Towards Open Vocabulary Learning: A Survey
Motivation&Background
Zero-Shot Learning(ZSL)缺少对不可见对象的示例,且在训练期间会将不可见类对象视作背景对象,因此,在推理过程中,模型仅基于其预定义的词嵌入来识别新类别,从而限制了对视觉信息和那些看不见的类别的关系的挖掘。
ZSL和open vocabulary之间的关键区别在于,open vocabulary可以使用视觉相关的语言词汇比如image captions来作为辅助的监督,使用语言来作为辅助的弱监督的motivations包括:
- 相比于box和mask annotation,language data易于获取,标注成本低
- language data提供了更大的词汇量,因此可以更容易地拓展,具有更强地泛化性
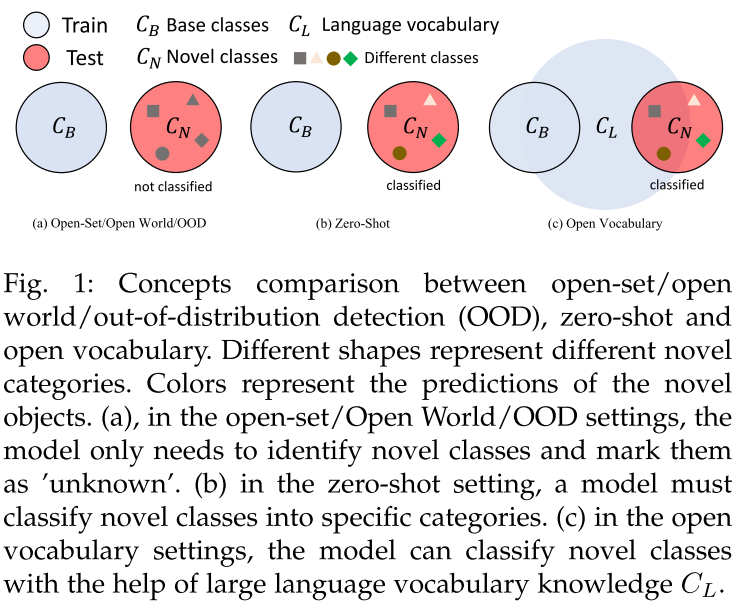
- Open-Set/Open World/OOD:只需要识别出unknown objects,而不需要将它们分到不同的具体类
- Zero-Shot Learning:模型严格在base类上进行训练,novel类在训练时是不可见的,且模型需要为novel类预测具体类别
- Open Vocabulary Learning
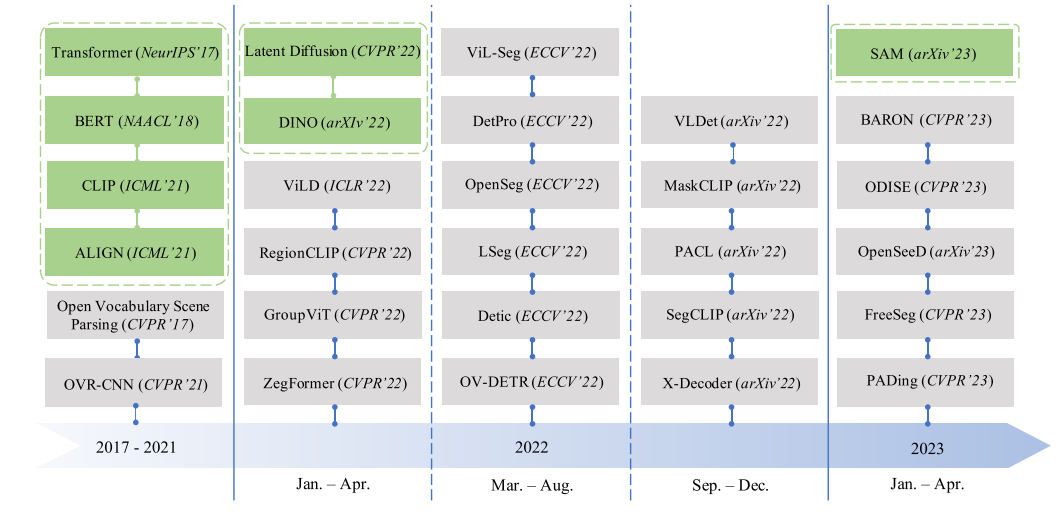
History&Roadmap
灰色框是代表工作,绿色框代表基础模型和VLMs
Tasks, DataSets, and Metrics
- Tasks:
- object detection
- instance segmentation
- semantic segmentation
- object tracking
- open vocabulary attribution prediction
- video classification
- point cloud classification
- Dataset
- object detection: COCO, LVIS, v3Det
