Monocular 3D Human Mesh Recovery
(a.k.a. 3D human pose and shape estimation) in the deep learning era
主要考虑RGB图片和单目RGB视频(统称为monocular images)作为输入
存在问题
- 将2D观察提升到3D空间存在固有的模糊性
- 多变的人体运动结构
- 与环境复杂的交互
两种范式:
- 基于优化:以迭代方式显式地将身体模型拟合到2D观察结果,各种数据项和正则化项被探索作为优化目标。
- 基于回归:利用神经网络强大的非线性映射能力,直接从原始图像像素预测模型参数。
Human Modeling
基于骨架:无法获得人体的表面
基于几何图元(geometric primitives,包括平面矩形,圆柱等):人体模型是手工制作的,不符合实际
statistical modeling:为了将密集点云和三角网格从3D扫描转换为水密的(watertight)和可动画(animatable)的3D人体网格,采取三个主要的预处理步骤:
template mesh registration: fit a template mesh to the 3D point cloud to deal with holes that the triangulated
mesh contains模板网格配准
skeleton fitting: determine the number of joints and the location and axis orientations of rotations for each joint
骨架匹配:确定关节的数量以及每个关节的旋转位置和轴方向
skinning: bind every vertex in the surface to the skeleton for animation
蒙皮:将曲面中的每个顶点绑定到骨骼以进行动画
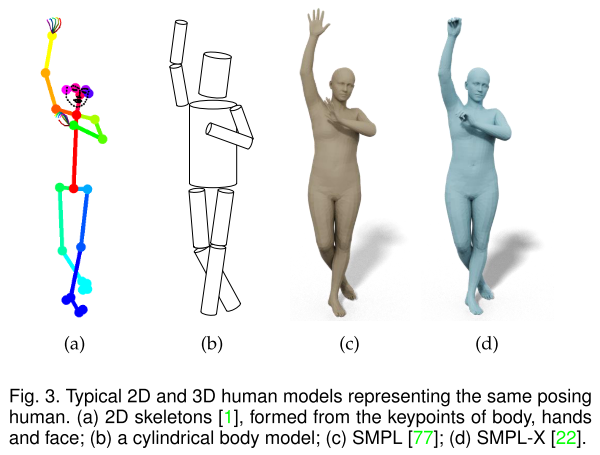
Statistical Modeling
Body Modeling
统计身体建模是指通过利用大量的3D身体扫描并简单地忽略手部关节或面部表情来学习统计身体模型
SCAPE 和SMPL 是两个代表性的模型,将身体变形(body deformations)分解为identity-dependent和姿势相关(pose-dependent)的形状变形。
SMPL
SMPL (Skinned Multi-Person Linear Model)是一种基于顶点的线性模型,描绘了自然姿势中穿着最少的人,这是目前研究界最广泛使用的人体模型,与现有的渲染引擎兼容。
SMPL是一个统计模型,通过两种类型的统计参数对人体进行描述:
- 形状参数(shape parameters):一组形状参数$\beta \in \mathbb{R}^{10} $去描述一个人的形状,每一个维度的值都可以解释为人体形状的某个指标,比如高矮,胖瘦等
- 姿态参数(pose parameters):一组姿态参数有着24×3维度的数字,去描述某个时刻人体的动作姿态,其中的24表示的是24个定义好的人体关节点,其中的3并不是如同识别问题里面定义的空间位置坐标(location),而是指的是该节点针对于其父节点的旋转角度的轴角式表达(axis-angle representation)(对于这24个节点,作者定义了一组关节点树)
