OpenSeeD
A Simple Framework for Open-Vocabulary Segmentation and Detection
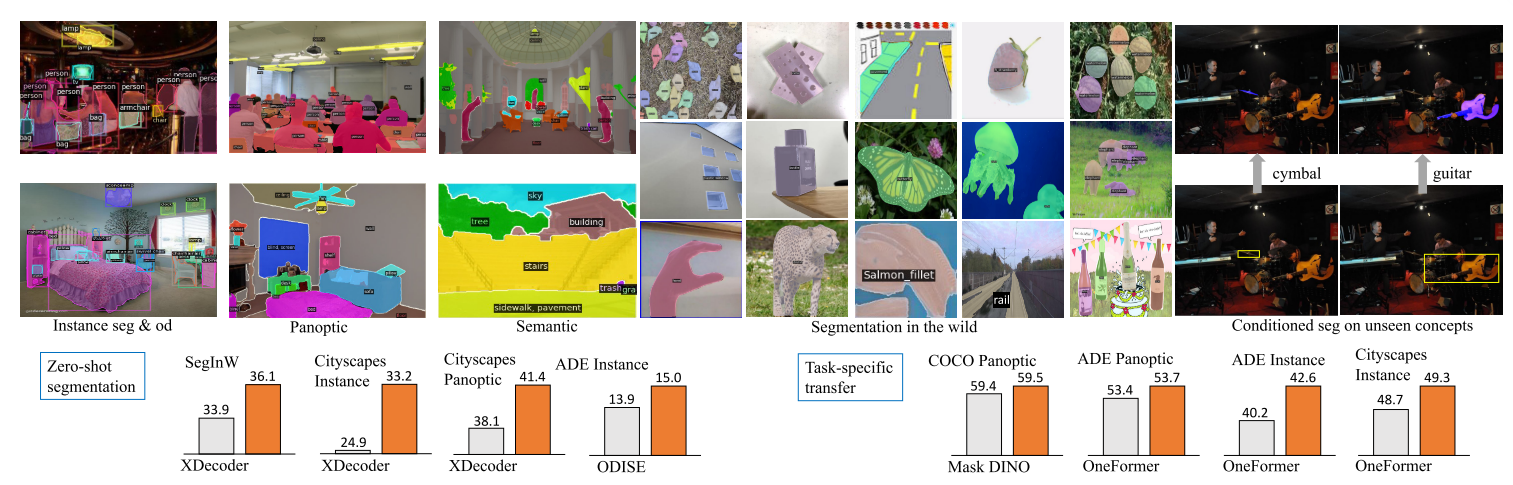
Motivation
将分割和检测进行联合训练,作者引入了一个预训练的文本编码器来为两个任务中涉及到的视觉概念进行文本编码,为了进一步协调两个任务,作者分析了两个任务的差异:
- 任务差异:分割需要获得前景和背景的mask,而检测只关心前景目标
- 数据差异:box和mask两种标注具有不同的空间粒度,因此难以直接互换
实现Open-Vocabulary for both task,Two critical questions:
- 如何在检测和分割之间传递语义知识
- 如何填补box和mask之间的监督差距
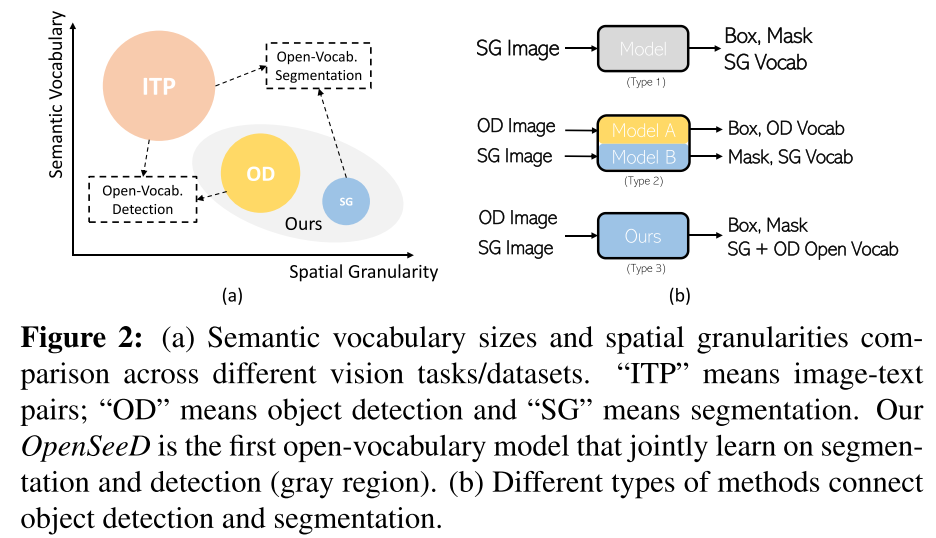
Related Work:
Generic Segmentation and Detection: 通用分割和检测模型如DETR,这类方法受限于词汇量,只能完成closed-set检测和分割
Open-Vocabulary Segmentation:
- 从大模型中蒸馏出visual-semantic knowledge
- DenseCLIP & GroupViT: 微调一个大模型 or 从头训练都可以获得较好的零样本表现
- X-Decoder: 将分割任务和其他几个视觉-语言任务联合起来
- ODISE: 使用text-to-image diffusion model来作为backbone
- 不同于这些方法,作者使用了具有纯净数据并且具有更小差距的检测与分割数据来作为监督。
