VisionLLM
本文提出了基于LLM的的框架,用以解决以视觉为中心的任务
VisionLLM通过将图像视作语言并将以视觉为中心的任务与可以使用语言指令灵活定义和管理的语言任务对齐,为视觉-语言任务提供了统一的视角,基于LLM的解码器可以基于这些语言指令对开放式的任务进行预测
Motivation
Vision Foundation Models仍然受限于预训练范式,难以和LLMS的开放任务能力相匹配
由于模态和任务范式的固有差异,LLM并不能很好的拓展到纯视觉和视觉语言任务
预训练-微调的范式伴随着显著的边际成本
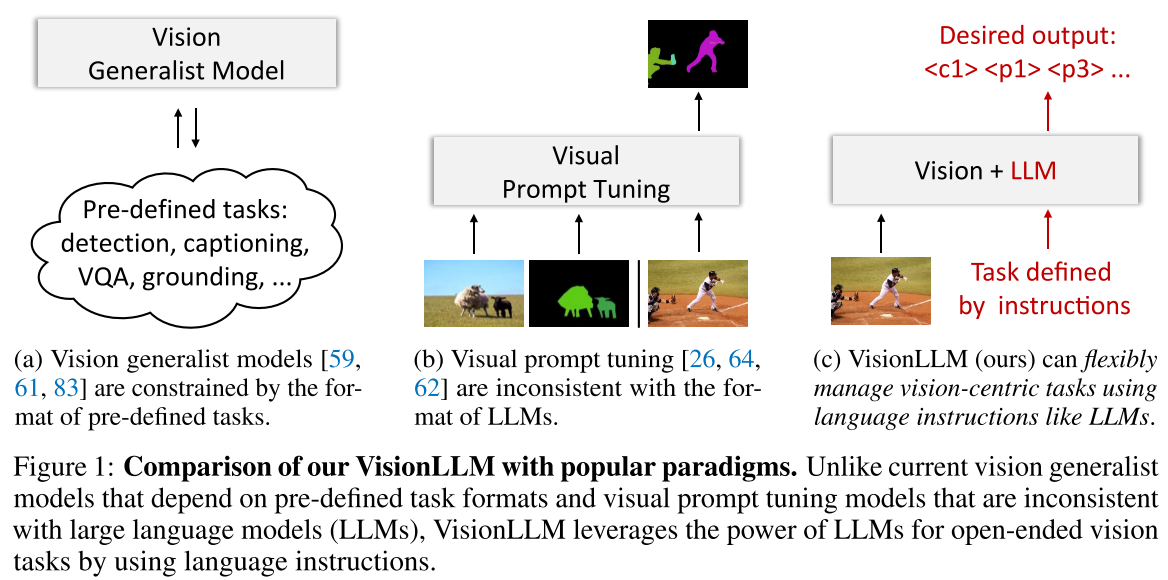
- (a) Vision generalist models:多任务统一方法被用于实现通才能力,但它们往往难以克服预定义任务所带来的限制,导致在开放式能力方面与LLMs存在差距
- (b) visual prompt tuning(VPT):视觉提示的格式与语言指令的格式非常不同,使得直接将LLM的推理能力和世界知识应用于视觉任务具有挑战性。
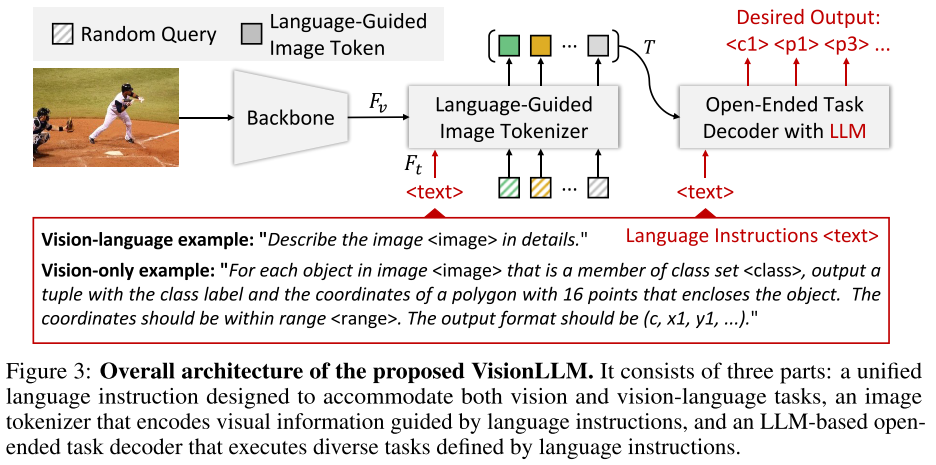
VisionLLM是一个统一的通才框架,将视觉为中心的任务定义与LLMs的方法对齐,利用LLM的推理能力和解析能力为视觉为中心的任务提供开放式任务功能,其包含3个核心组成部分:
- 为视觉和视觉语言任务设计的统一语言指令
- 语言引导的image tokenizer
- 基于LLM的开放式任务解码器:使用语言指令实现各种任务
使用语言指令完成了对多任务的定义,并可以定制输出
COCO上实现60+% mAP,超过mask rcnn,deformable detr等并接近sota

Related Work
- Large Language Model:LLM的出现也为解决以视觉为中心的任务开辟了基于API的应用程序。这些应用程序将可视化API与语言模型集成在一起,以实现基于可视化信息的决策或规划,例如Visual ChatGPT,MM-REACT,HuggingGPT,InternGPT和VideoChat。然而,尽管使用基于语言的指令来定义任务和描述视觉元素很方便,但这些交互式系统在捕获细粒度视觉细节和理解复杂视觉上下文方面仍然面临限制,这阻碍了它们有效连接视觉和语言模型的能力。总之,虽然LLM在各种NLP应用中显示出巨大的潜力,但其对以视觉为中心的任务的适用性受到模态和任务格式所带来的挑战的限制。
- Vision Generalist Model:通才模型旨在使用一个共享的框架和参数来处理各种各样的任务,但受到预定义任务的限制,并且不能支持基于LLM等语言指令的灵活的开放式任务定制。
- Instruction Tuning
Methodology
- 统一语言指令,为以视觉为中心的任务定义和定制提供一致的接口
- 语言引导的图像标记器(image tokenizer),将视觉信息编码为与给定语言提示一致的特征,使得模型能够有效地理解和解析视觉内容