- image segmentation: COCO, ADE20k, PASCAL-VOC2012, PASCAL-Context, Cityscapes
- video segmentation&tracking: VSPW, Youtube-VIS, LV-VIS, MOSE, TAO
- Metrics
- detection: mAP, mAR
- segmentation: mIoU, mask-based mAP, panoptic quality(PQ)
Methodology
常见框架
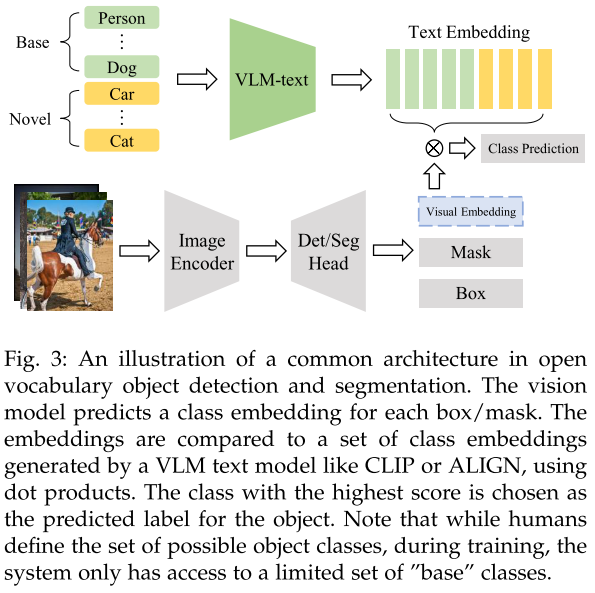
Open Vocabulary Object Detection
Knowledge Distillation
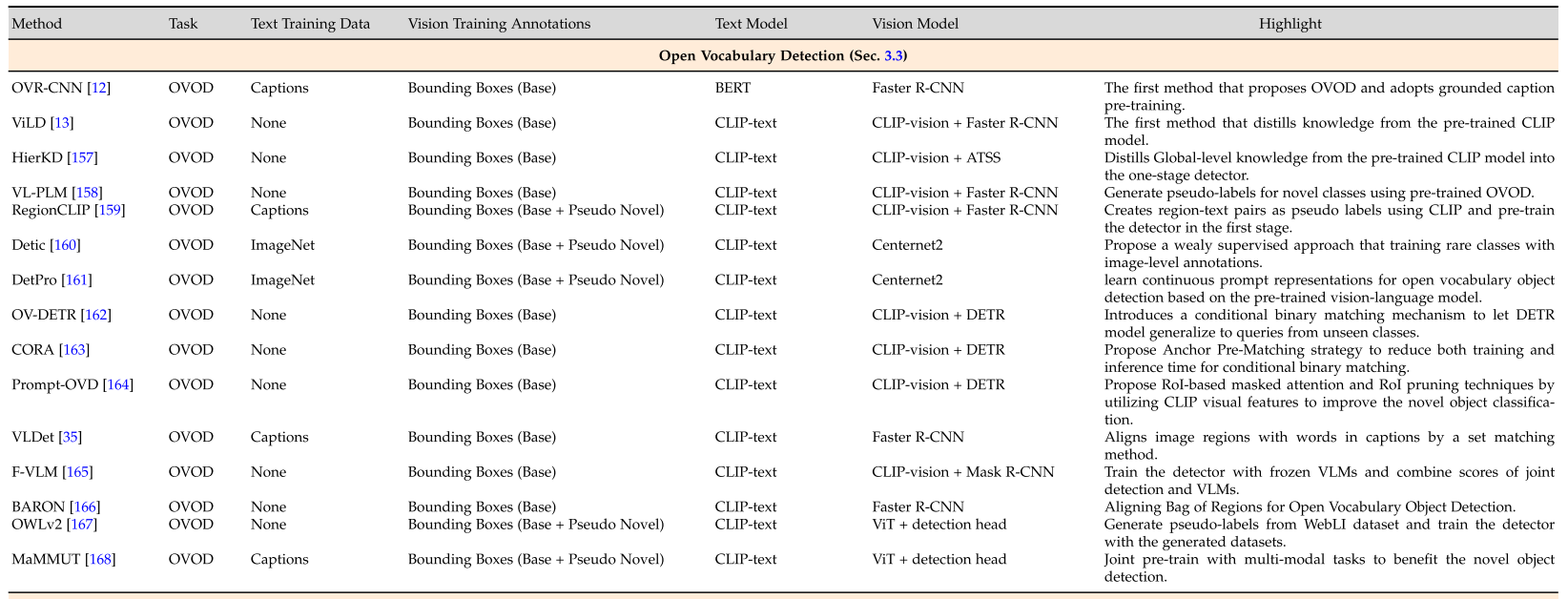
将VLMs的知识蒸馏到detectors中,代表工作如ViLD(two-stage).
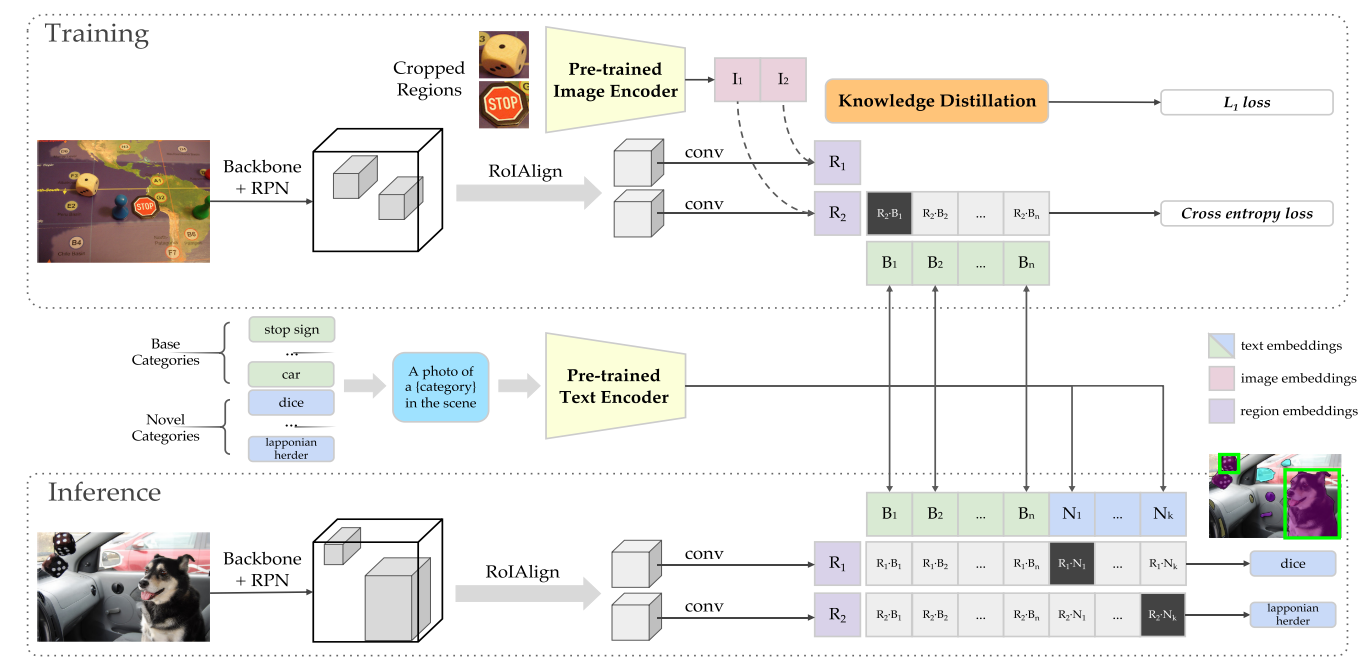
- HierKD-单阶段
OADP同时关注物体间关系
不单使用novel class names做text distillation,使用更加细粒度的信息包括attributes,captions和物体关系
- PCL使用image captioning model生成captions来描述物体实例
- OVRNet同时检测物体和物体的视觉属性
Region Text Pertaining(相关性)
利用易于获取的图像文本对来学习区域文本对齐
学习区域文本对齐将novel classes的视觉特征和文本特征映射到对齐的特征空间中
OVR-CNN第一个引入了caption data
Attribute-Sensitive OVR-CNN在对齐时增强了模型对形容词,动词词组和介词短语的敏感度
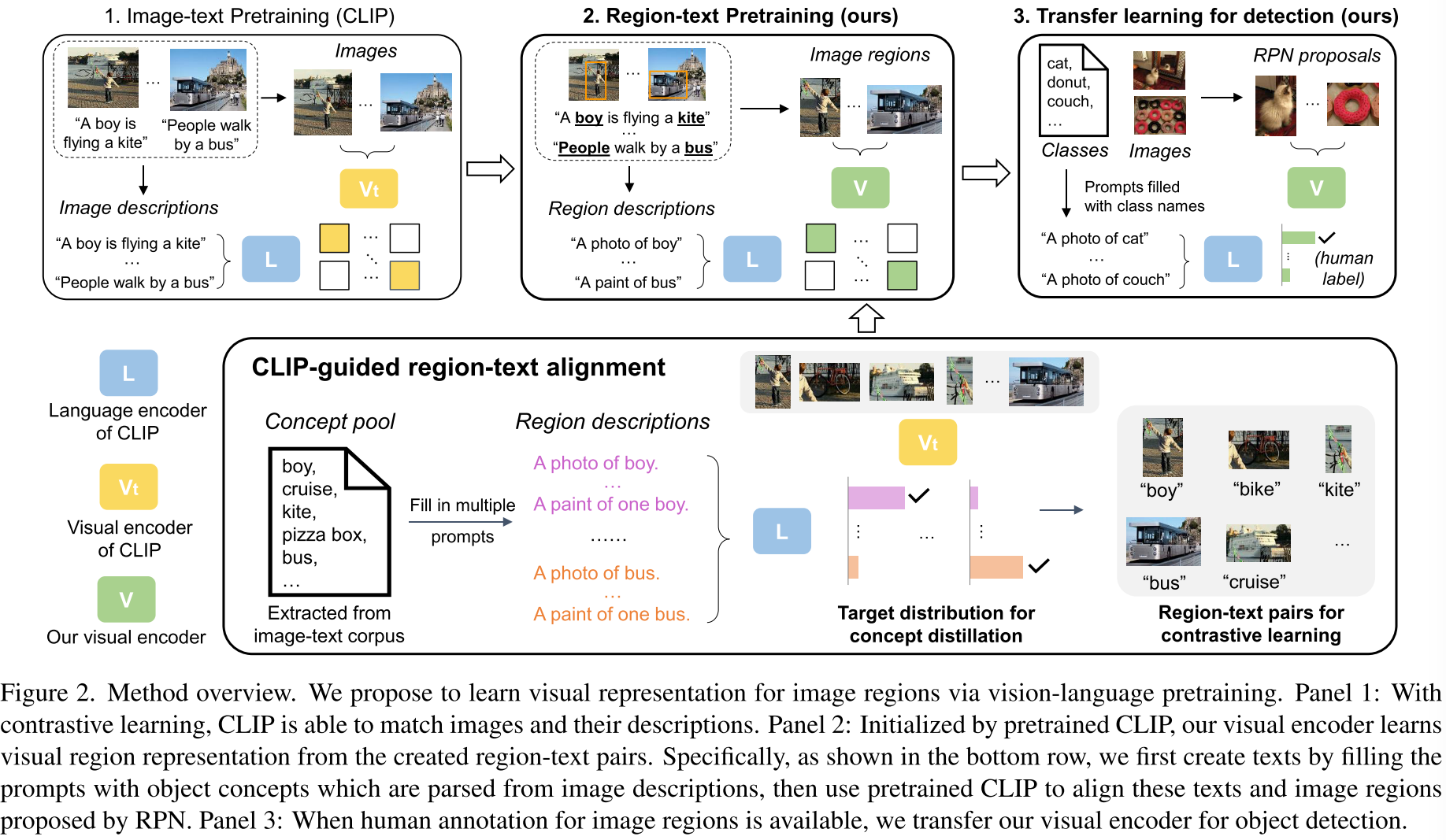
RegionCLIP通过匹配区域和区域对应的描述来学习视觉区域表征
使用图片描述中的词来填充区域描述模板,然后用CLIP来寻找对应的区域描述和RPN得到的proposal,从而得到region-text pairs
- MaMMUT结合了对比学习和生成式学习
