MetaFormer
MetaFormer : A Unified Meta Framework for Fine-Grained Recognition
细粒度视觉分类(FGVC)是一种需要识别属于一个超类别的多个从属类别的对象的任务
Motivation
FGVC的主流方法主要关注如何使网络关注于最具判别性的区域,这类方法将受人类观察行为启发的定位的inductive bias引入到具有精细结构的神经网络。当一些物种在视觉上难以区分时,人类专家经常使用视觉之外的信息来帮助他们进行分类,所以仅使用视觉信息来完成细粒度分类是不合理的
最近的最先进的方法通常设计复杂的学习pipeline来解决这个任务。然而,仅凭视觉信息往往不足以准确区分细粒度的视觉类别。元信息(例如,时空先验、属性和文本描述)通常与图像沿着出现,MetaFormer旨在使用一个统一而简单的框架来利用各种元信息来辅助细粒度的识别。
Methodology
Hybrid Framework
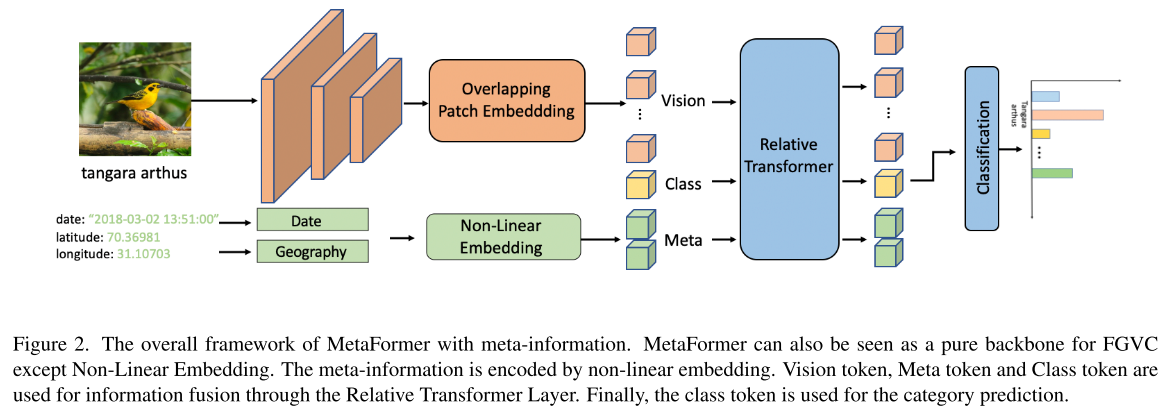
使用卷积来获取视觉信息,用transformer编码meta information和融合信息
由于Transformer的self-attention是置换不变的,不能有效的利用输入序列中token的顺序,因此作者在计算attention时引入了relative position bias $B$:
$\operatorname{Attention}(Q, K, V)=\operatorname{SoftMax}\left(Q K^{T} / \sqrt{d}+B\right) V$
所有额外的tokens(除了图像tokens以外的所有)都共享一个相对位置偏置
Meta Information
地理坐标系转换为直角坐标系
时间映射

- 属性作为meta information时,将属性转换为词向量
Experiments
Datasets
- iNaturalist2017
- iNaturalist2018
- iNaturalist2021
- CUB-200-2011
- Stanford Cars
- Aircraft
- NABirds
Meta Information
- CVL
- KERL