions和对应的action plans
- The generated data is leveraged for grounded plan tuning of pre-trained LLMs
Related Work
从周围环境接收信息
- [37] A persistent spatial semantic representation for high-level natural language instruction execution
- [38] Piglet: Language grounding through neuro-symbolic interaction in a 3d world
- [39] Grounding language to autonomously-acquired skills via goal generation
prompt engineering
设计任务指令和相应动作的简单示例来对LLMs进行提示,以产生合理的任务计划,并通过构建具有语义相似性的映射来过滤出可执行计划子集
- [40] Language models as zero-shot planners: Extracting actionable knowledge for embodied agents
根据action feedback为复杂任务生成决策
- [41] Pre-trained language models for interactive decision-making
SayCan和LLM-Planner都通过提取场景的latent features或物体名称来为LLMs提供视觉信息
SayCan只能完成在厨房场景下的任务
LLM-Planner在ALFRED simulator中实现,大部分任务都非常简单,如putting and placing
- [14] Do as i can, not as i say: Grounding language in robotic affordances
- [15] Llm-planner: Few-shot grounded planning for embodied agents with large language models
Methodology
Data Generation of Embodied Task Planning
利用GPT-3.5来生成为planning agent tuning生成大规模多模态数据集
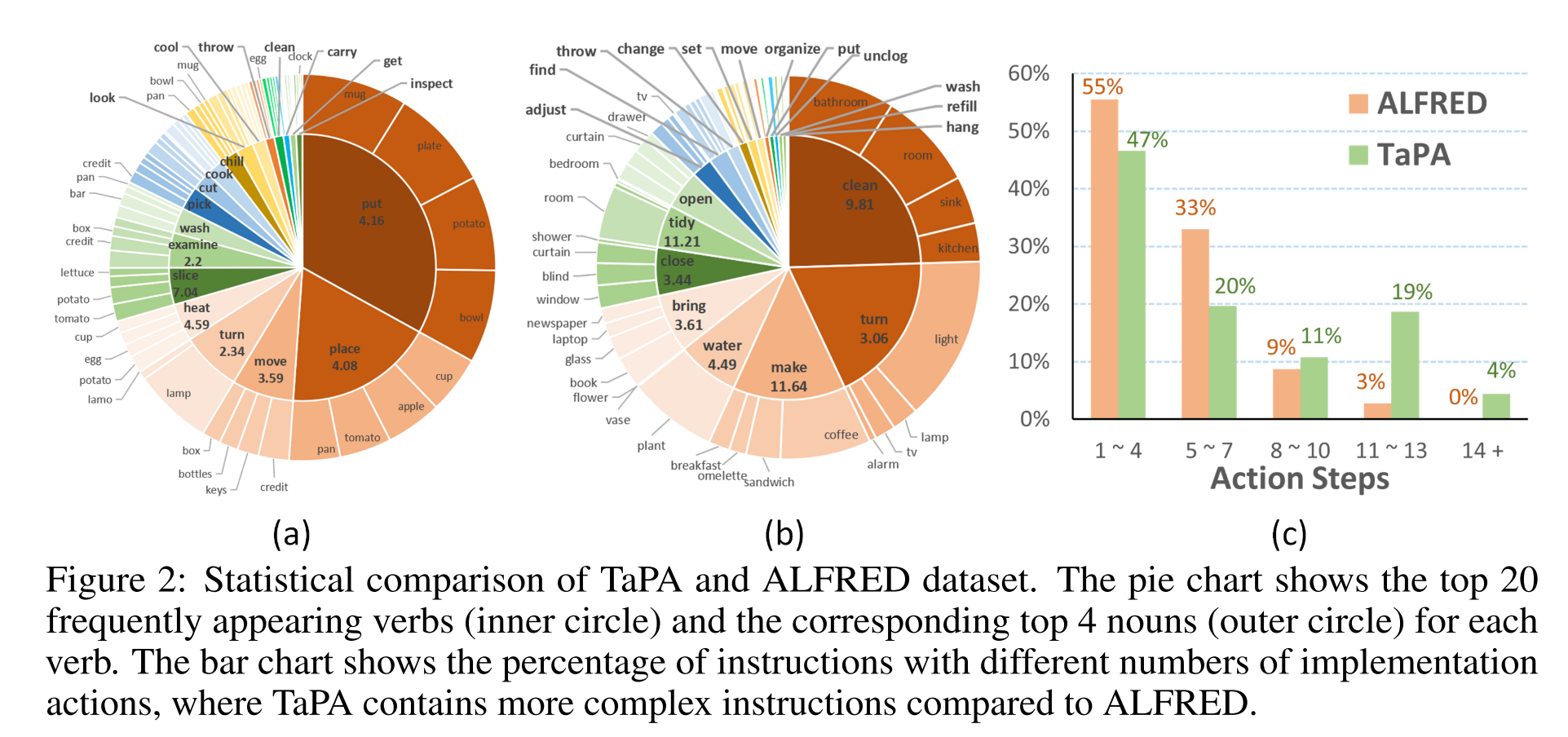
利用给定具身场景中的所有objects的class name来表示场景,基于这种场景表示,在ALFRED benchmark使用了一个简单的方法来生成embodied task plans数据集的多模态指令,即人为地设计一系列对应着逐步的actions的指令。但对于复杂的现实任务来说,这样的手工标注成本极高。
本文设计了prompt来模拟具体任务规划的场景,基于object name list来自动生成数据。prompt描述了以下内容:
- embodied task planning的定义
- 生成指令的要求
- 几个样例
在生成指令时使用了对应场景所有实例的ground truth label
以下是prompt示例
- the definition of embodied task planning
- the requirements
- several examples of generated instructions and corresponding action plans

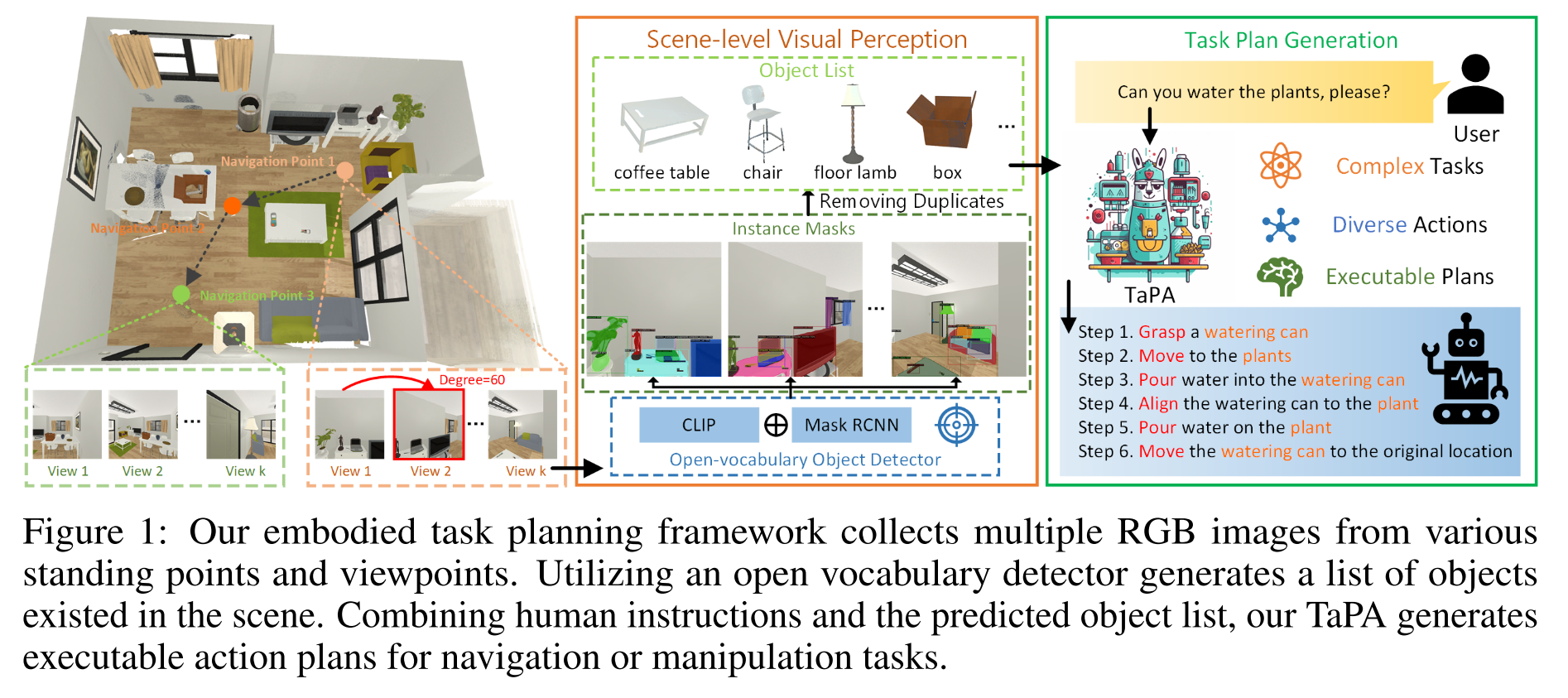
实际进行规划时,agent只能获取视觉场景中的所有可交互物体,并没有GT object list。因此作者构建了一个多模态数据集,用三元组表示一组数据(visual scenes, instructions, the corresponding plans), 在task planner的训练阶段,直接使用gt object list来避免不准确的视觉感知对训练带来的影响,在task planner的推理阶段,则使用open-vocabulary object detector来预测场景中存在的object list作为task planner的输入。
- 编码场景信息的过程

使用AI2-THOR simulator来作为agent的环境,split the scenes with 80 for training and 20 for evaluation,为了增加训练集容量和多样性,作者做了数据增强的操作,通过直接修改gt object list将原本的80个训练场景扩充到了6400个训练场景。