- 基于LLM的开放任务解码器,利用编码的视觉信息和语言指令来生成令人满意的预测或输出
Unified Language Instruction
引入统一的语言指令,使得各种视觉和视觉语言的任务描述统一,并允许灵活的任务定制。
视觉-语言任务
- image captioning:“The image is < image>. Please generate a caption for the image: ”
- VQA:“The image is < image>. Please generate an answer for the image according to the question: < question>”
视觉任务:通过提供任务描述并通过语言指令指定所需的输出格式来描述视觉任务
- 通过任务描述把预期任务传达给语言模型。VisionLLM设计了一组带有占位符的种子指令,并使用LLMs来生成大量相关的任务描述,在训练期间随机选择其中一个
- 对于检测、分割等传统感知任务,本文提出了一个统一的输出元组格式$(C,P)$,其中$C$表示类别集中的类索引< class>,$P = \{xi,yi\}^N_{i=1}$表示定位对象的N个点。为了和word tokens的形式对齐,类索引$C$和点$xi,yi$的坐标都被转换成离散的tokens,具体来说,类索引是从0开始的整数,并且点的连续坐标被均匀地离散为范围$[-
, ]$内的整数。对于目标检测来说,点数N等于2,表示对象的边界框的左上和右下点。在实例分割的情况下,作者采用沿着对象边界的多个点($N>8$)来表示实例掩模。如姿态估计(关键点检测)的其他感知任务也可以以这种方式被公式化为语言指令。
实例分割语言指令的例子:

Language-Guided Image Tokenizer
VisionLLM将图像视为一种外语,并将其转换为表征。与以往的部分工作利用固定大小的补丁嵌入来表示图像不同,VisionLLM引入了Language-Guided Image Tokenizer来灵活地编码与特定于任务的语言prompts或instructions相一致的视觉信息。
具体来说,作者首先将图像送到图像编码器(如ResNet)提取4个尺度的视觉特征$F_v$,同时利用文本编码器(如BERT)从给定的prompts中提取语言特征$F_l$,然后利用cross-attention将语言特征注入到每个尺度的视觉特征中,得到多尺度语言感知视觉特征,从而实现跨模态的特征对齐。
然后作者采用具有$M$个随机初始化的queries $Q=\{q_i\}^M_{i=1}$的transformer-based network如Deformable DETR来获得图像的high-level信息,将前面的到的多尺度语言感知视觉特征输入到transformer-based network中,提取$M$个image tokens$T=\{(e_i,l_)\}^M_i=1$,(e-embedding,l-location,分别代表了token的语义和位置信息),这一表示方式独立于图像分辨率,可以提取到与language prompts相关的视觉表达。
