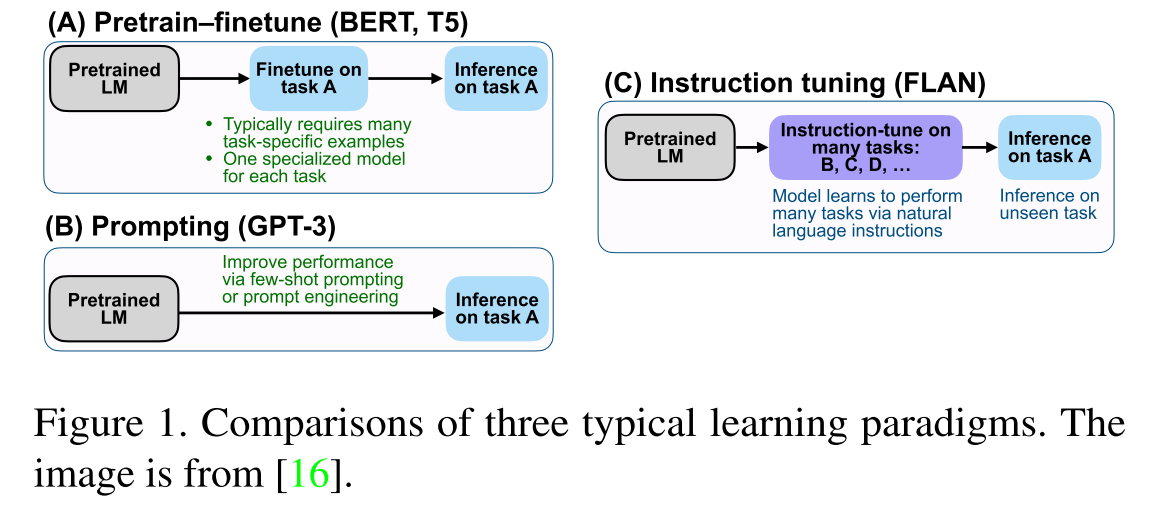
A Survey on Multimodal Large Language Models
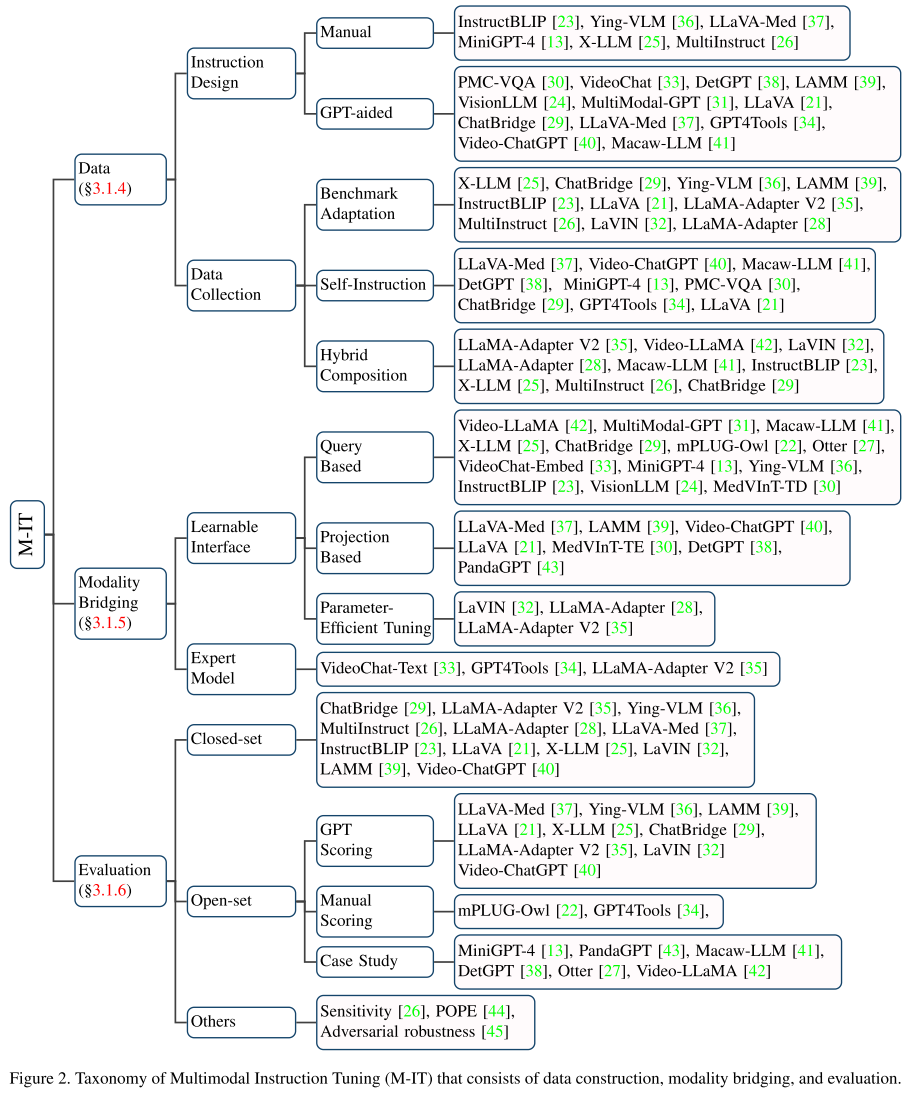
Multimodal Instruction Tuning (M-IT)
Instruction指任务的描述,Instruction tuning是一种在指令格式的数据集集合上对预先训练的LLM进行微调的技术
- Pretrian-finetune需要许多特定于任务的数据来训练特定于任务的模型
- Prompting能够提升few-shot性能,但zero-shot无提升
- Instruction tuning学习如何推广到看不见的任务。此外,指令调整与multi-task prompting高度相关
将Instruction tuning从单模态扩展到多模态,需要对数据和模型结构进行调整:
- 数据方面,对现有的数据集进行调整(如VisionLLM),或self-instruction(如MiniGPT-4)
- 模型方面,通常将其他模态视作是外语注入到LLM中
- 直接在表征空间将外语和LLM特征对齐
- 使用专家模型将其他翻译成LLM可以理解的自然语言
下图是用于构造多模态指令数据的简化模板,< instruction>代表任务的文本描述。{< image>,< text>}和< output>是来自数据样本的输入和输出。在一些数据集可能会丢掉< text>,如image caption数据集仅具有< image>。< BOS>和< EOS>分别表示输入开始和结束的标志。
instruction是描述任务的自然语言的句子,如“Describe the image in detail.”
input可以是图像文本对(VQA)或者只有图像(Image Captioning)
output是以input为条件的instruction的答案

Modality Alignment
通常在M-IT之前会利用大规模的配对数据进行预训练,使不同模态进行对齐。
对齐预训练的常用方法:冻结pre-trained modules(如Visual encoder和LLMs),然后训练一个可学习的接口
Data
收集multimodal instruction-following data是M-IT的关键,收集的方法可以大致分类为:
benchmark adaptation
benchmark datasets是高质量数据的丰富来源