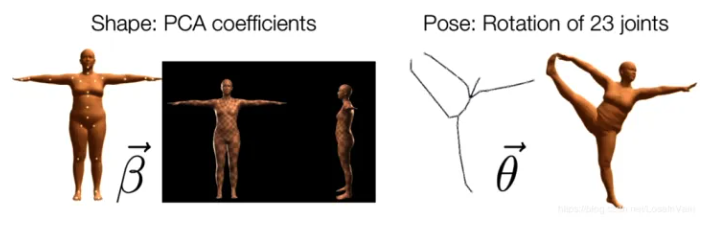
整个从SMPL模型合成数字人体模型的过程分为三大阶段:
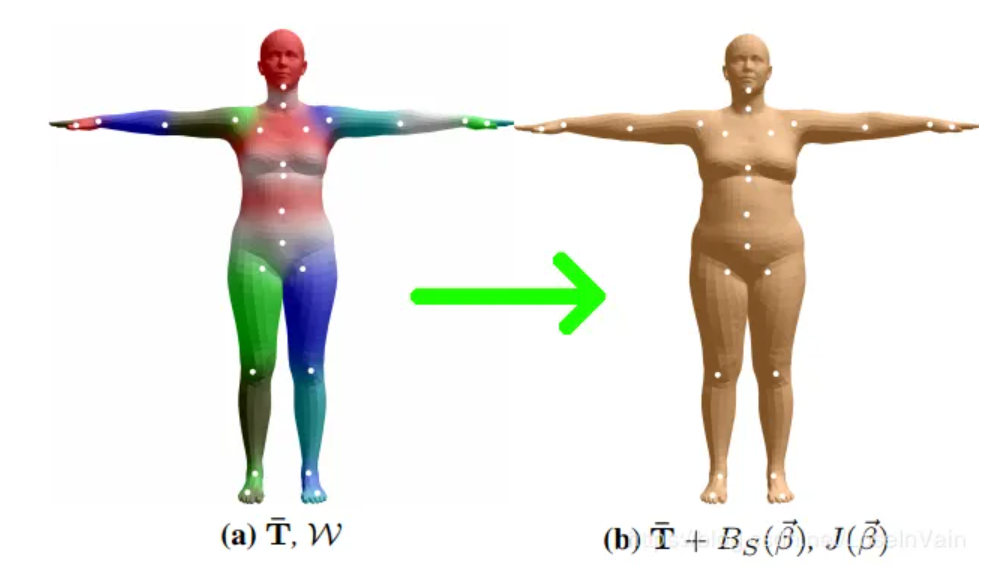
1. 基于形状的混合成形(Shape Blend Shapes)
一个基模版(或者称之为统计上的均值模版)$\bar{\Tau}$ 作为整个人体的基本姿态,这个基模版通过统计得到,用$N=6890$个端点(vertex)表示整个mesh,每个端点有着$(x,y,z)$三个空间坐标。随后通过参数$\beta \in \mathbb{R}^{10} $去描述我们需要的人体姿态和这个基本姿态的偏移量,叠加上去就形成了我们最终期望的人体姿态,这个过程是一个线性的过程。此处得到的人体mesh的姿态称之为静默姿态(rest pose,也可以称之为T-pose),因为其并没有考虑姿态参数的影响。

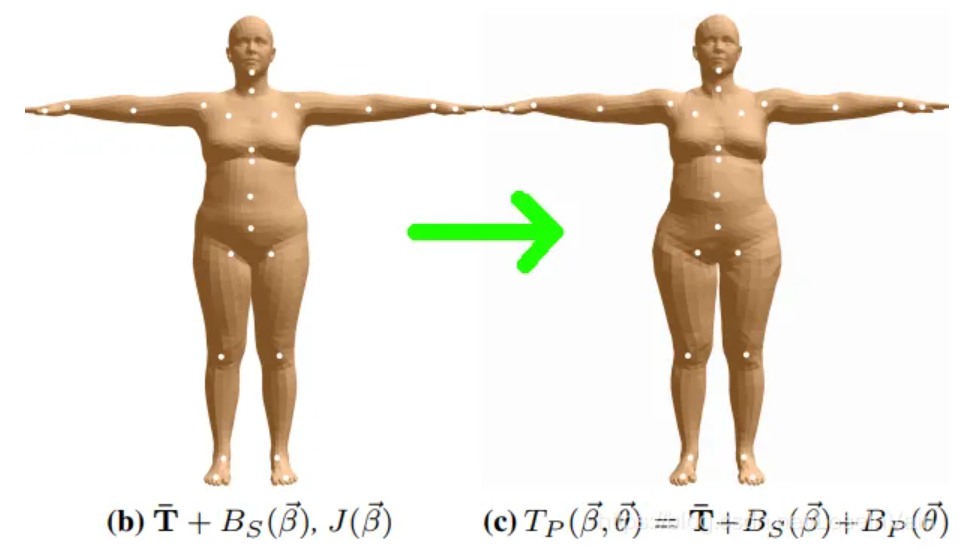
2. 基于姿态的混合成形 (Pose Blend Shapes)
当我们根据指定的$\beta$参数对人体mesh进行形状的指定后,我们得到了一个具有特定胖瘦,高矮的mesh,还未加入姿态对人体形状的影响。
SMPL定义了24个关节点的层次结构,并且这个层次结构是通过运动学树(Kinematic Tree)定义的,因此保证了子节点和父节点的相对运动关系。以0号节点为根节点,通过其他23个节点相对于其父节点(根据其运动学树结构可以定义出节点的父子关系)的旋转角度,我们可以定义出整个人体姿态的姿势。
