OvarNet
Open-vocabulary Object Attribute Recognition(面向开放词汇的目标检测与属性识别)
使用单一模型对图像中任何类别目标同时进行定位、分类和属性预测
Motivation
进行物体属性预测是对视觉场景理解的很好补充,同时训练两个任务会比将两个任务单独对待获得更好的效果
3个挑战:
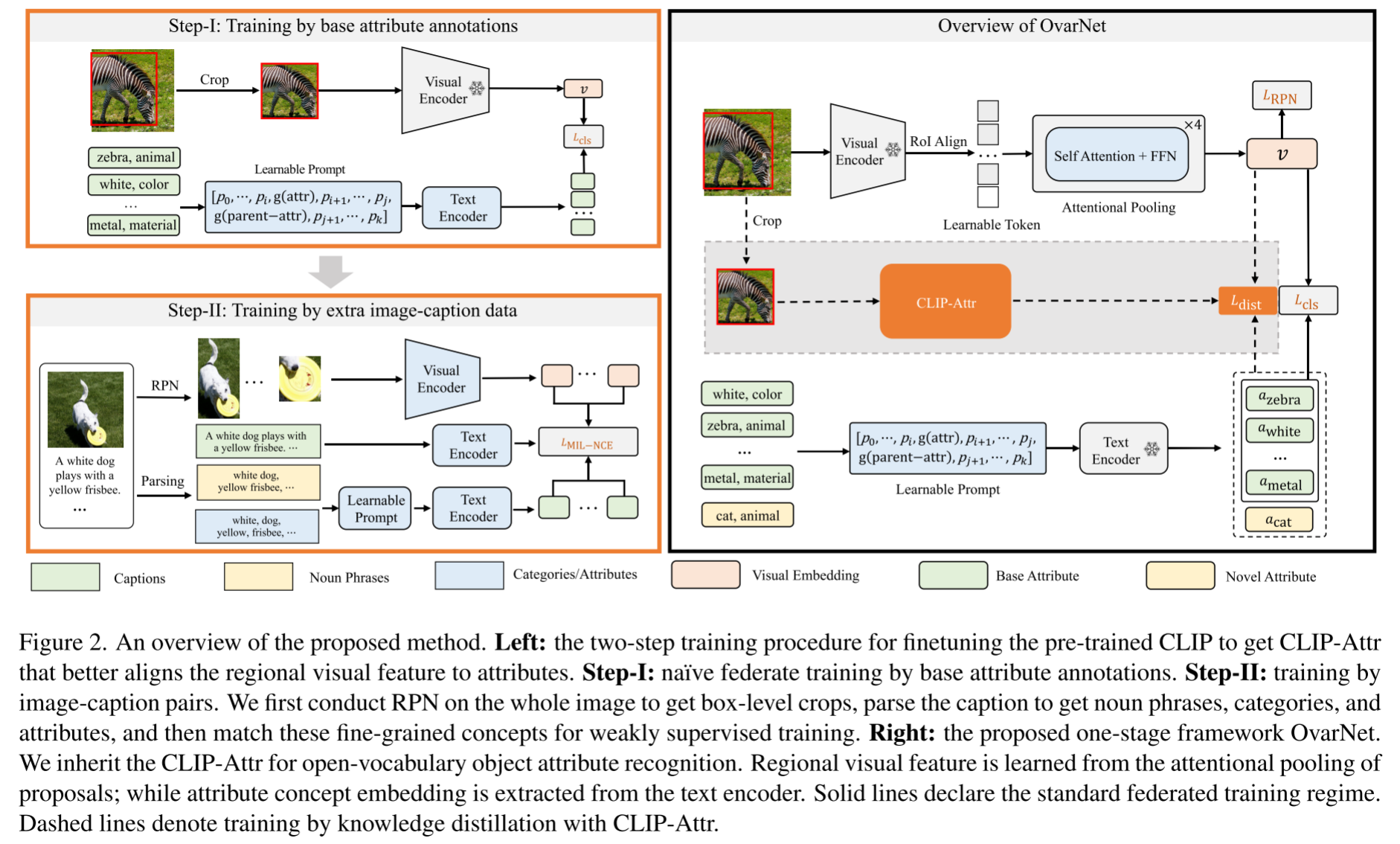
- 已有的基础模型如CLIP是基于image-caption pairs进行训练的,学到的表征更倾向于物体类别,而不是物体属性,这使得直接将CLIP用于属性预测存在不对齐的问题
- 没有同时包含物体框,语义类别和物体属性三种标注的理想的训练集,只有COCO Attributes数据集提供了这样的标注,但是受限于较小的词汇量(196种attributes,29个类别)
- 将这三个任务在开放词汇场景下统一到同一个框架中还尚未得到好的探索
Methodology
方法主要分为 3 步:首先,利用目标检测数据和属性预测数据在开放词汇场景下训练一个简单的两阶段的方法;然后,通过利用大量的图文对数据进一步微调这个两阶段模型以提高在 novel/unseen 类别和属性上的性能;最后,为了保证泛化性和前传速度,基于知识蒸馏的范式设计了一个一阶段的算法