Training with More Balanced Data
利用更加平衡的数据,包括图像分类数据集,图像文本对数据生成的伪标签,以及额外的检测数据
- Detic使用image-level的监督提升了long-tail detection的性能,Detic基本的insight是,大部分分类数据都是object-centric的,因此RPN得到的最大候选区域可能完整的覆盖了一个属于image-level class的物体,所以可以利用这一点来引入分类数据集

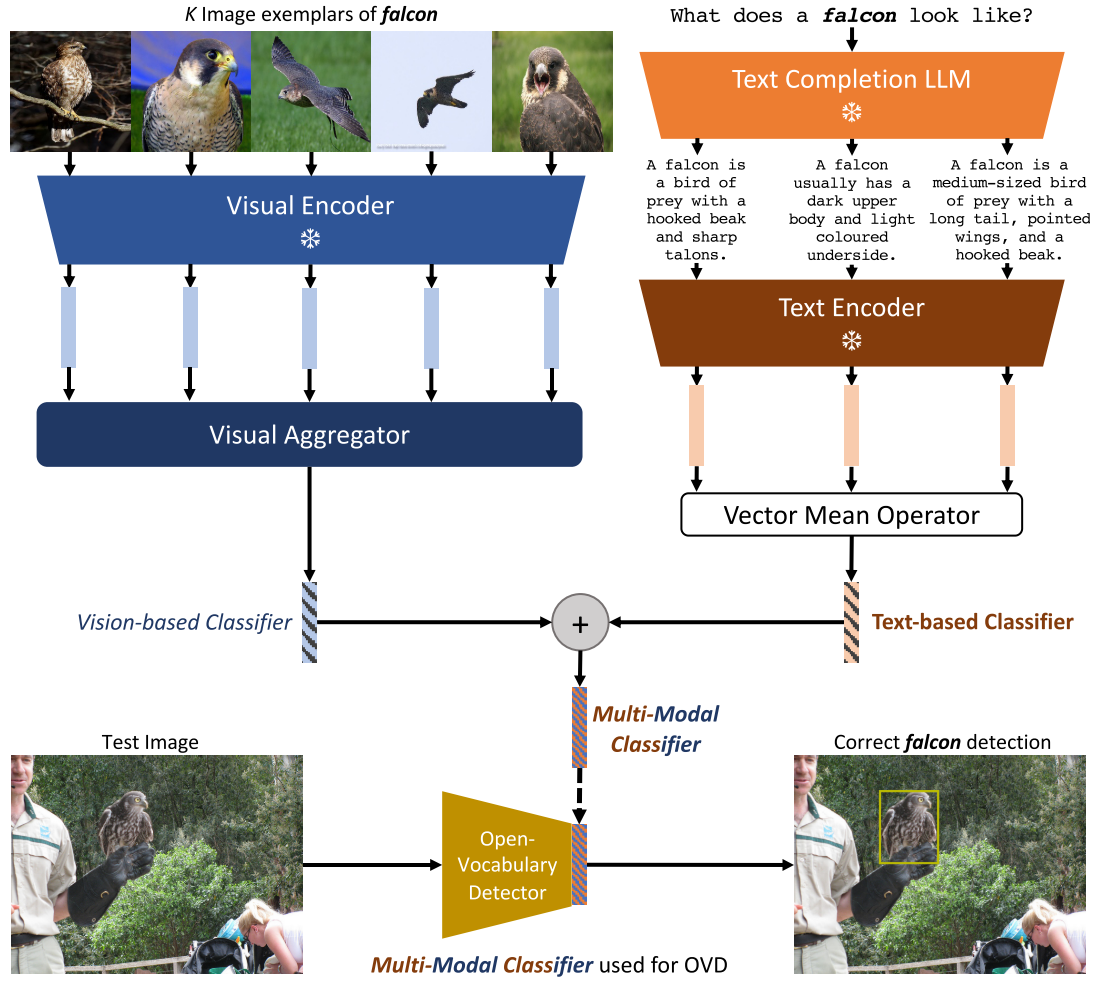
- mm-ovod在Detic基础上引入multi-modal text embeddings来作为classifier。使用LLM来为每个class name生成描述,而不是依赖于手工设计的prompt templates,根据描述来生成text-based embeddings。
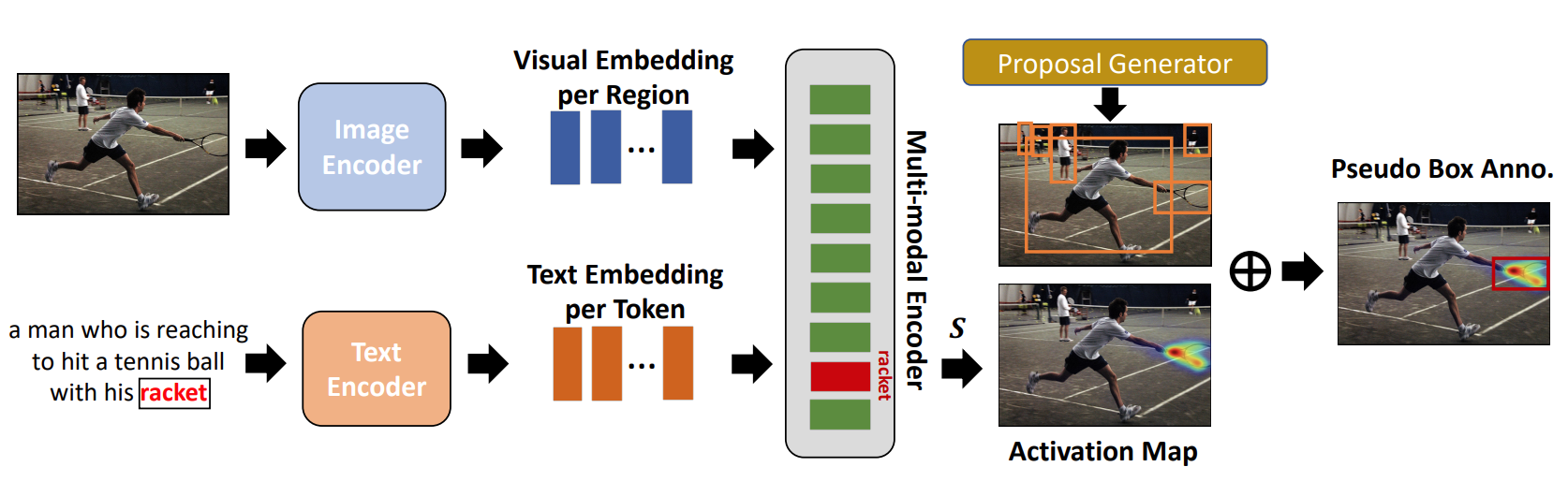
- PB-OVD使用Grad-CAM配合RPN来产生伪标注框,Grad-CAM的激活图是从预训练的VLM的区域嵌入和词嵌入之间的对齐获得的
- VL-PLM提出使用无类别的目标检测数据集把Faster R-CNN训练为一个类别无关的proposal generator
- LocOV使用RPN中的类别无关的的proposal,通过分别匹配图像和字幕的区域特征和单词嵌入来训练Faster R-CNN
- X-Paste生成rare类的的数据来提升现有方法的分类能力
- OWLv2使用self-training来产生大量的伪标签,以实现更加平衡的学习
Prompting Modeling
通过将学习到的提示合并到基础模型中,模型可以更容易地将其知识转移到下游任务
- 由于negative proposals并不属于任何一个具体类别,DetPro强制negative proposal要与任何对象类别同等的不相似,而不是使用一个background class来代表它
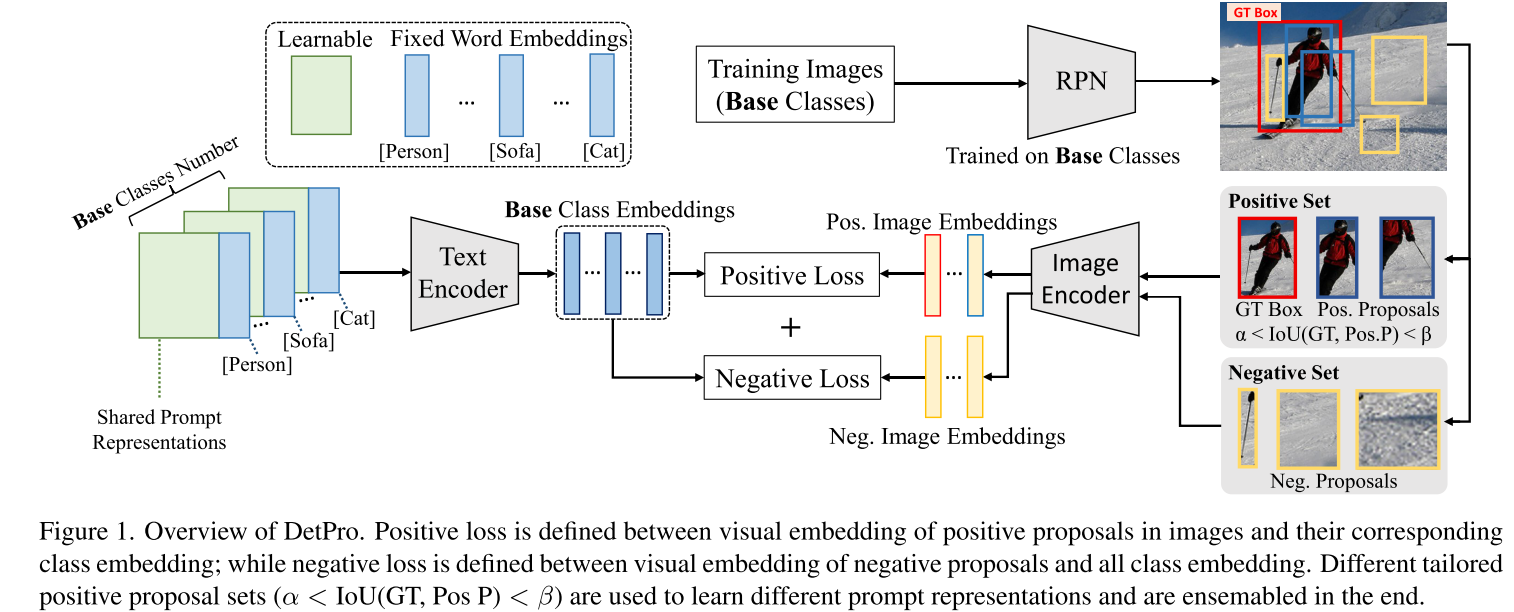