- 对于每个场景类型,首先通过枚举相同类型的所有房间来获取可能出现在这种类型的场景中的对象的列表
- 然后随机地用可能存在于相同类型房间,并且未被观察到的其他对象替换存在的对象
- 似然性约束(plausibility constraint)旨在防止针对给定场景类型生成违反直觉的对象
- 作者收集了15K个样本进行训练,并利用另外60个三元组对本文提出的multimodal data generation framework进行评估
生成的三元组(visual scenes, instructions, the corresponding plans)数据样例

Grounding Task Plans to Surrounding Scenes
由于在使用的场景中可能会出现训练集里没有见过的类,因此引入open-vocabulary object detector。
agent收集不同位置观察到的RGB图像来感知视觉场景中存在的对象,作者设计了几种图像收集策略来探索周围的3D场景
image collection strategies可以表示为:
$\mathcal{S}=\left\{(x, y, \theta) \mid(x, y) \in L(\boldsymbol{\lambda}, \mathcal{A}), \theta=k \theta_{0}\right\}$
其中$(x,y)$表示位置,$\theta$表示相机朝向,$\boldsymbol{\lambda}$代表调整位置选择标准的超参,$\mathcal{A}$代表可选的区域,$\theta_0$代表相机旋转的最小单元,$k$为整数,也就是每个位置会有间隔的采样不同角度视角下的图像。可选的区域$\mathcal{A}$会被划分为网格,根据采样方式的不同,会遍历所有网格进行采样或者有选择地采样,根据位置的不同,采样点分为全局中心和分块中心,分别获得全局的视觉信息和局部的细粒度视觉信息:
- The overall center point stands for the center of the whole scene without any hyperparameters
