CVPR2023 GLIGEN
GLIGEN: Open-Set Grounded Text-to-Image Generation
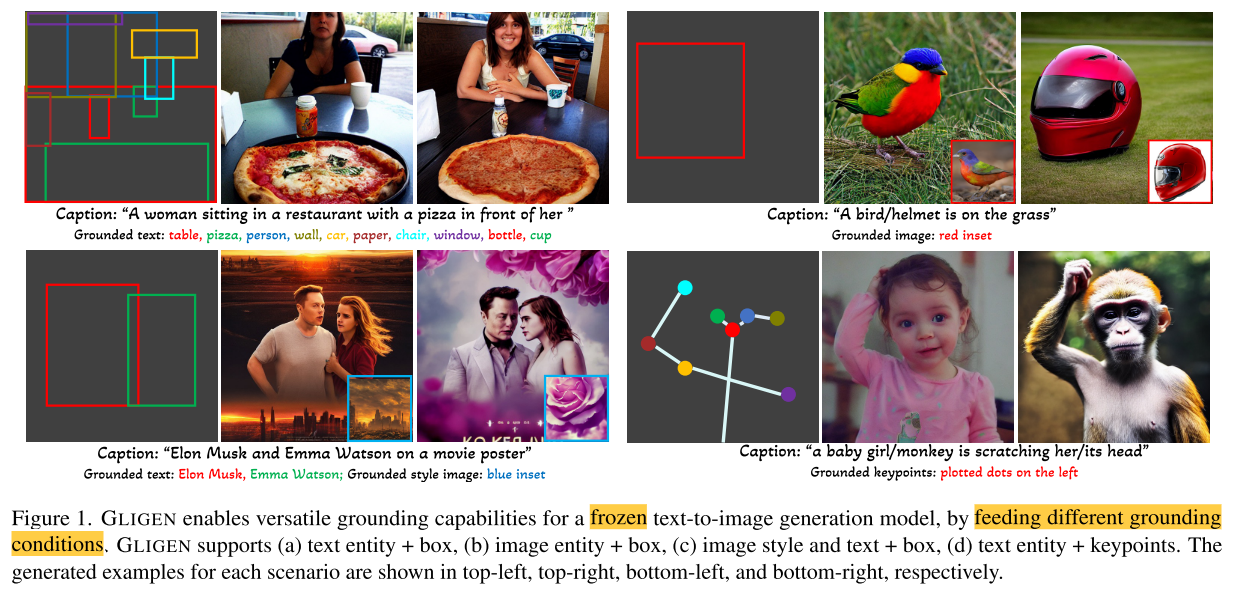
Motivation
单独使用文本输入来进行图像生成的可控性较差,缺乏精确定位概念或使用参考图像来控制生成过程的能力。扩散生成模型在大规模的图像文本对上进行训练,模型中已经具有大量的概念知识,是否能在现有的预训练扩散模型基础上,赋予新的条件输入模式?
本文提出的GLIGEN保留文本标题输入的同时,启用了其他模态的输入,在预训练的text-to-image扩散模型基础上,通过不同的条件输入实现了更好的可控性。
关键难点在于,如何在学习新的grounding信息的同时,不遗忘预训练模型中原有的概念知识。为了保留预训练模型的大量概念知识,GLIGEN中冻结了预训练模型的所有权值,并通过门控机制将grounding信息注入到新的可训练层
Related Work
- Large scale text-to-image generation models.
- 仅将标题作为输入,可能难以传达诸如对象的精确位置之类的其他信息
- 以往模型通常是close-set的
- 对于关键点等条件输入,attention方式难以控制
- Image generation from layouts(给定bboxes和物体类别,生成图像,是目标检测的逆任务)
- 通常是close-set的,只能生成有限类别的目标
- ReCo对原有模型进行了微调,可能导致知识遗忘
Methodology
image prompt提供更好的style和background参考,也可以作为实体提示
边界框则提升了定位能力和空间概念
可以实现grounded generation和grounded inpainting