以VQA数据集的变换为例,原始样本是输入-输出对,其中输入包括图像和自然语言问题,并且输出是以图像为条件的问题的文本答案。该指令(即任务的描述)可以从手工设计或从GPT辅助的半自动生成中获得。
下图是VQA的一些指令模板

由于现有VQA和caption数据集的答案通常是简短的,直接使用这些数据集进行instruction tuning可能会限制MLLM的输出长度,有两个常用策略来解决这个问题:
- 修改指令,如ChatBridge对于短回答显式声明了short and brief, InstructBLIP则在公共数据集(通常更倾向于简短的回答)的指令模板中加入了short and briefly
- 延长现有答案的长度,如M^3^IT通过向ChatGPT提示原始问题、答案和上下文来改写原始答案
self-instruction
现有的benchmark datasets提供了丰富的数据源,但是通常不能满足实际需求,如多轮对话,为解决这一问题,提出通过self-instruction来收集样本
- 基于LLMs使用少量手工标注的样本来生成文本指令跟随数据。具体来说,一些手工设计的指令跟随样本被作为种子示例,之后ChatGPT/GPT-4被提示以种子示例为指导生成更多指令样本。
- LLaVA 通过将图像转换为标题和边界框的文本,并鼓励GPT-4在种子示例的上下文中生成新数据,将self-instruction方法扩展到多模态领域。以这种方式,构建了称为LLaVA-Instruct-150k的M-IT数据集。
- 后续的工作也遵循了类似的想法,如MiniGPT-4,ChatBridge,GPT 4 Tools和DetGPT开发了不同的M-IT数据集,以满足不同的需求
- 基于LLMs使用少量手工标注的样本来生成文本指令跟随数据。具体来说,一些手工设计的指令跟随样本被作为种子示例,之后ChatGPT/GPT-4被提示以种子示例为指导生成更多指令样本。
hybrid composition
除了M-IT数据之外,language-only user-assistant conversation data也可以用于提高会话熟练度和指令跟随能力
Modality Bridging
由于LLMs只能感知文本,因此有必要弥合自然语言和其他模态间的gap,但是端到端的方式训练一个多模态模型是非常昂贵的,而且可能会导致灾难性遗忘,所以更现实的做法是在pre-trained visual encoder和LLM之间引入可学习的接口,或者借助专家模型将图像翻译成语言,再送给LLM。