- The block-wise center points aim to choose the center of each division in the scene to efficiently acquire fine-grained visual information
经过实验对比,作者选择the block-wise center point for multi-view RGB image collection。位置选择标准中的网格大小被设置为0.75,相机旋转的单位角度为2π/3。
然后用OVD对多视角图片进行检测并去重,得到object list,和instruction作为输入,然后TaPA输出对应的action plans。
Experiment
AI2-THOR simulator中进行实验
LLaMA-7B pre-trained language model作为task planner的backbone,并使用本文生成的多模态数据进行微调
- maximum token number为512
- OVD使用Detic
- 8卡3090
Evaluation Metrics
使用人工投票的方式评估生成的action plan的正确率,错误的类型分为:
- counterfactuals(违反了物理规律,比如在走到门口之前抓住门把手)
- hallucination(和场景中不存在的对象进行交互,例外的情况是交互对象可以是存在于场景中的对象的一部分(例如垃圾桶盖和垃圾桶)或物体的同义词(例如马克杯和杯子))
Experimental Results
TaPA和其他大模型在60个validation samples上的成功率对比
- 其实都还比较低,厨房环境任务最复杂,所以成功率最低
- prompt方式影响很大,LLaVA和LLaMA都是使用各自原始的finetuning prompt
- 在进行了instruction tuning后,TaPA比GPT-3.5提升了6.38%
- 多模态大模型LLaVA较差的表现反映了在视觉问答任务中整体场景信息不能由单个图像表示的事实,而进行action plan需要对场景进行充分的理解

采样策略和超参设置的影响

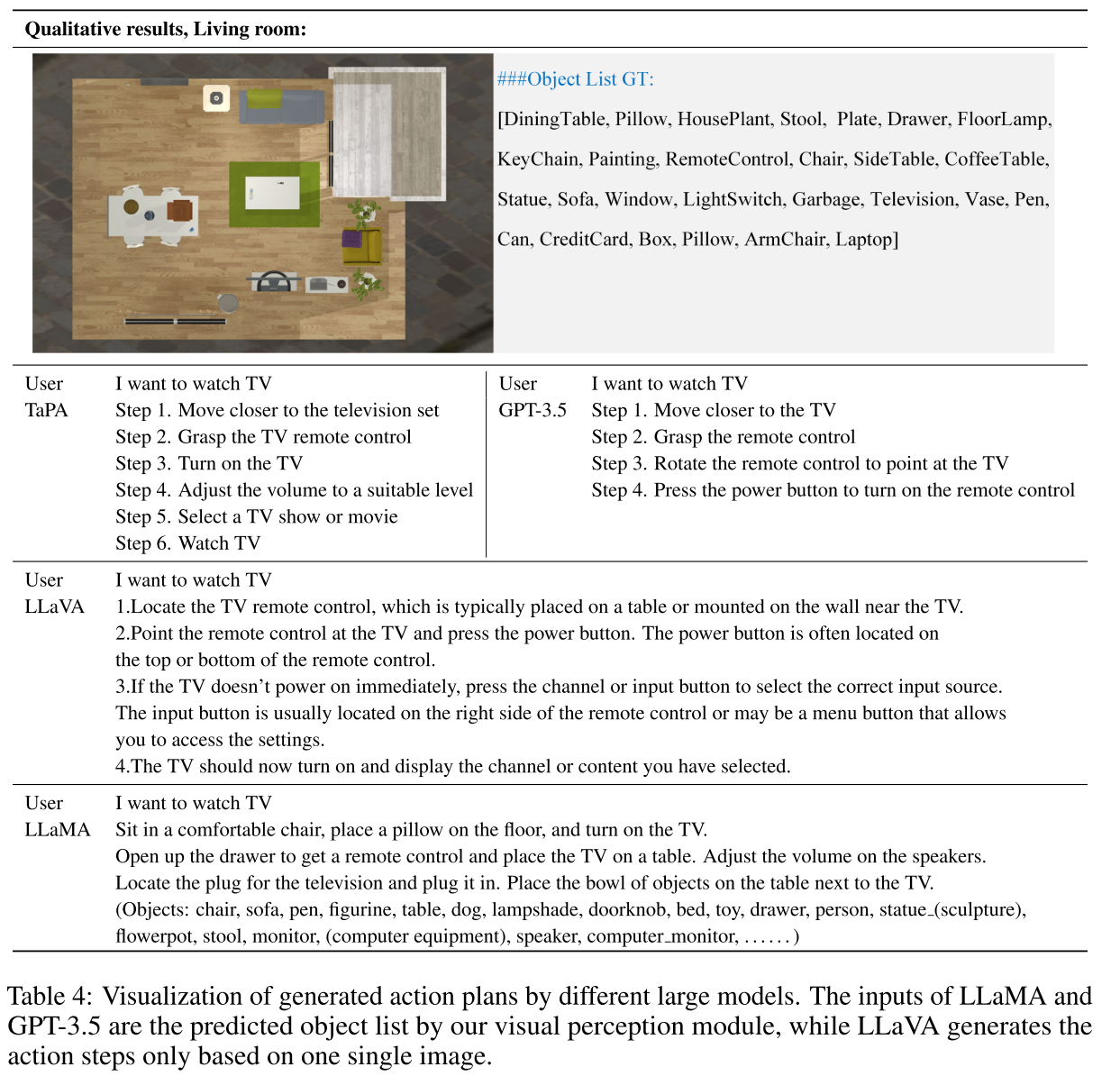
一个对比例子