- PromptDet将类别描述引入到prompt中,并探讨了类别在prompt中的位置
- CORA基于DETR框架,提出region prompting,通过对基于CLIP的区域分类器得到的区域特征进行提示,缩小了整体图像与区域分布之间的差距,提出anchor pre-matching来学习可推广的对象定位
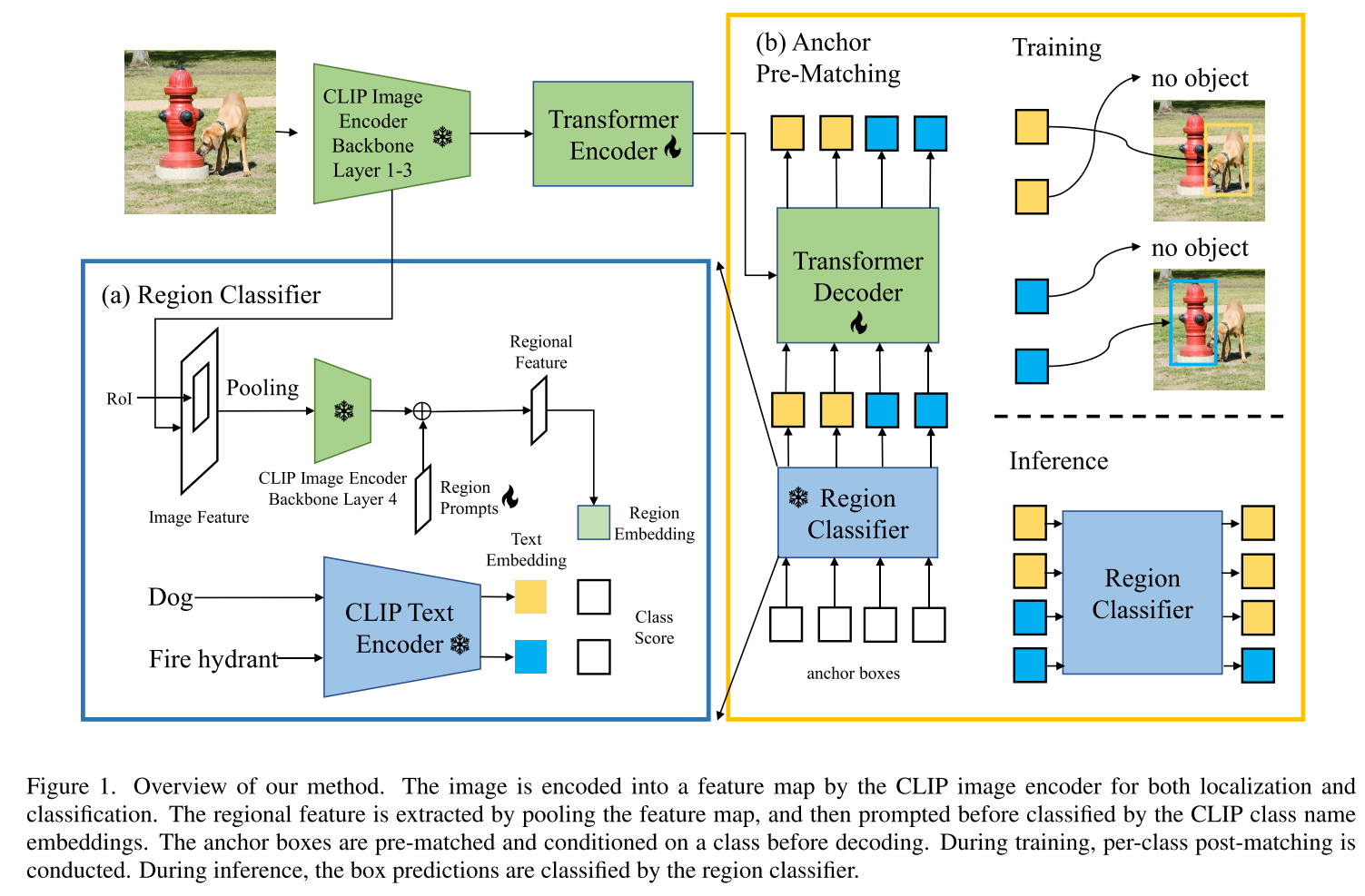
- Prompt-OVD基于OV-DETR,提出RoI-based masked attention和RoI pruning techniques(剪枝)
Region Text Alignment
- OV-DETR将DETR用于OVD,用条件二分图匹配代替二分图匹配
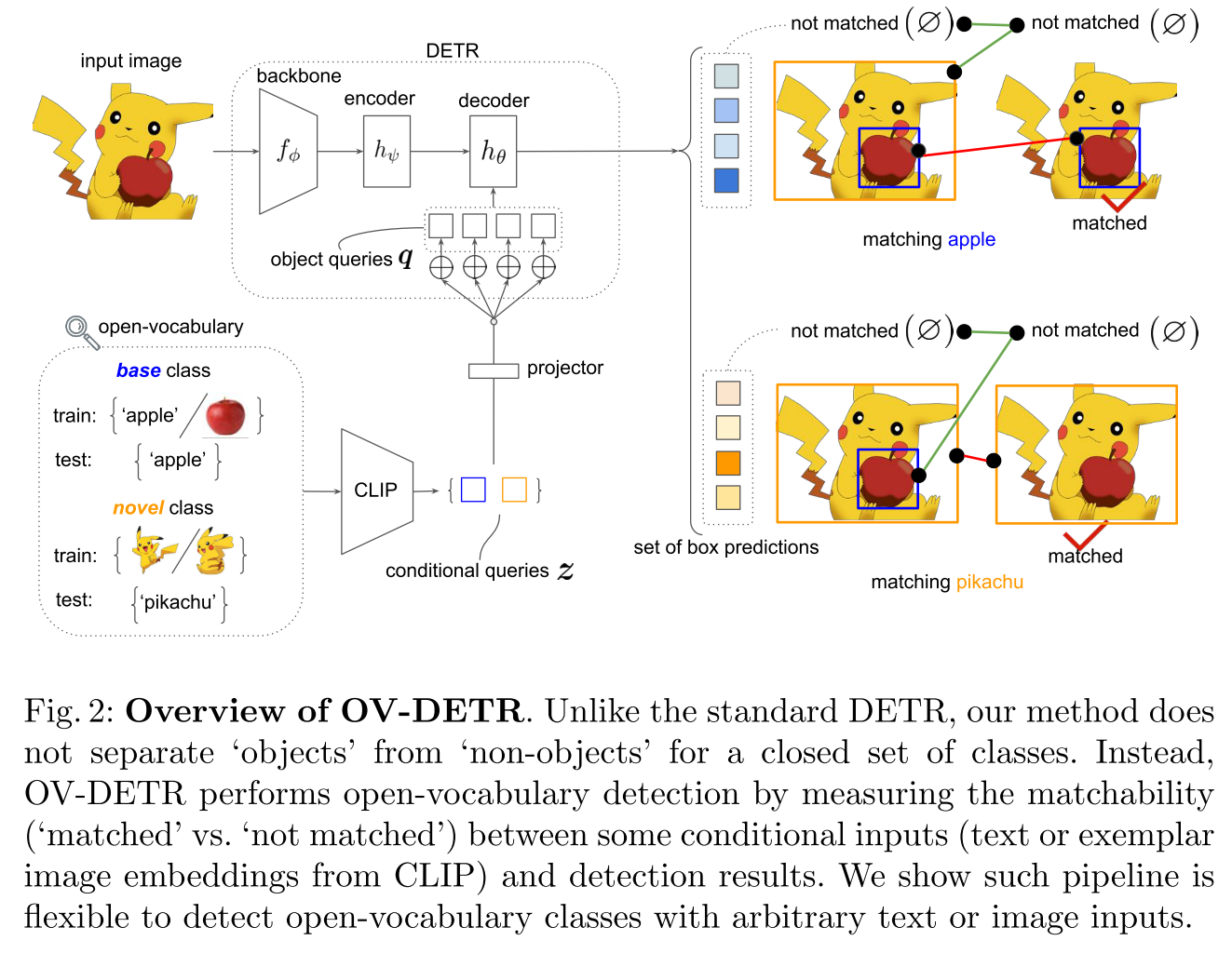
- VLDet将图像转换为一系列区域,caption转换为一系列words,然后使用set matching方法来实现区域和文本的对齐
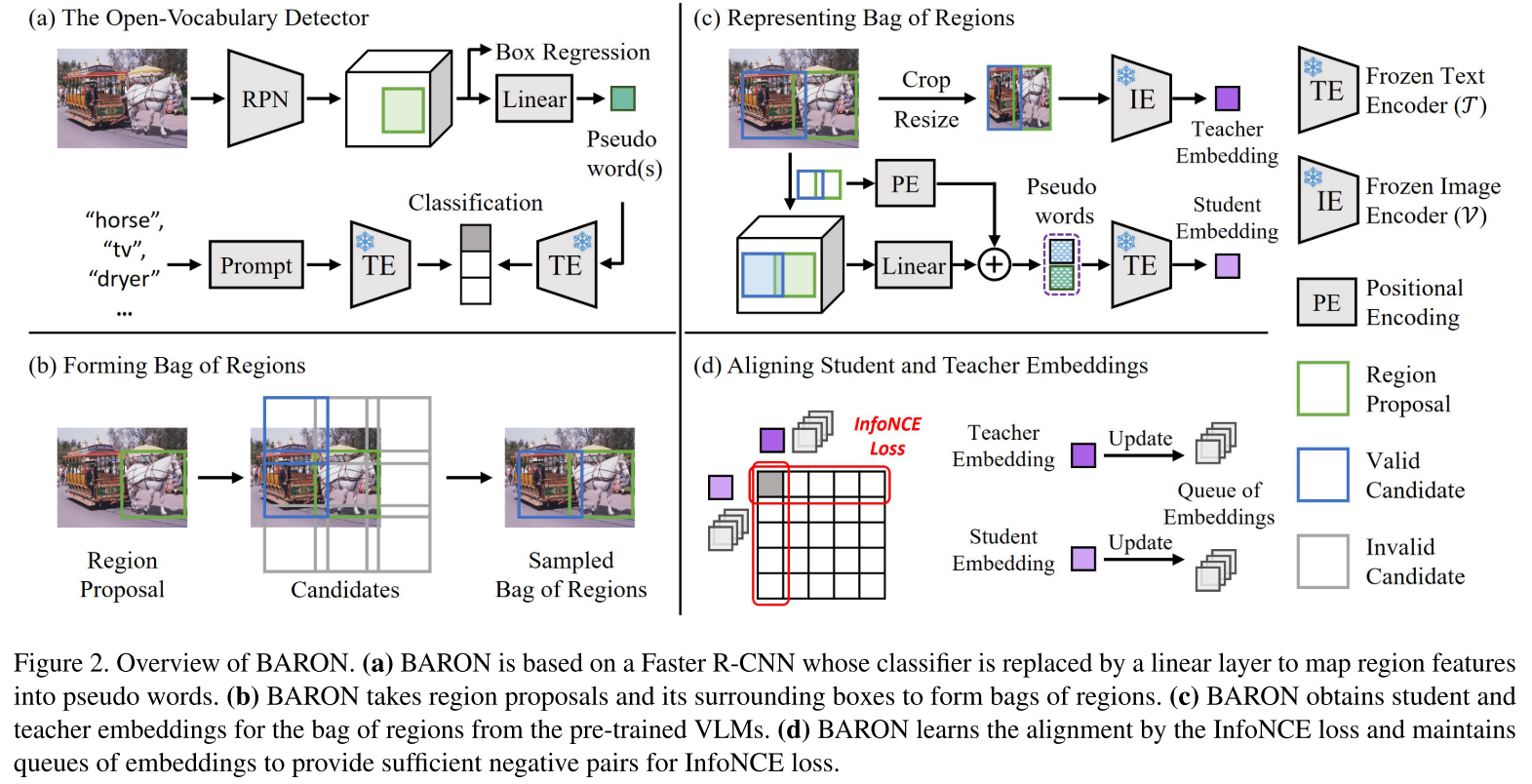
- BARON提出要对齐bags of regions而不是单个region。它首先将上下文相关的区域分组为一个bag,并将袋子中的每个区域视为句子中的一个词。然后,它将bag of regions送到文本编码器以获得bag-of-regions embeddings。这些bag-of-regions embeddings将与来自VLM的图像编码器的cropped region embeddings对齐。
Open Vocabulary Segmentation
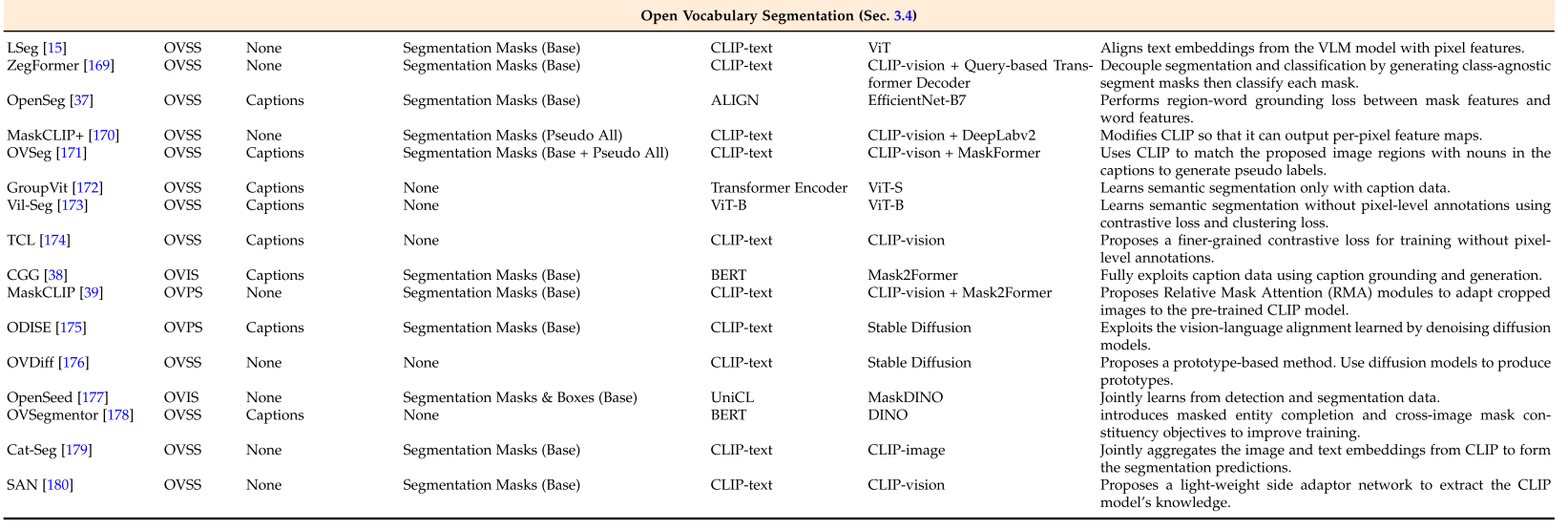
Utilizing VLMs to Leverage Recognition Capabilities
- LSeg
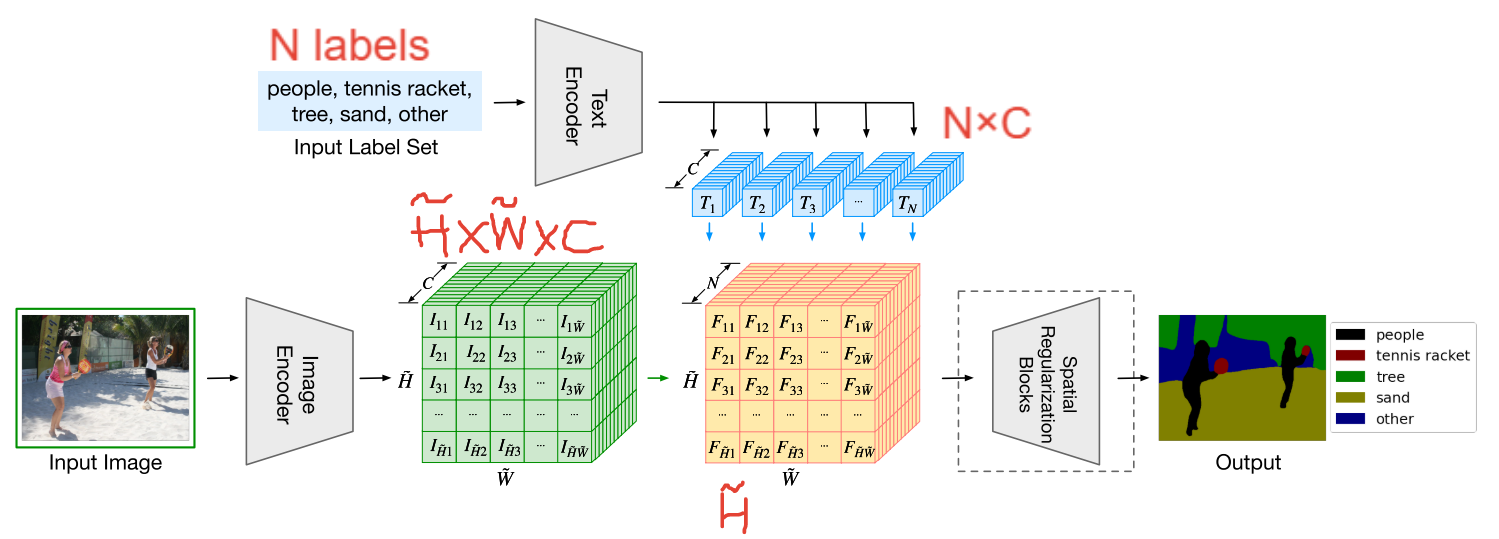
ZegFormer将问题解耦为类不可知的分割任务和掩码分类任务,它使用从 VLM得到的label embeddings来对proposal masks进行分类,并用CLIP的视觉编码器来获得和语言对齐的视觉特征