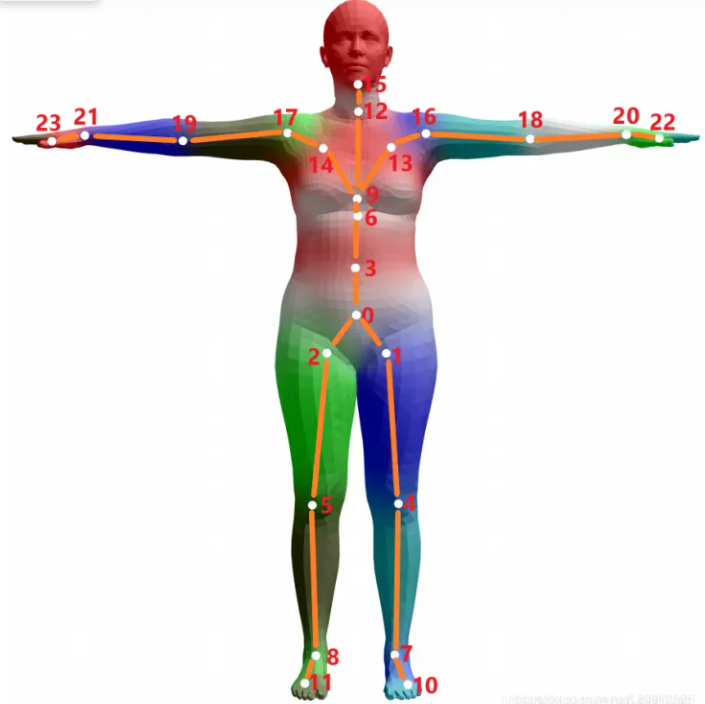
轴角式表示旋转的方向和大小
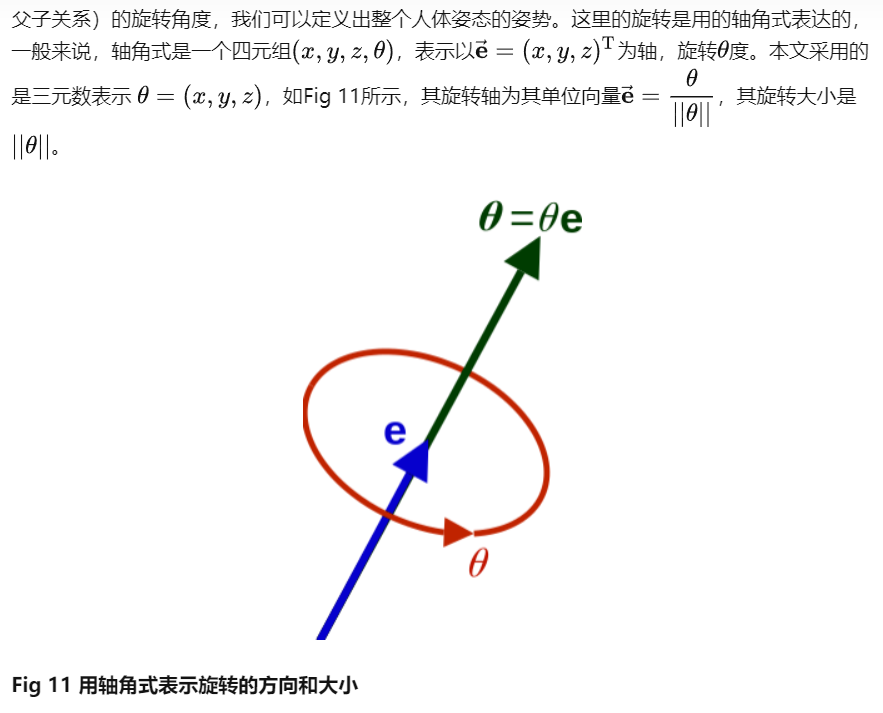
因此使用轴角式的三元数表示来表达这些非根节点的相对于父节点的相对旋转需要用$23\times3$个参数,为了表示整个人体运动的全局旋转(也称之为朝向,Orientation)和空间位移,比如为了表示人体的行走,奔跑等,我们还需要对根节点(0号)定义出旋转和位移,那么同样的,需要用3个参数以轴角式的方式表达旋转,再用3个参数表达空间位移。

1 | # self.pose : 24x3 the pose parameter of the human subject |
3. 骨骼点位置估计(Joint Locations Estimation)& 蒙皮
骨骼点位置估计整个过程可以可视化成Fig 12所示,每个骨骼点的位置由它本身最为接近的若干个mesh的端点加权决定。
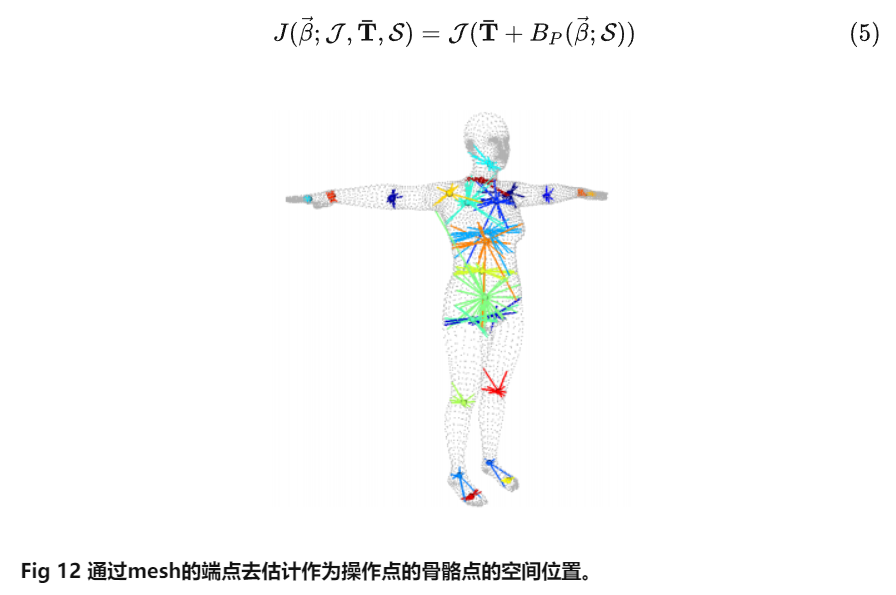
在经过骨骼点位置估计之后,我们便有了对整个人体数字模型进行操作的控制点了,其实就是骨骼点。当我们对骨骼点进行旋转时,我们可以像摆动球形关节娃娃一样将静默姿态下的人体摆成我们需要的姿态。人体mesh端点也会随着其周围的关节点一起变化,形成我们最后看到的人体数字模型。因此蒙皮其实是让静默姿态下的人体骨架“动起来”,并且对其蒙上“皮肤”的过程。
Whole Body Modeling
SMPL-X
Human Mesh Recovery
DM-NeRF