可学习接口
可学习接口负责在冻结预训练模型的参数时连接不同的模态。挑战在于如何有效地将视觉内容翻译成LLM可以理解的文本。
- 利用一组可学习的query tokens以查询的方式来提取信息(Flamingo and BLIP-2)
- 基于投影的接口(linear layer),缩小模态间的差距(LLaVA)
- parameter-efficient tuning manner(LLaMA-Adapter,LaVIN)
专家模型
利用专家模型,如image captioning模型来减小模态间的差距,使用专家模型的方式简单,但是缺点在于会造成信息损失
Evaluation
M-IT的评估方法根据问题类型可以分为closed-set和open-set两种
Closed-set
可能的答案选项是预定义的,且是有限的
Open-set
手工评分、GPT评分和案例研究
Multimodal In-Context Learning (M-ICL)
In-Context Learning的两个优点:
- 不同于传统的监督学习从大量数据中学习表征,ICL的关键是类比学习,举一反三。具体来说,在ICL setting中,LLMs从一些例子和可选指令中学习,并推断出新的问题,从而以很少的方式解决复杂和看不见的任务
- ICL通常以无需训练的方式实现,因此可以在推理阶段灵活地集成到不同的框架中。与ICL密切相关的技术是指令调优(instruction tuning),经验证明了它可以增强ICL能力。
在MLLM的背景下,ICL已经扩展到更多的模态,产生了多模态ICL(M-ICL)
下图是一个M-ICL的样例模板,为了说明,作者列出了两个in-context示例和一个由虚线划分的query。{instruction}和{response}是数据样本中的文本。< image>是表示多模态输入的占位符(在本例中为图像)。< BOS>并且< EOS>是分别表示输入的开始和结束。(模型对样例的排列顺序也很敏感)

M-ICL有了两个主要的应用场景:
- 解决各种视觉推理任务
- LLM从说明和演示中提供的信息了解任务正在做什么以及输出模板是什么,并最终生成预期的答案
- 教LLMs去使用外部工具
- 工具使用的示例通常是纯文本的,而且粒度更细。它们通常包括可以顺序执行以完成任务的一系列步骤。因此,第二种情况与CoT密切相关
Multimodal Chain of Thought (M-CoT)