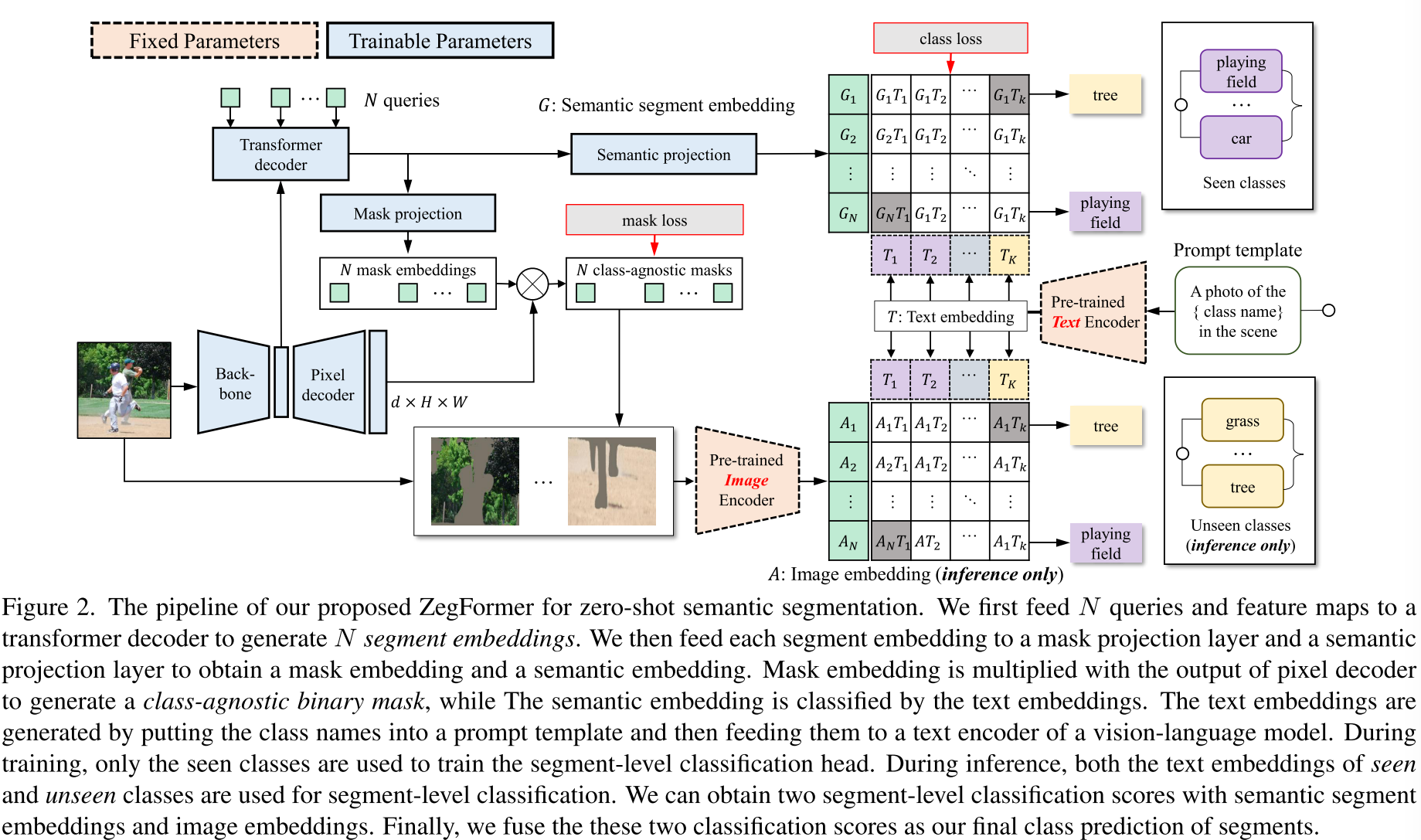
MaskCLIP将Relative Mask Attention modules插入预训练的CLIP,更高效的利用CLIP的特征
Learning from Caption Data
- OpenSeg
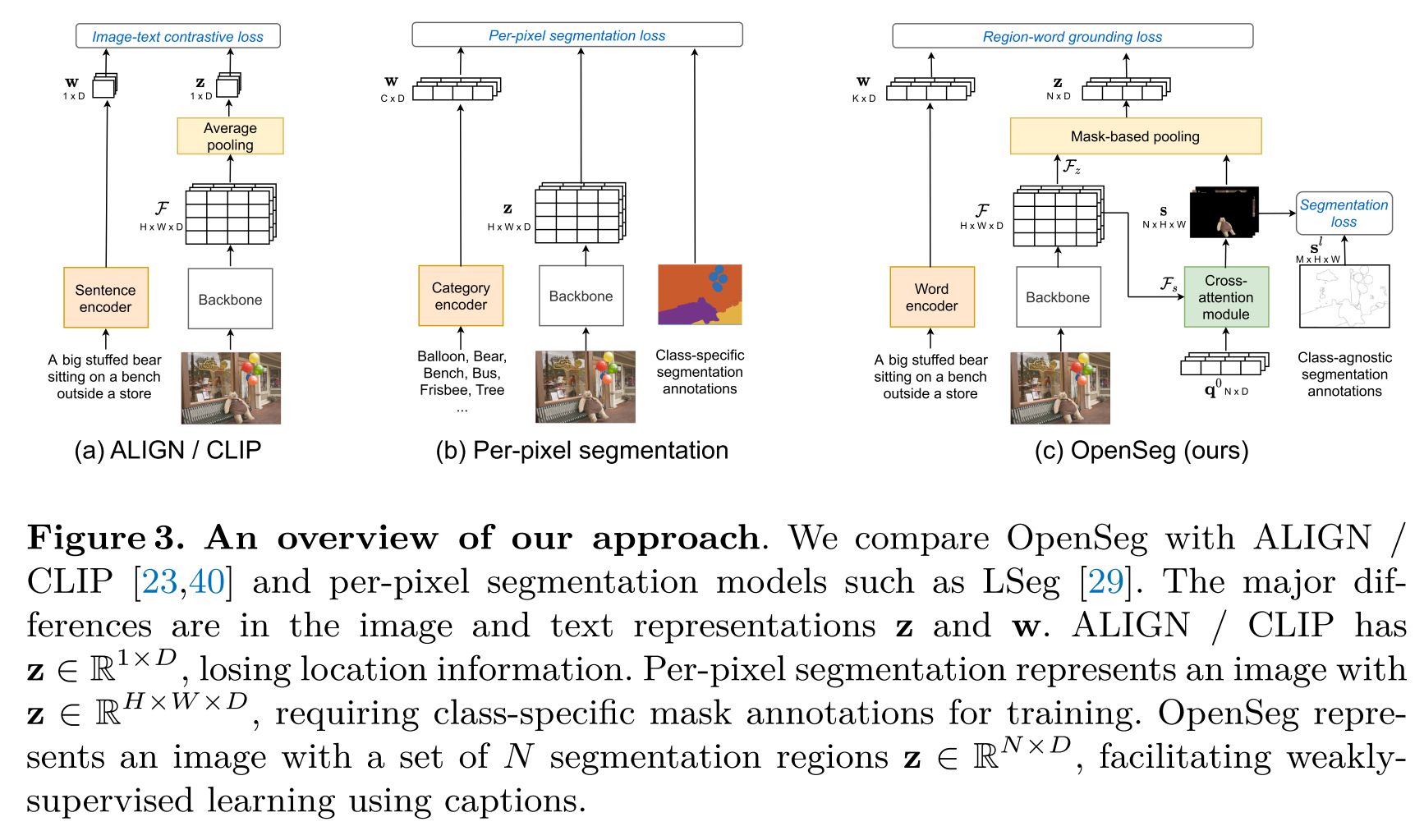
- CGG
Generating Pseudo Labels
MaskCLIP+将CLIP视觉编码器的最后一层pooling layer替换成了卷积层,用来产生dense feature maps,然后将产生的特征图来生成伪标签,用于训练分割模型
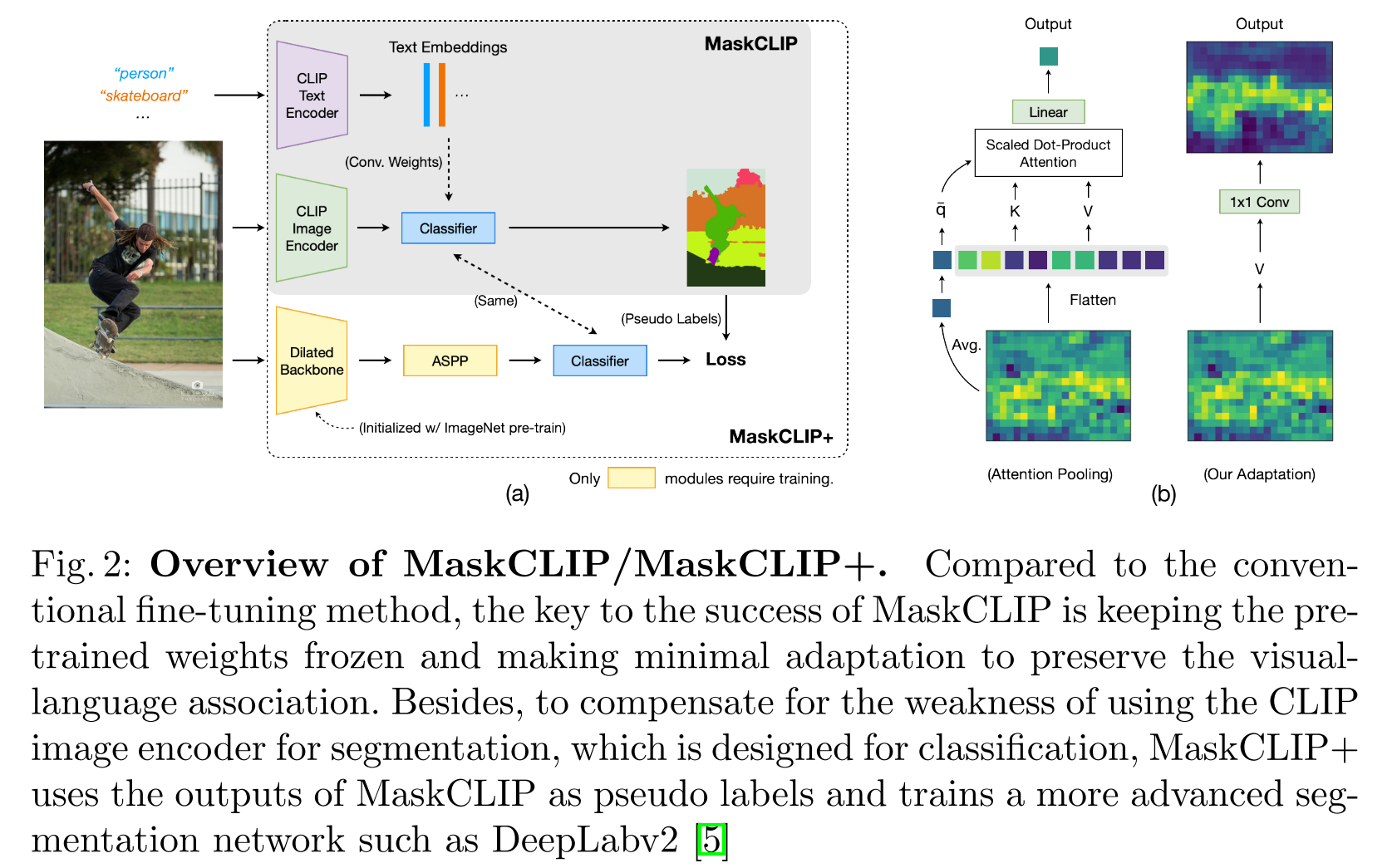
OVSeg
XPM
Training without Pixel-Level Annotations
仅使用弱监督,如image caption
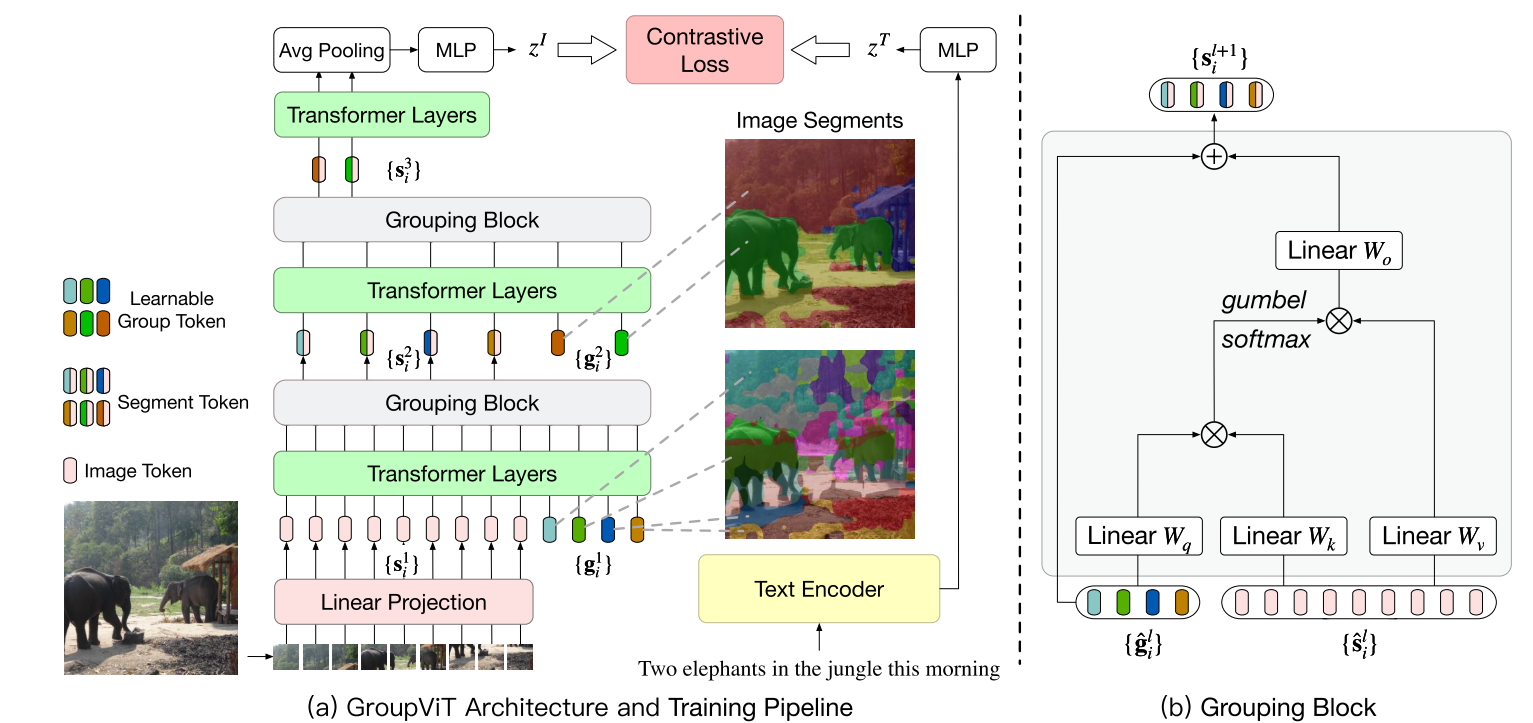
GroupViT
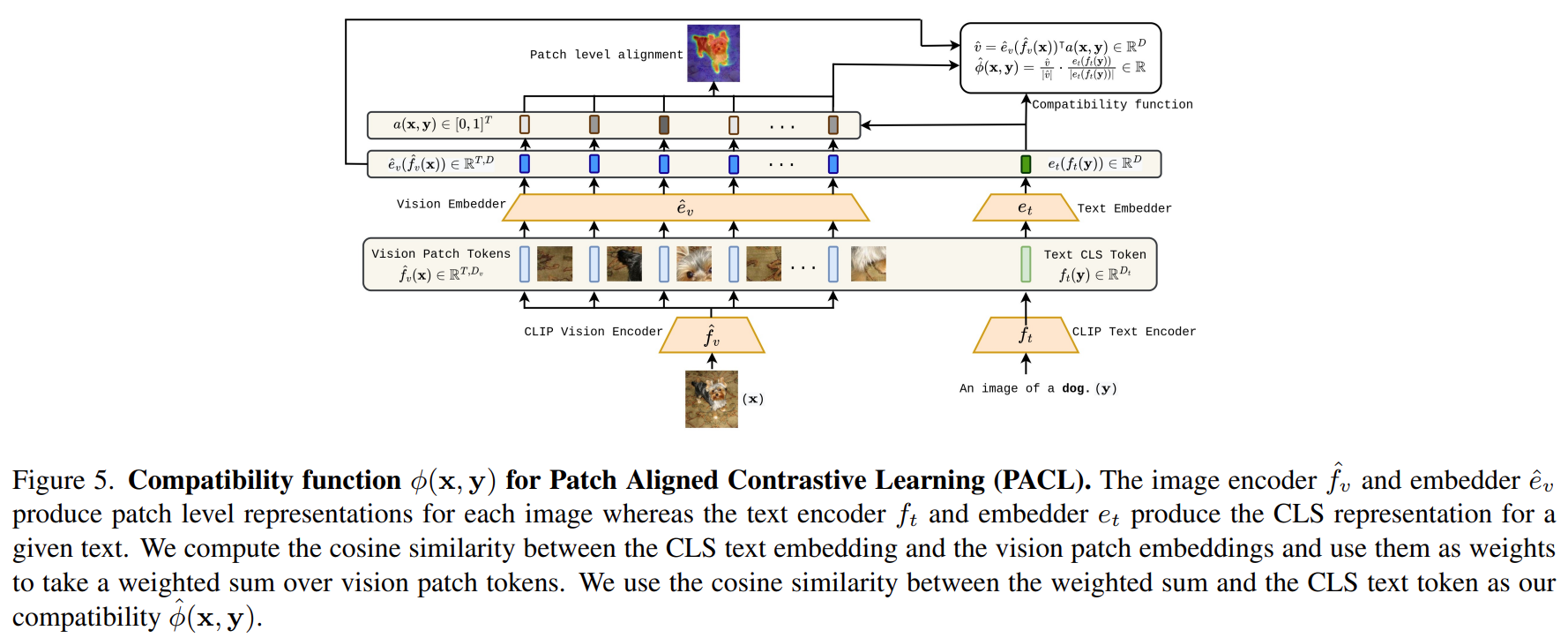
PACL通过对齐image patches和captions的CLS token来增强对比损失
- ViL-Seg结合了对比损失和聚类损失
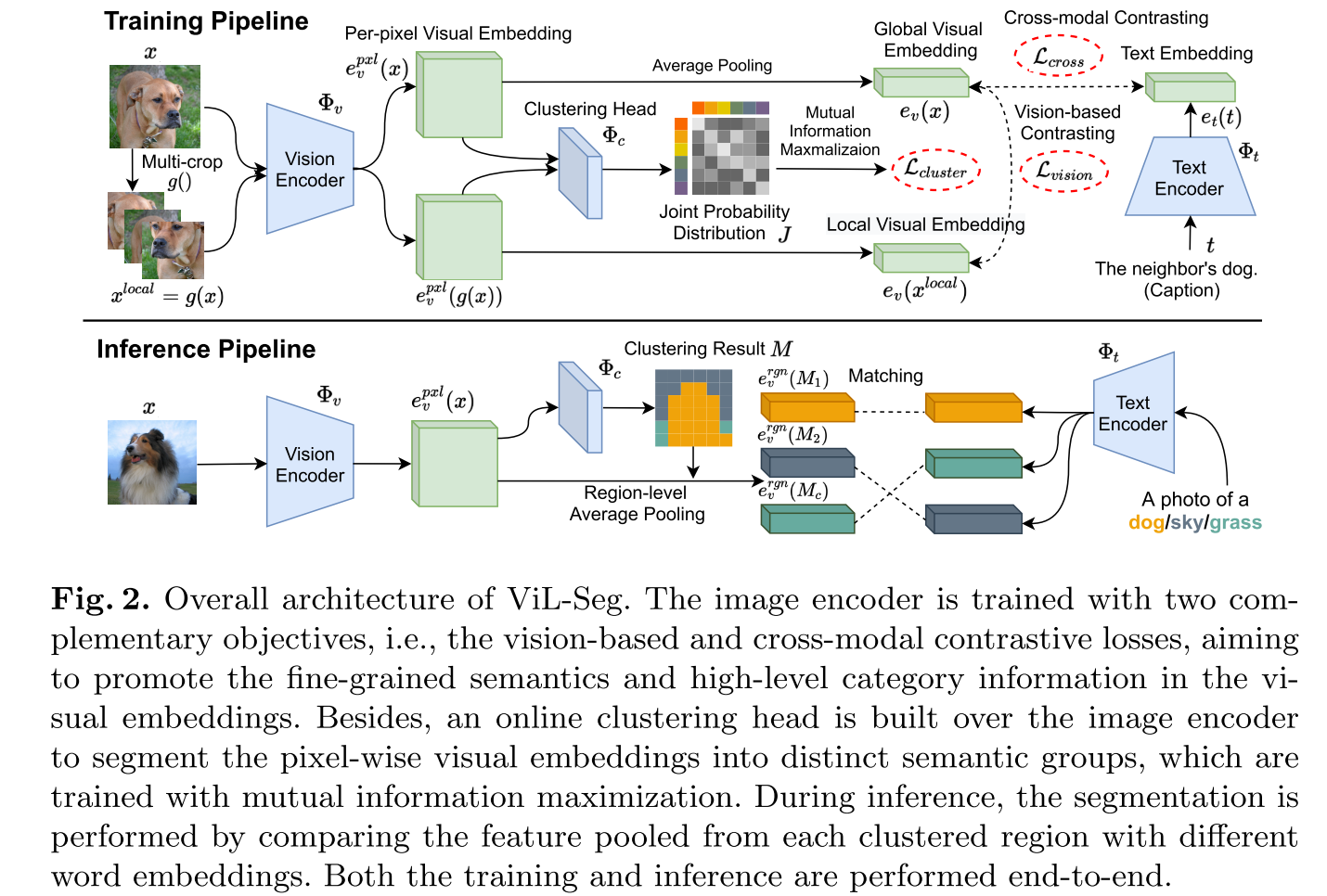
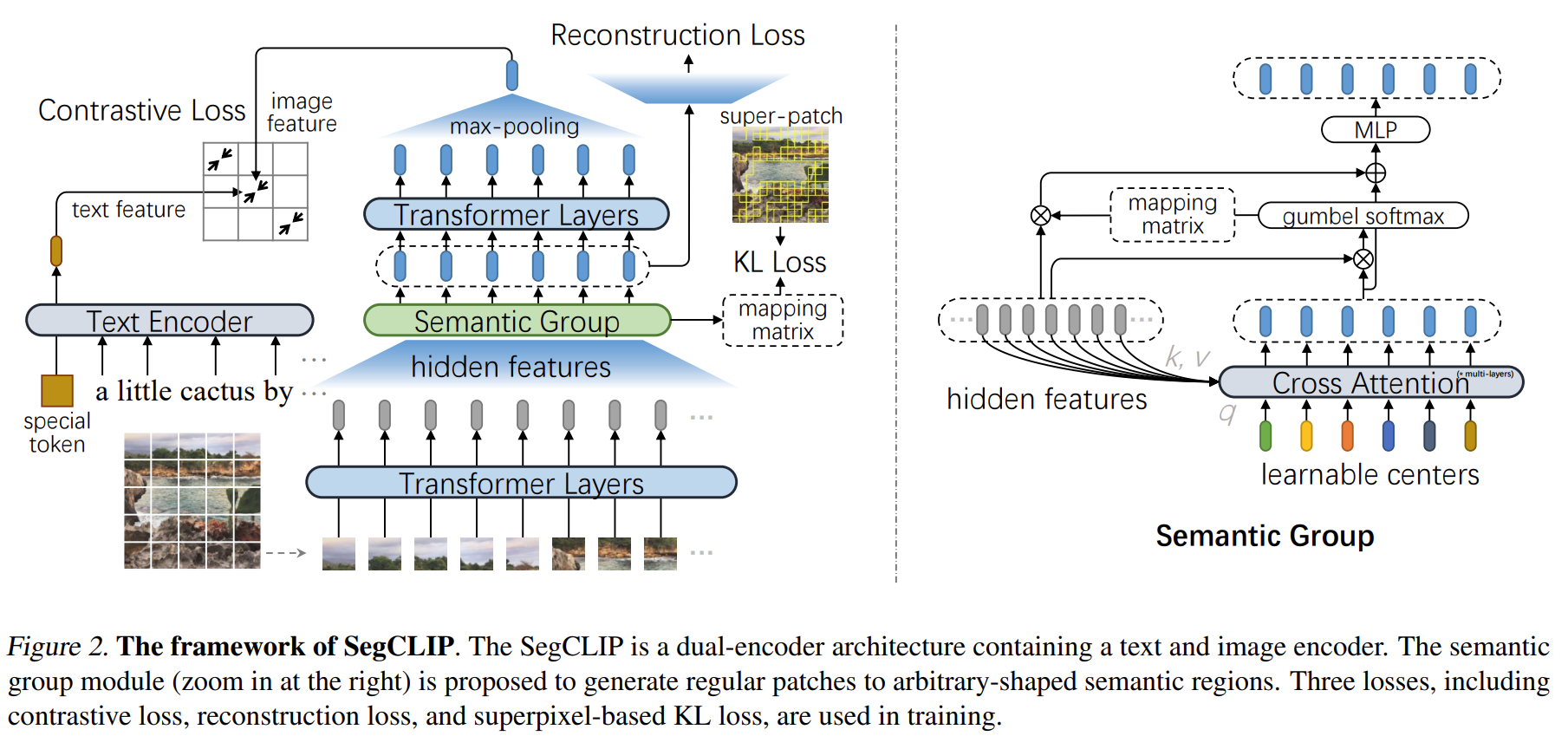
- SegCLIP进一步引入了重建损失和基于超像素的KL损失
Jointly Learning Several Tasks
OVSS,OVIS,OVPS联合训练
- X-Decoder
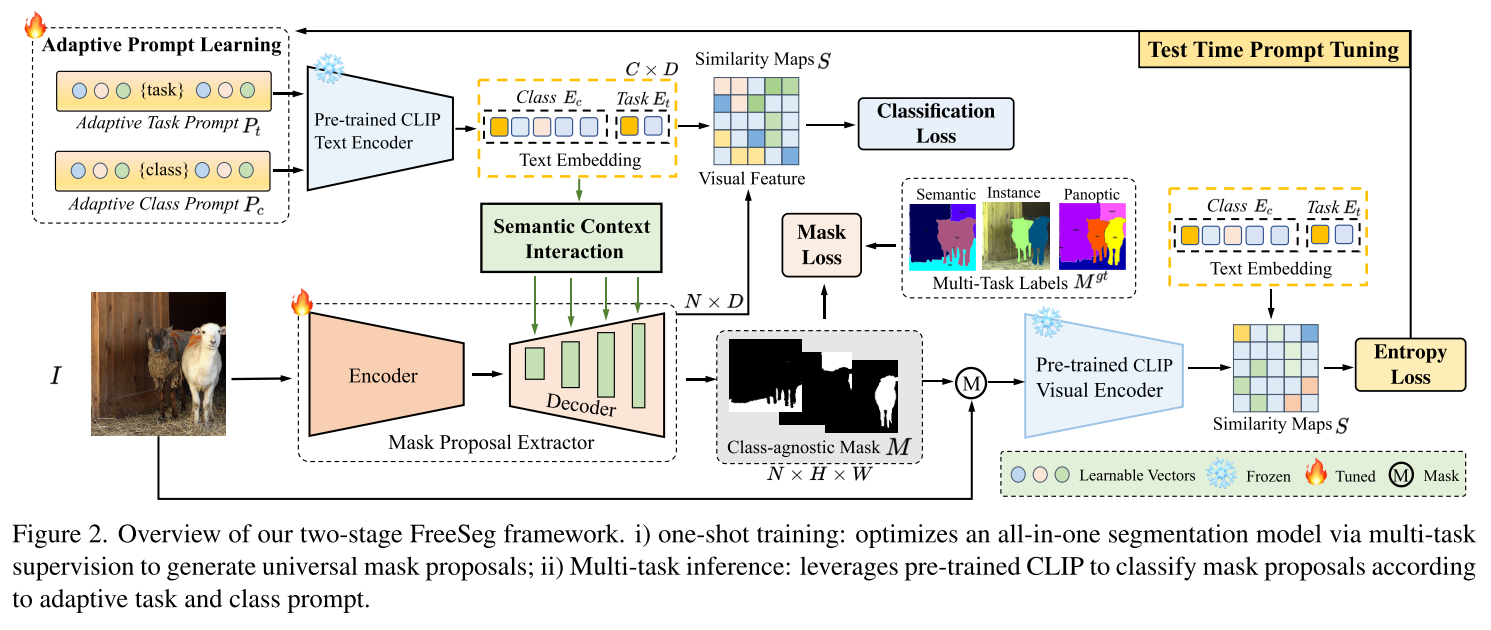
- FreeSeg,统一框架解决三种分割任务,设计了自适应任务提示模块,并对可学习的提示进行测试时间调整,以捕捉特定于任务的特征
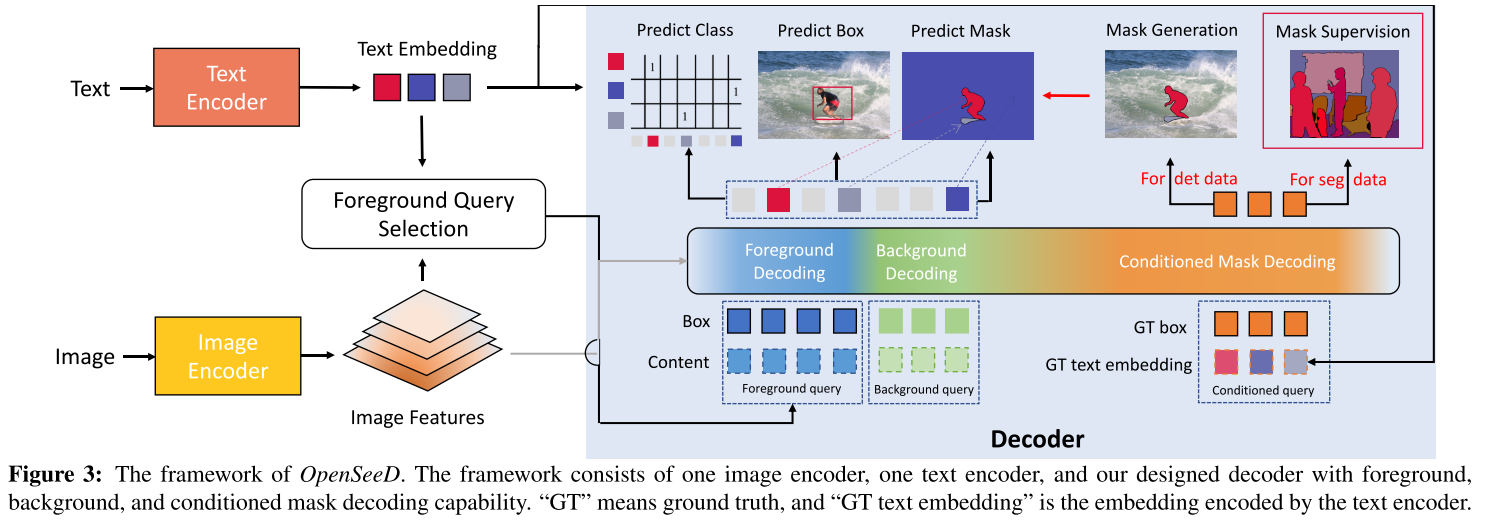
- OpenSeeD同时从检测数据集和分割数据集中学习
Adopting Denoising Diffusion Models