LLM-based Open-Ended Task Decoder
VisionLLM的decoder部分是基于Alpaca(adapted from LLaMA)构建的,可以在语言指导下处理各种和视觉相关的任务。
但Alpaca在处理以视觉为中心的任务时,存在一些固有缺点:
- 词汇表中的digital tokens只有0-9,限制了用数字来定位物体的能力
- 用多个tokens(category name tokens)来表示类别名称,这导致在进行对象分类时效率低下
- 这是一个因果模型,对于视觉感知任务而言效率低下
因此作者使用额外的tokens来拓展LLM的词汇表。
- 添加一组location tokens,表示为$\{< p-512>,…< p0>……< p512>\}$,其中< p i>($i ∈ [-512,512]$)表示image tokens的位置$l_i$的离散化offset,其与图像高度或宽度的相对值等于$i/512$。这些tokens将对象定位任务从连续变量预测转换为更统一的离散分类。
- 引入semantic-agnostic classification tokens$\{< c0>,< c1>,…,< c511>\}$来替代原本的表示类别的多个tokens(category name tokens)。类别和tokens的映射可以通过语言指令来灵活的实现,如{“person”:< c0>,“car”:< c1>,“black cat”:< c2>,…}。这种设计允许模型从提供的类别集中选择适当的类别名称,从而促进高效和准确的对象分类。
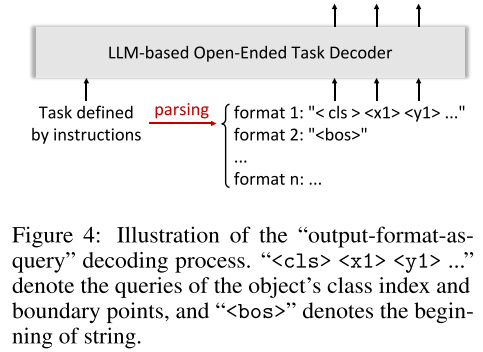
- 为了解决因果框架所造成的低效率,作者引入output-format-as-query decoding,利用LLMs从任务指令中解析结构化输出格式,(e.g., “< cls> < x1> < y1> < x2>< y2>” for object detection, “< bos>” for image captioning,beginning of string),然后将结构化输出格式的tokens作为queries送到decoder,以根据queries生成期望的输出。这种简单的方法使模型不仅可以避免低效,同时对于视觉语言任务保持了一个统一的框架。
通过这种方式,对象定位和分类的输出被公式化为foreign language,从而将这些以视觉为中心的任务统一为token classification。因此,视觉-语言和视觉任务都可以像语言任务一样用交叉熵损失来监督。此外,为了有效训练,作者采用了低秩自适应(LoRA)方法,这使得在没有过多计算成本的情况下可以训练和微调模型。
Details
4×8 NVIDIA A100 GPU上运行50个epoch