CoT是一系列中间推理步骤,主要思想是促使LLM不仅输出最终答案,还输出导致答案的推理过程,类似于人类的认知过程。
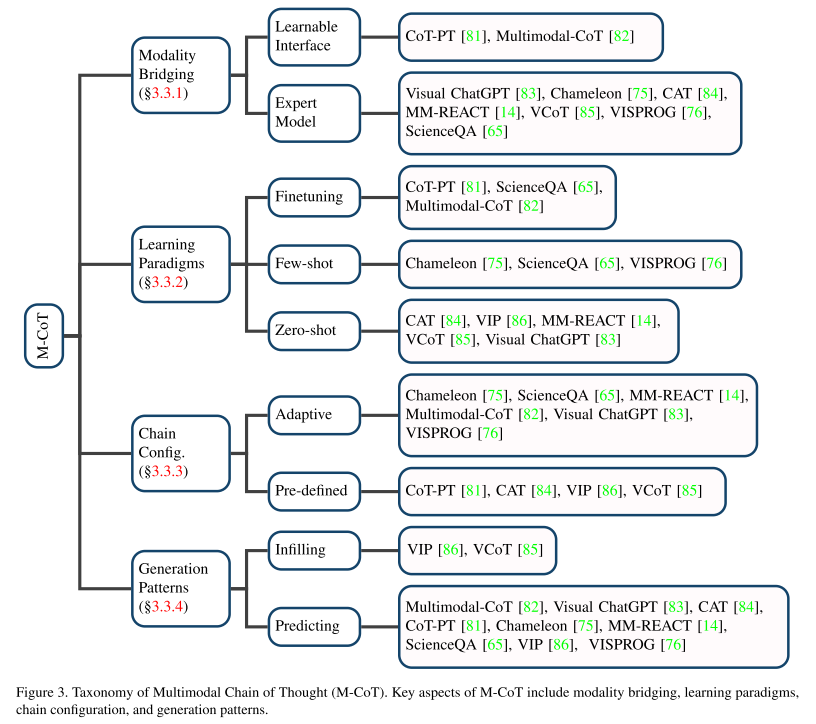
Modality bridging
减小不同模态间的差距(同M-IT中的分析)
- 可学习的接口(通过对特征进行融合)
- 专家模型(通过将视觉输入转换成文本描述)
Learning Paradigms
三种获取CoT的学习范式
finetuning
使用特定的数据集,如ScienceQA
- Multimodal-CoT使用ScienceQA进行训练,且遵从2阶段范式,先生成推理步骤,再基于推理步骤生成最终答案
- CoT-PT组合了prompt tuning和step-specific visual bias来学习隐式的推理链
training-free few-shot learning
需要手工制作一些上下文示例
training-free zero-shot learning
Let’s think frame by frame
Let’s think step by step
Chain Configuration
- 自适应:让LLM自己决定何时停止
- 预定义:在达到预定义推理长度后停止
Generation Patterns
如何构建思维链
- infilling-based:在周围的上下文(先前和后续步骤)之间推导步骤,以填补逻辑空白
- predicting-based:在给定的条件下扩展推理链,例如指令和先前的推理历史
LLM-Aided Visual Reasoning (LAVR)
用LLM辅助进行视觉推理
相比传统的视觉推理模型,LAVR具有以下优点:
- 强大的泛化性
- 涌现能力,可以完成复杂抽象的任务,如解释一个笑话为什么是有趣的
- 可以提供更好的交互性和控制
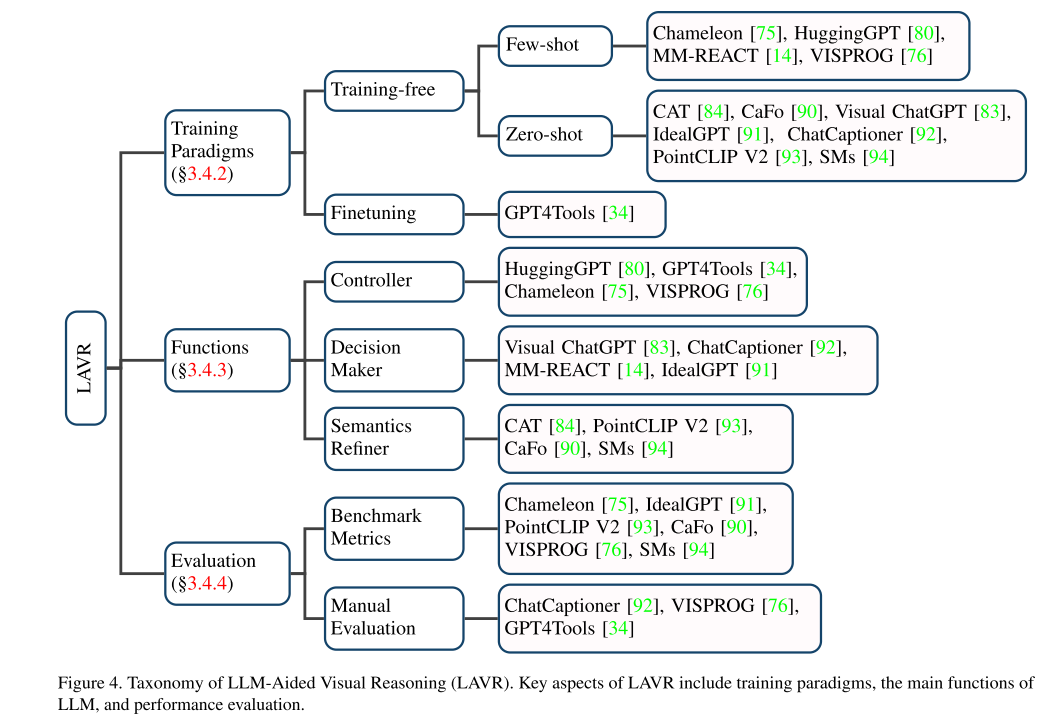
Training Paradigms
training-free
为了保留大模型中的大量知识,直接且简单的方法就是直接冻住模型,为模型提供不同的prompt来满足不同的需要
- few-shot models需要一些手工制作的in-context samples来引导LLMs来生成程序或者一系列执行步骤,把这些生成的程序或一系列执行步骤作为对应的基础模型或外部工具的指令
- zero-shot models则直接利用LLMs的知识或推理能力,如PointCLIP V2提示GPT-3生成具有3D相关语义的描述,以更好地与相应图像对齐