- ODISE利用了diffusion-based generative models的中间特征
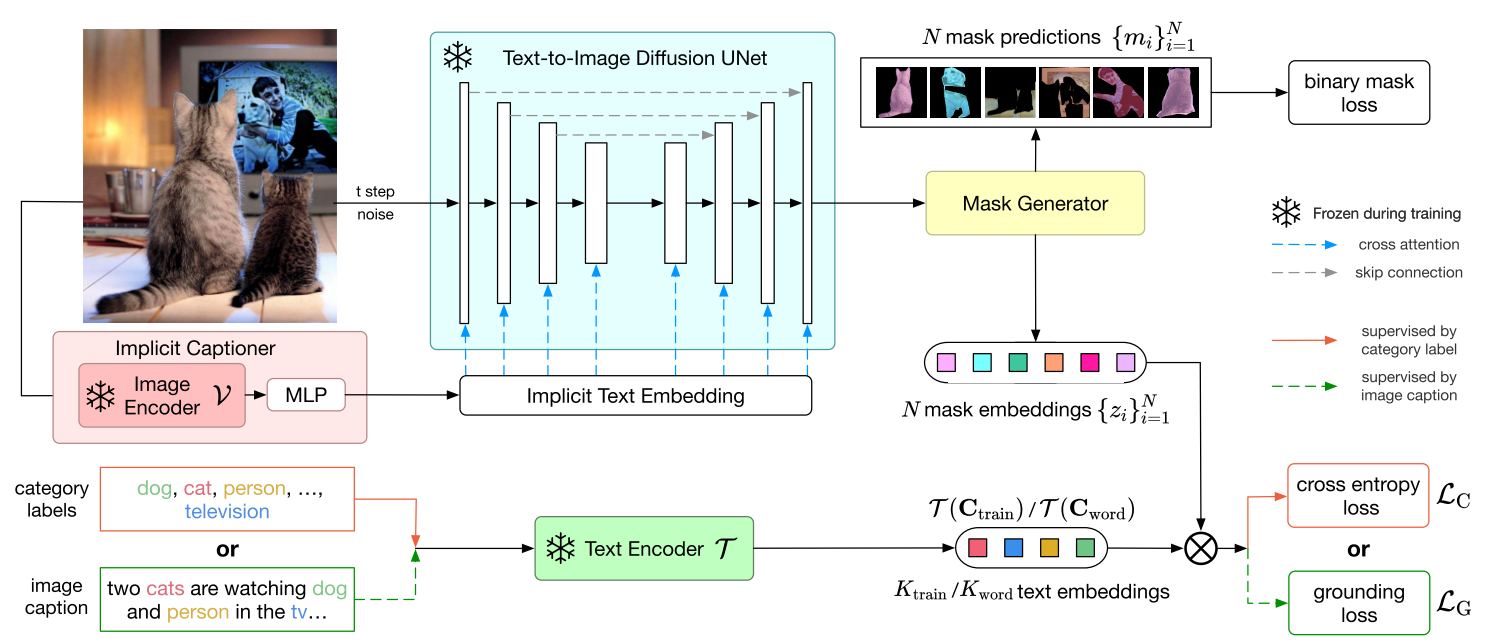
- OVDiff提出了一种基于原型的方法来处理开放词汇语义分割。它使用扩散模型来生成各种类别的图像,并将它们视为原型。该方法不需要训练。在测试期间,将输入图像与这些生成的原型进行比较,并且最匹配的原型类别就是输入图像的预测类。
Open Vocabulary Video Understanding

Open Vocabulary 3D Scene Understanding

3D to 2D projection
将Open Vocabulary机制扩展到3D感知并不简单,因为很难像CLIP在2D感知中所做的那样为point-language对比训练收集足够的数据。
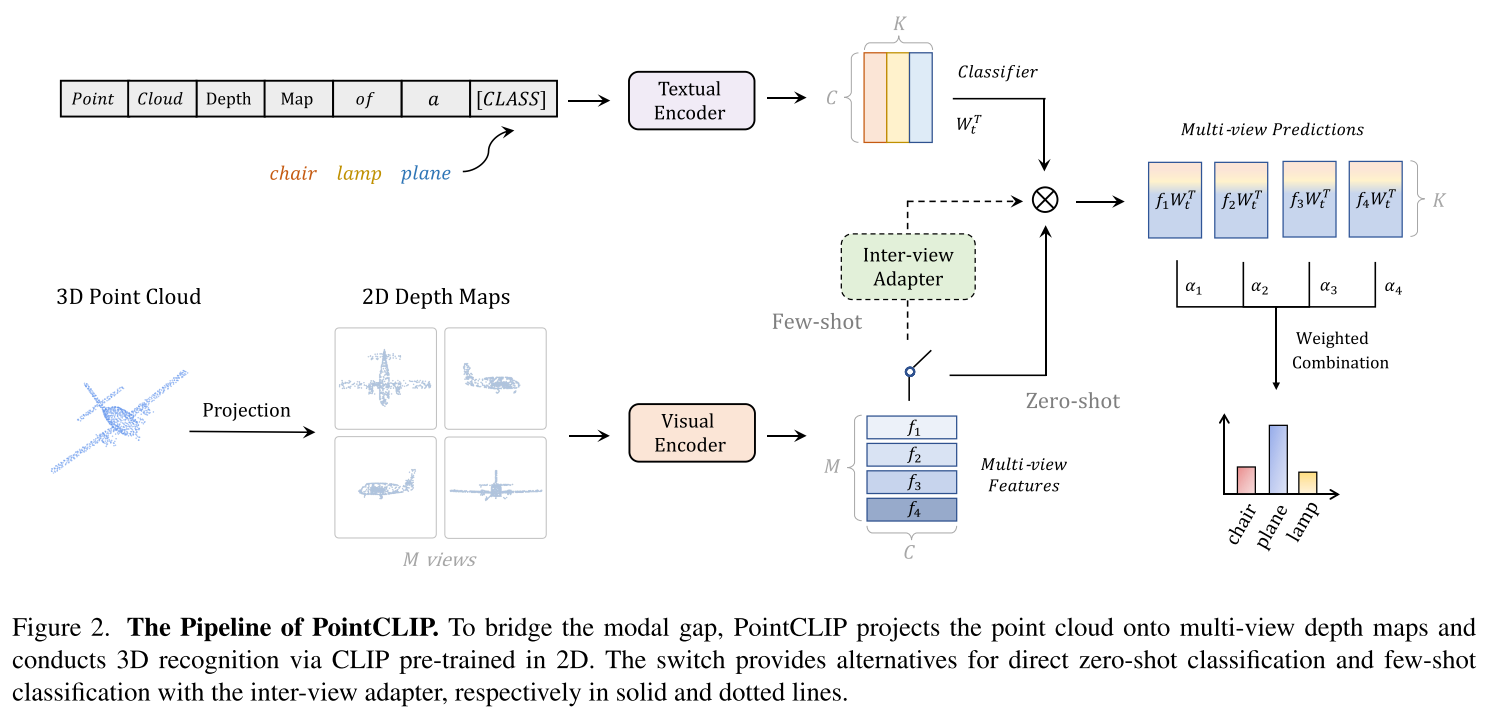
- PointCLIP将3D点云投影到2D平面,并通过CLIP视觉编码器从投影的深度图中提取视觉特征
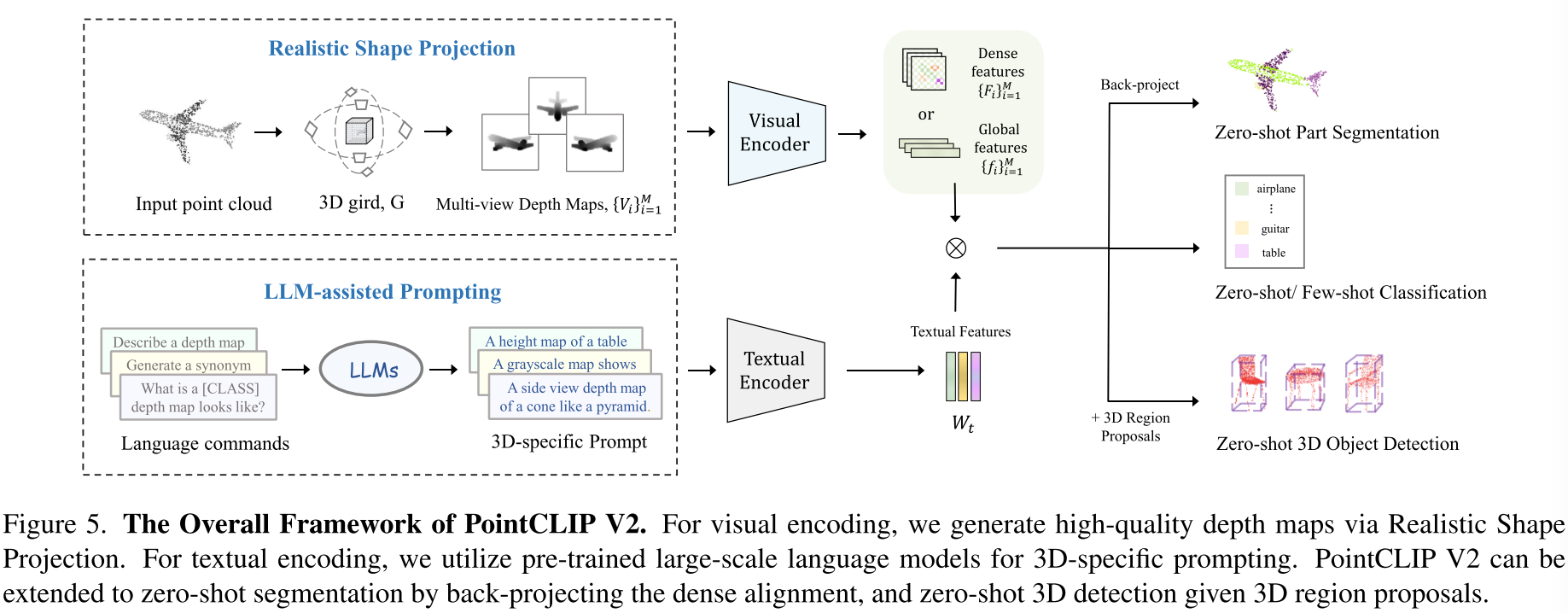
- PointCLIP V2进一步引入了深度图生成和3D prompting
3D and 2D Alignment
将3D点投影到2D可能不能完全利用3D的信息
- ULIP将3Dbackbone提取到的3D特征和CLIP的视觉、文本特征进行对齐
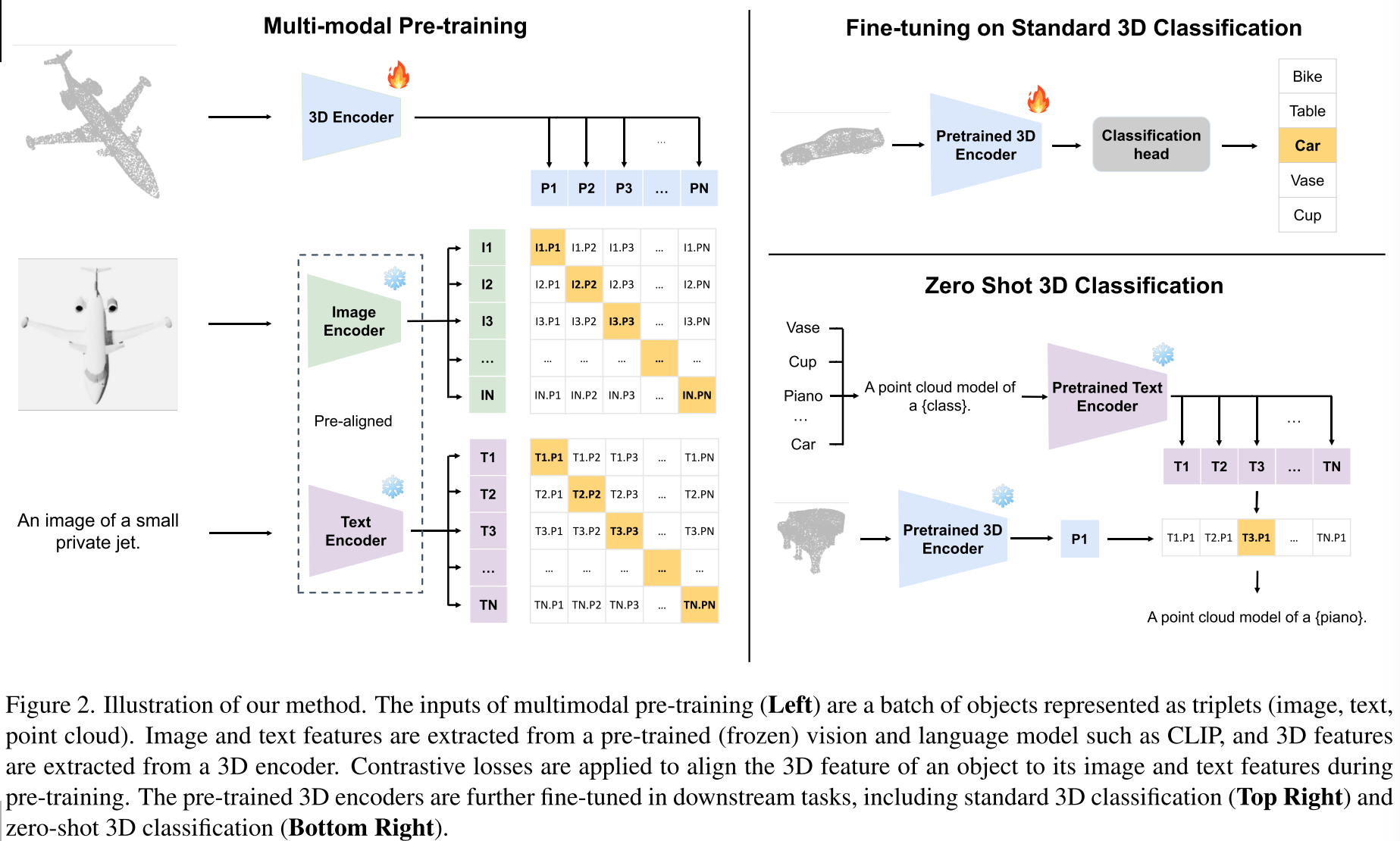
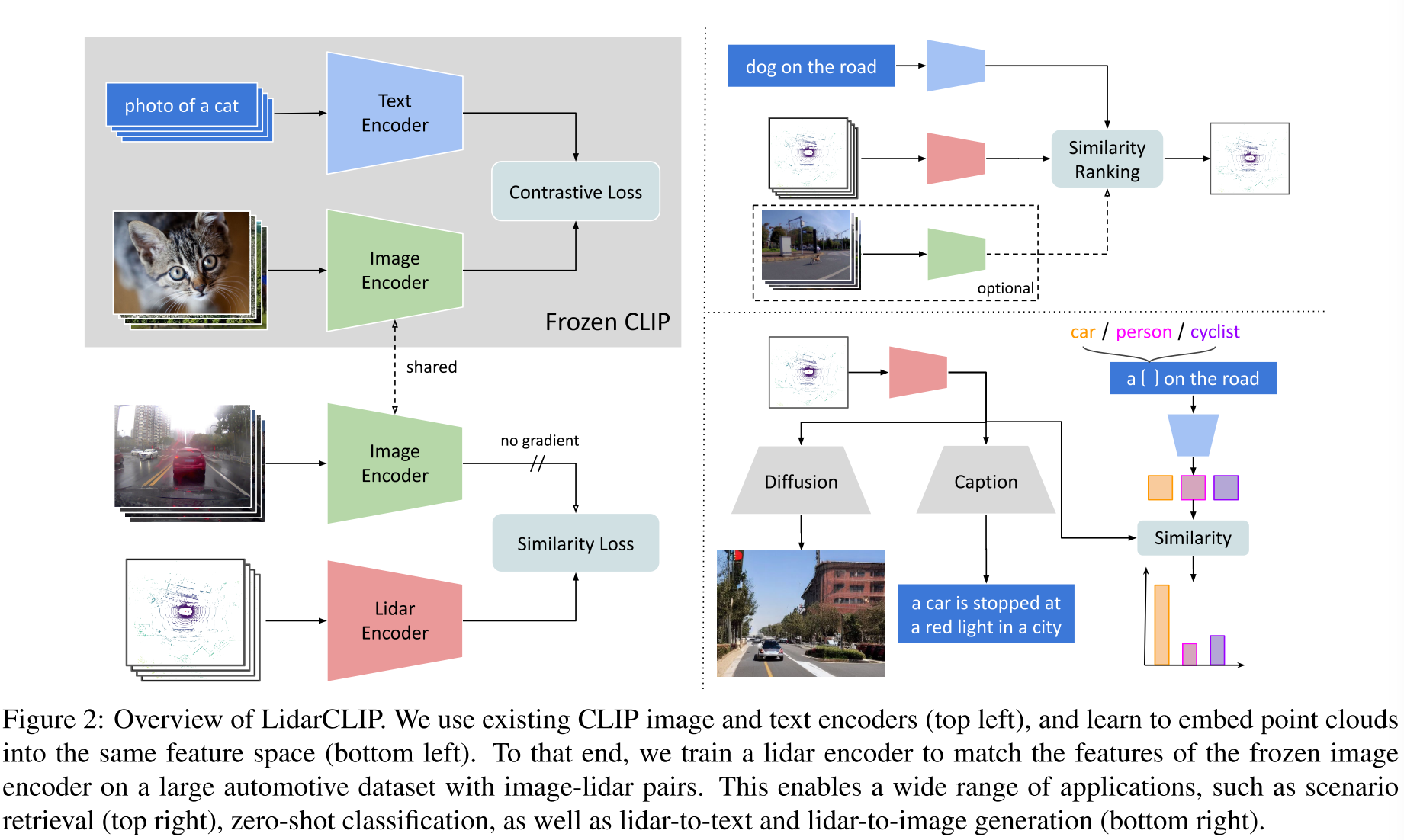
- LidarCLIP对齐3D和2D特征,可以用于3D open vocabulary scene understanding和lidar-to-image generation
Downstream Tasks
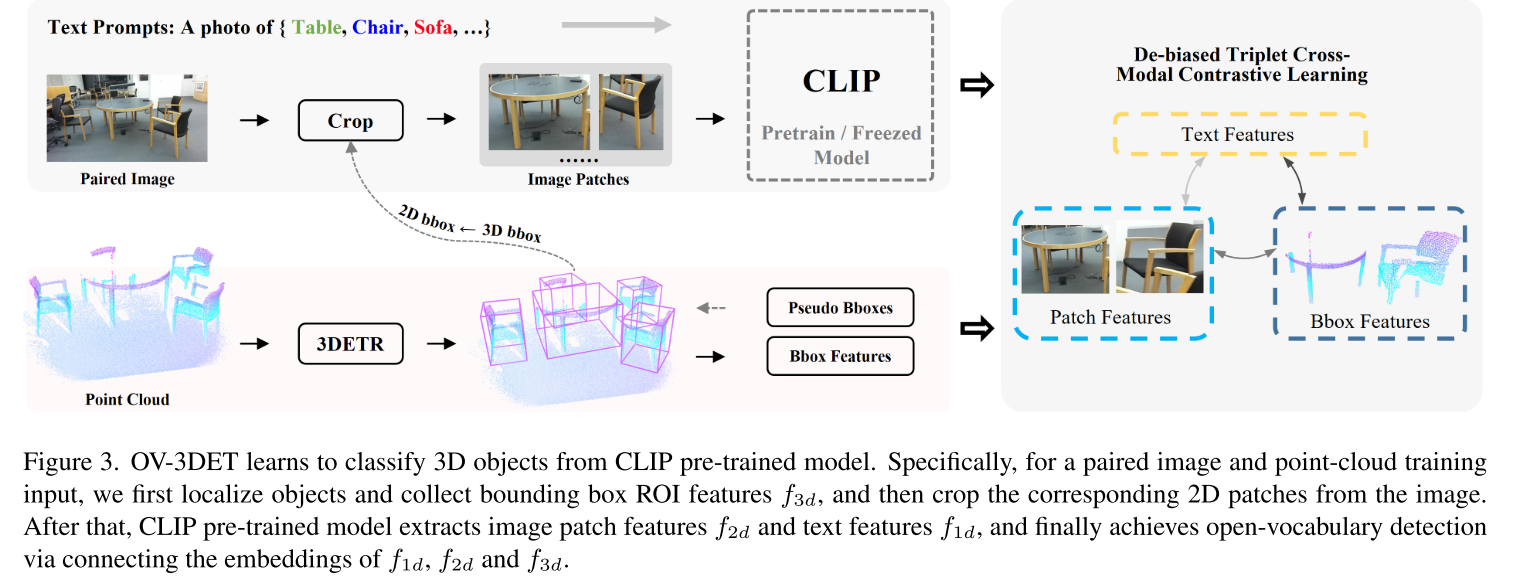
OV-3DETIC将定位和识别解耦到两种图像和点云两种模态中去,点云用于定位,而RGB图像用于识别
OV-3DET
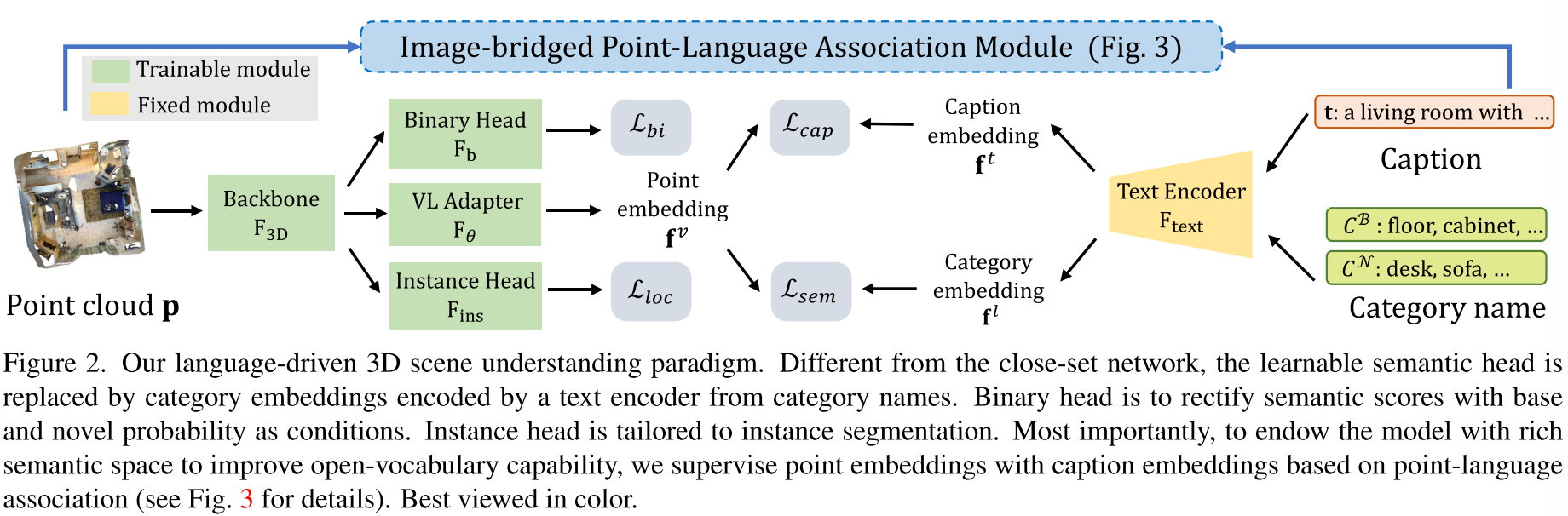