finetuning
- GPT4Tools引入instruction-tuning来提升与工具使用相关的规划能力并提高系统的指令跟随能力
Functions(LLMs在LACR扮演的角色)
LLM as a Controller
- 将复杂任务分解为更简单的子任务/步骤:利用CoT,基于prompt使LLM输出任务规划或模块的调用
- 将这些任务分配给适当的工具/模块
LLM as a Decision Maker
复杂的任务以多轮的方式解决,通常以迭代的方式解决
- 总结当前上下文和历史信息,并决定在当前步骤可用的信息是否足以回答问题或完成任务
- 组织和总结答案,以用户友好的方式呈现
LLM as a Semantics Refiner
当作为semantics refiner时,主要是要利用LLMs丰富的语义知识,用于将信息整合到流畅的自然语言句子中,或者按照定制需求生成文本
Evaluation
- Benchmark Metrics: 如ScienceQA,VCR等
- Manual Evaluation:人工评级
Challenge and Future Directions
- MLLMs的感知能力仍然受限,这导致对于视觉信息的获取是不完整或不正确的,这可能是由于信息容量和计算负担之间的折衷。比如Q-Former只使用32个可学习的tokens来表示图像,这可能会导致信息丢失。按比例增加tokens size将不可避免地给LLM带来更大的计算负担,LLM的输入长度通常是有限的。一种潜在的方法是引入大型视觉基础模型,如SAM,以更有效地压缩视觉信息
- MLLMs的推理链可能是脆弱的,单模态的LLM的推理能力可能不等于接收视觉信息之后的LLM的推理能力
- MLLMs的指令跟随能力需要提升,在M-IT之后,一些MLLM无法生成预期的答案(“yes”或“no”),尽管有明确的指令“请回答yes or no”。这表明,指令调整可能需要覆盖更多的任务,以提高泛化能力
- 对象幻觉现象普遍存在(object hallucination issue),这影响了MLLMs的可靠性,这可能归因于对齐预训练不足。因此,一种可能的解决方案是在视觉模态和文本模态之间执行更细粒度的对齐。细粒度是指图像的局部特征,可以通过SAM获得,以及相应的局部文本描述
- 需要参数高效的训练。现有的两种模态桥接方式,可学习的接口和专家模型,是减少计算负担的初步探索。更有效的训练方法可以在具有有限计算资源的情况下释放更多的MLLMs的性能