- PLA专注于3D场景理解,使用多视图图像来提取特征用于对比学习
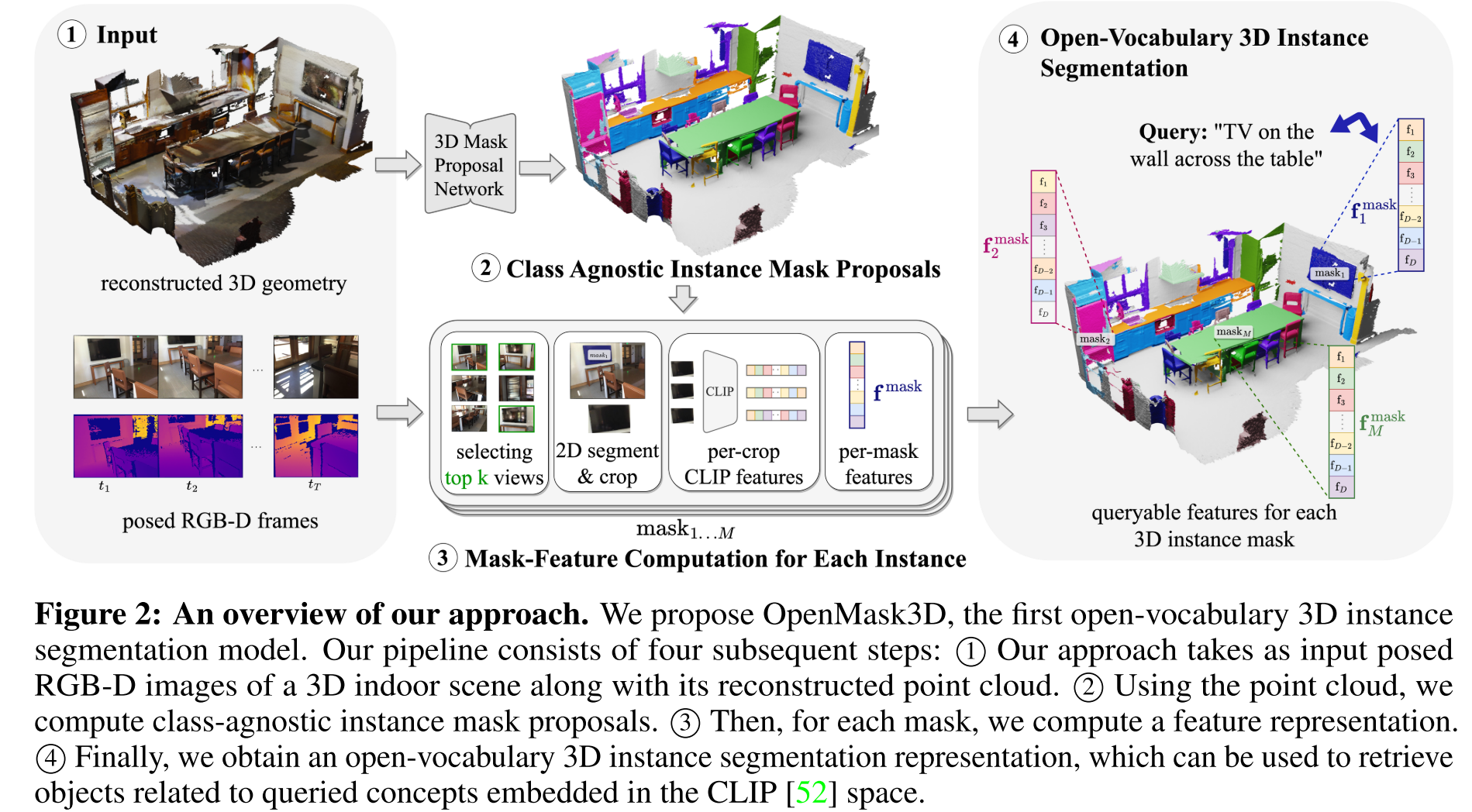
- OpenMask3D(3D实例分割)提出了多视角融合的方法,从point cloud获得类别无关的3D mask proposals,然后再去CLIP特征空间进行检索分类
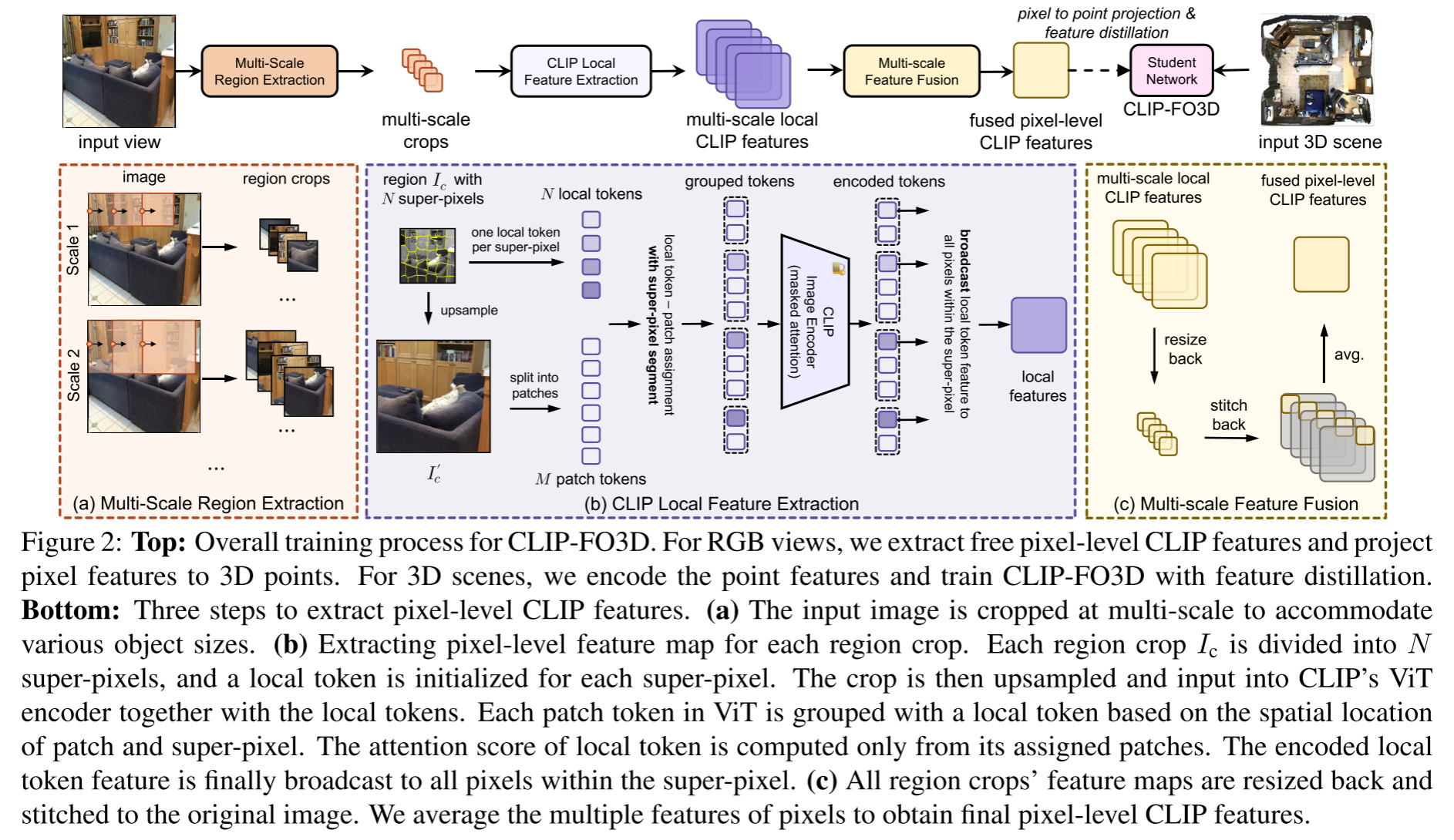
- CLIP-FO3D(3D语义分割)使用了知识蒸馏,直接从CLIP学习知识,不需要额外标注
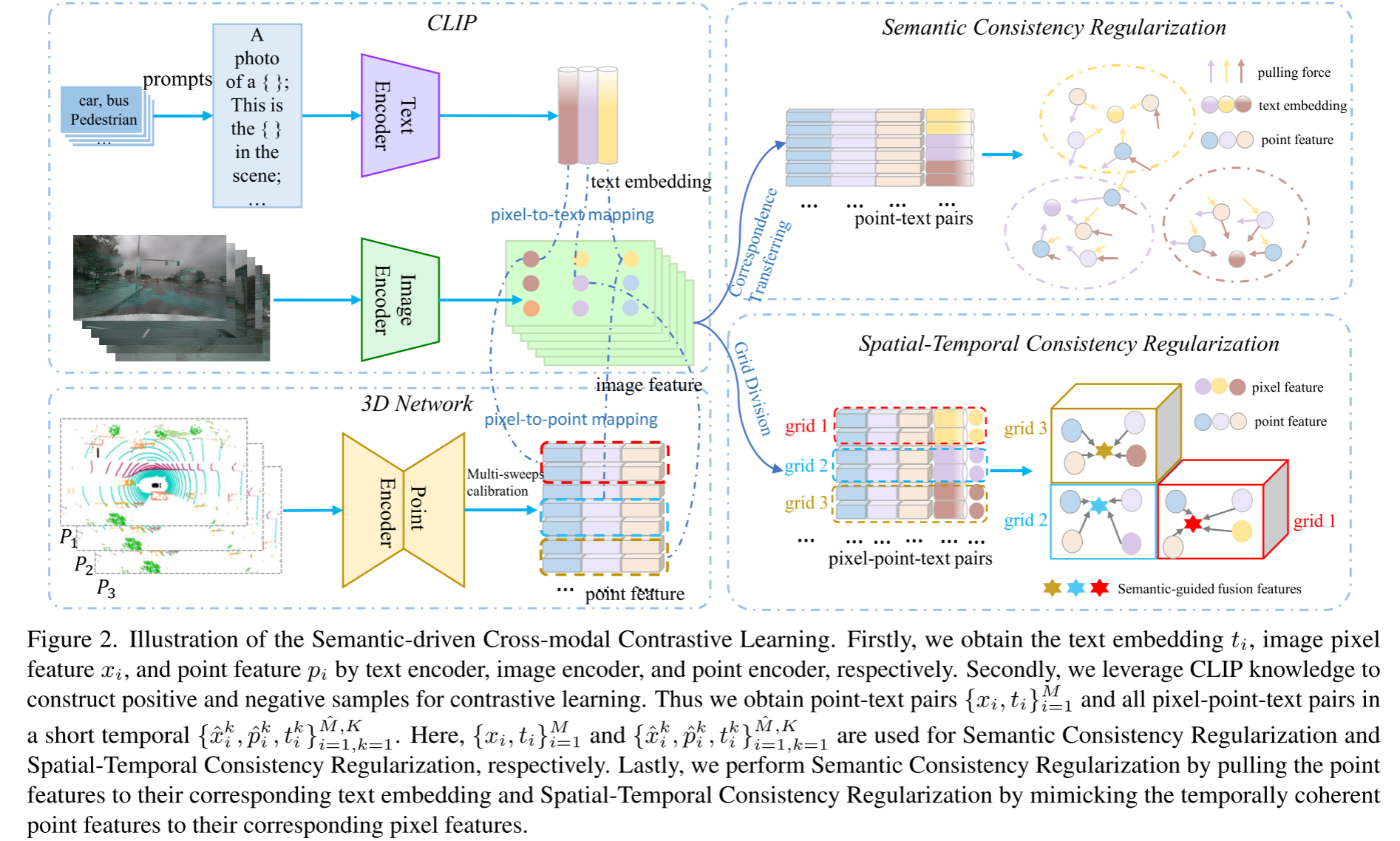
- CLIP2Scene提出通过语义驱动的跨模态对比学习来训练3D网络以进行3D分割
Benchmark Results
Open Vocabulary Object Detection
Setting
- COCO dataset包含80类,48类作为base classes,17类作为novel classes,训练使用107761张图片,包括665387个base类的bbox annotations,测试使用4836张图像,包括28538个base类和novel类的bbox annotations
- LVIS dataset包含1203类,866个常见类作为base类,剩下的377个类作为novel类
Results
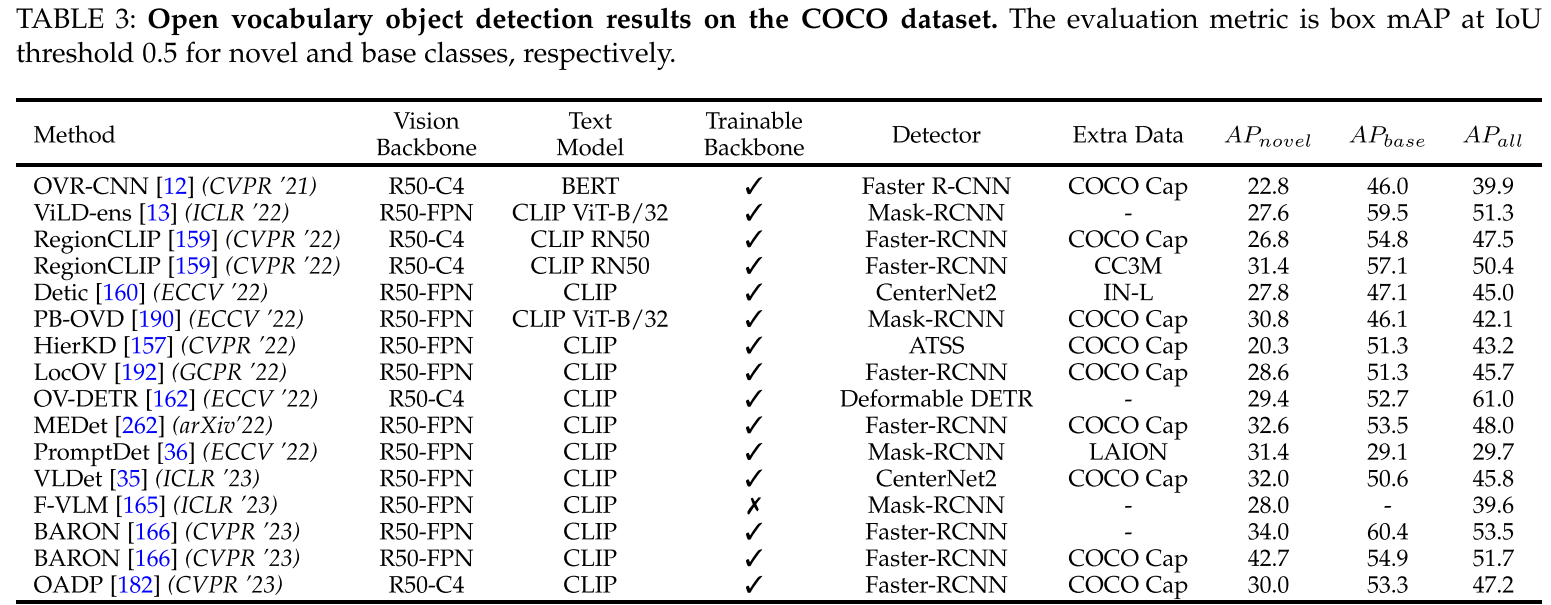
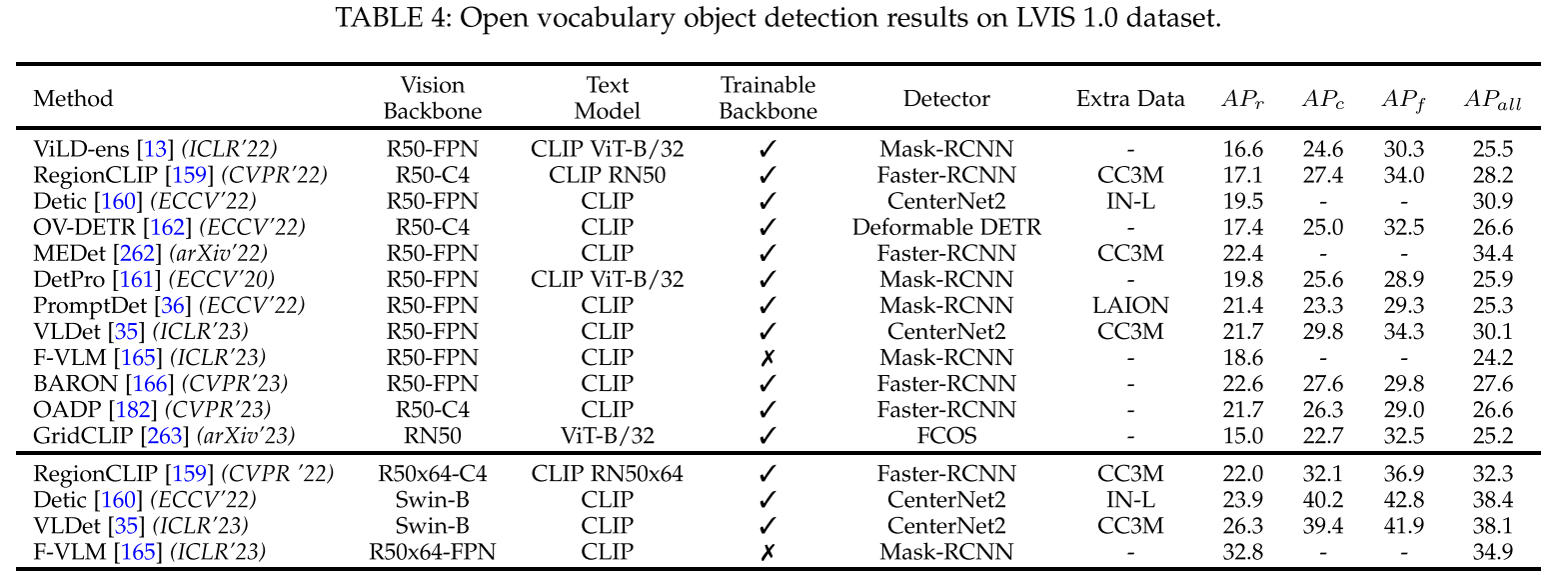
两阶段方法精度明显优于一阶段,BARON使用Faster-RCNN+ResNet-50在COCO上取得42.7$AP_{novel}$,在LVIS上取得22.6$AP_r$
sota方法BARON,FVLM(冻结主干)
Open Vocabulary Semantic Segmentation
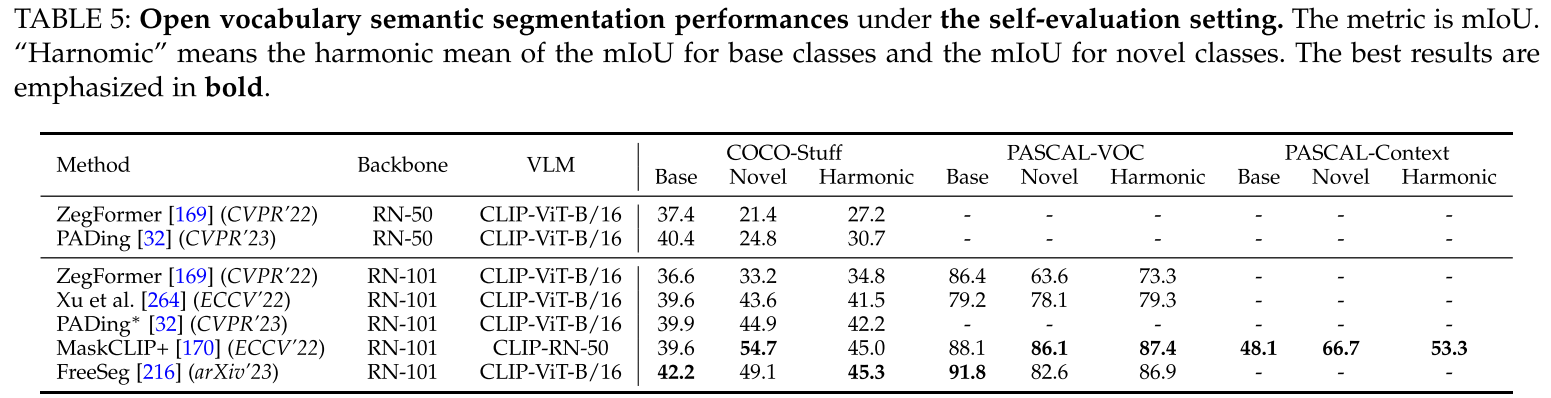
Setting
- ADE20K dataset包含2k张validation images,整个数据集包含2693个前景和背景类
- Pascal Context dataset包含5k张validation images,包含459类
- Pascal VOC有20类被用作evaluation
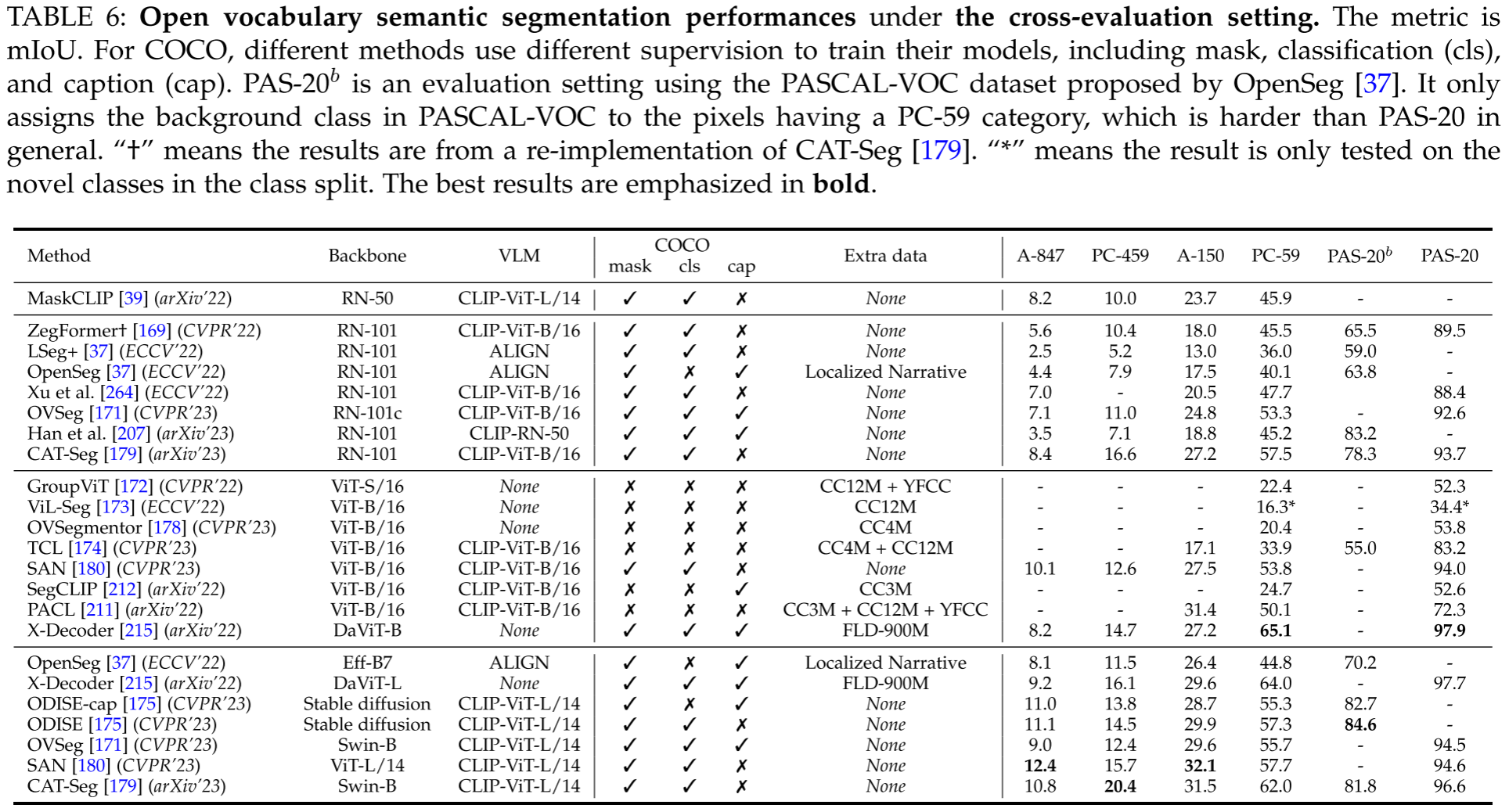
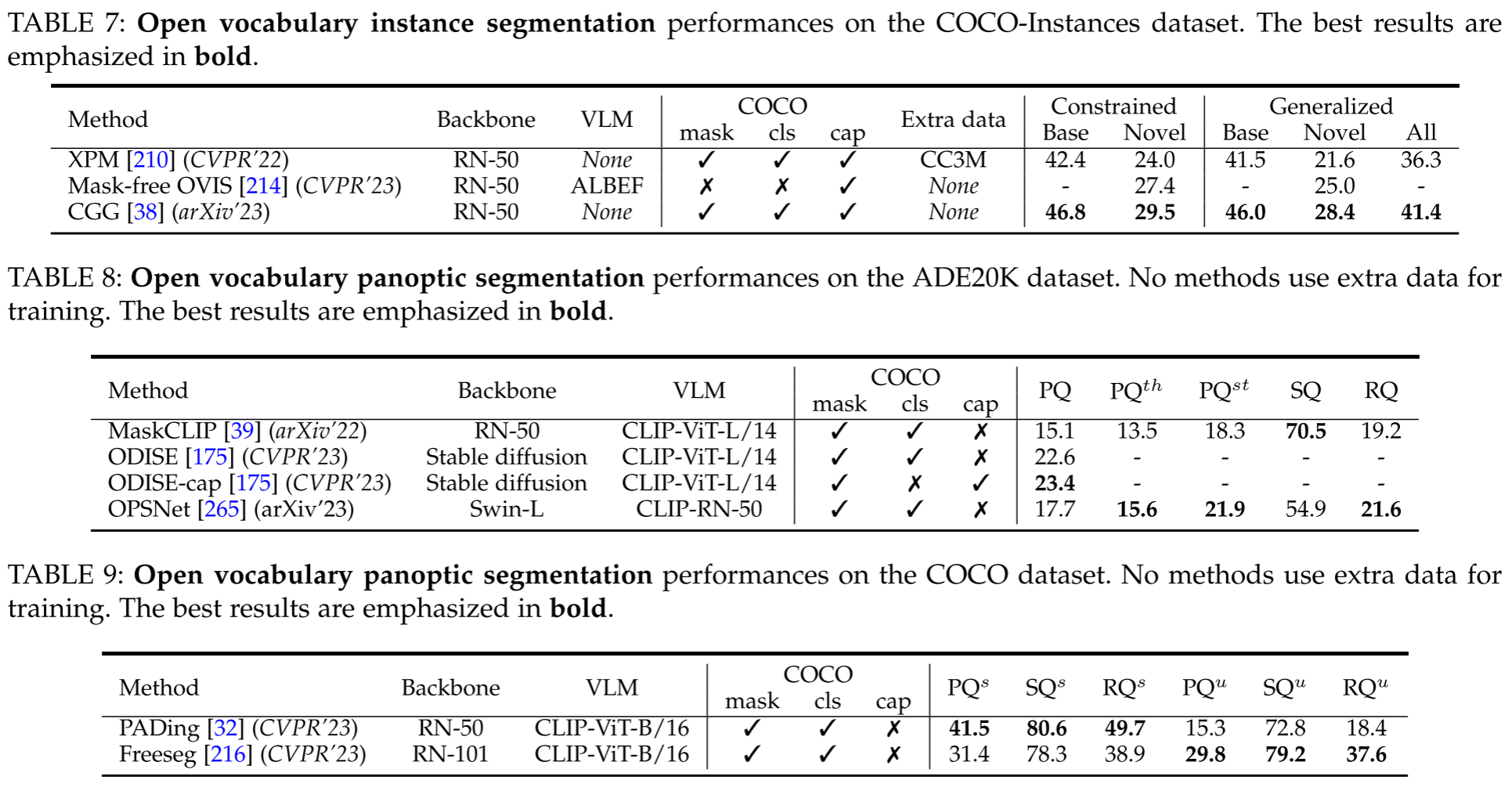
Results
Challenges&Outlook
Explore Temporal Information
视频场景
3D Open Vocabulary Scene Understanding
点云数据标注更加困难,因此将Open Vocabulary引入3D场景非常必要。目前3D open vocabulary scene understanding的解决思路主要集中在设计投影函数来更好的利用2D VLMs,如何将2D模型的知识与3D模型对齐是一个值得探索的方向
Explore Foundation Models With Specific Adapter For Custom Tasks
利用adapter去解决基础模型表现不佳的特定领域的corner case
Efficient Training For Target Dataset
现有的sota方法需要大量的数据进行预训练,在VLM的帮助下设计高效的学习方法是有必要的,一个可能的解决方案是采用in-context learning,充分探索和利用VLM和LLM的知识。
Base Classes Over-fitting Issues
由于模型在基类上训练,因此当出现novel类和base类具有相似形状和语义时,base类的置信度会更高,引入更加细粒度的特征判别建模比如parts和attributes是解决这一问题的潜在方法
Combining with Incremental Learning
在真实的场景中,数据标注通常是开放世界和非平稳的,其中新的类可以连续和增量地出现。但是直接转化为增量学习可能会导致灾难性遗忘问题。另一方面,当前的开放世界对象检测(open world object detection)仅关注novel类的定位,而不进行分类。如何在一个框架内同时处理灾难性遗忘问题和新的类检测问题是值得探索的。