Open-Vocabulary Detection:
- 从大模型中蒸馏,典型代表VILD, OV-DETR
- GLIP将检测和visual grounding任务结合起来,grounding data使得phrases和region能够更好的对齐
- RegionCLIP & DetCLIP: 从image-text pairs生成伪标注框
Weakly-Supervised Segmentation:
- 将弱图像级监督转移到细粒度任务通常需要复杂的设计来减小巨大的粒度差距,并且容易受到图像-文本对中的噪声的影响
- 对于box annotation的WSSS方法,如BoxInst,Box2Mask,DiscoBox和Mask AutoLabelers,这些方法都是closed-set的。
联合检测与分割
Mask R-CNN在COCO上联合学习了检测和实例分割,但其需要在包含对齐的box和mask标注的同一数据集上进行训练
Mask dino表明在Object365上预训练的检测模型可以很好的迁移用于COCO panoptic segmentation,遵循预训练-微调范式,这产生了两个separate closed-set models(也就是说一个模型只能单独用于检测或者单独用于分割,并且是closed-set的,不能迁移到novel类)
Methodology
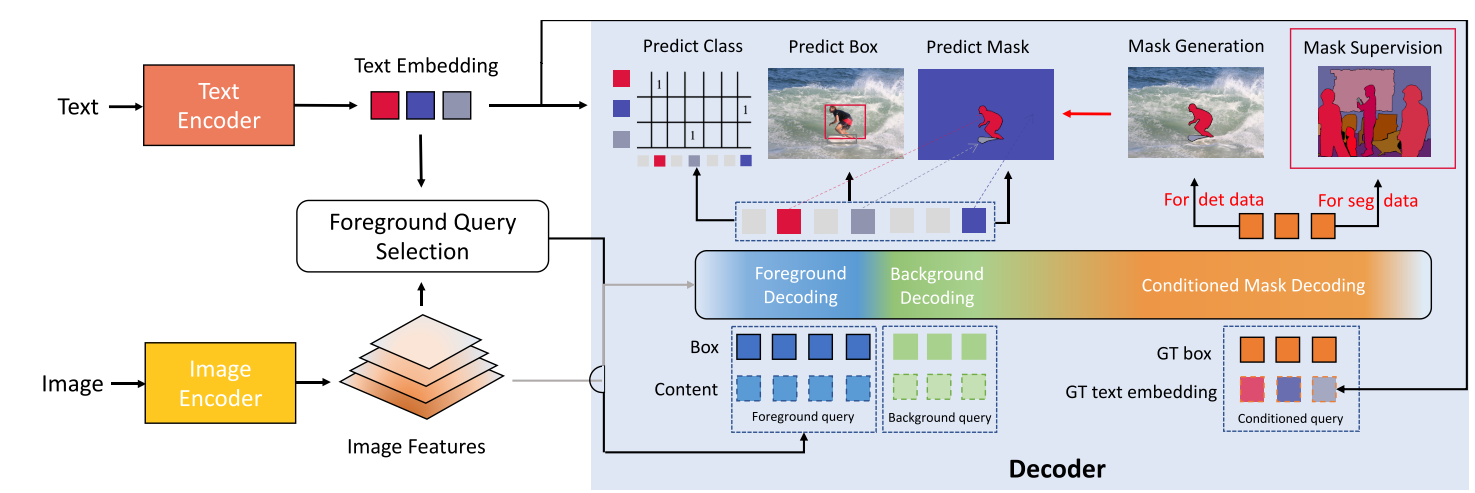
- 使用单个文本编码器来编码两个任务中涉及的所有概念,视觉tokens和语义在公共空间中对齐
- 将decoder中的queries分为forground queries(检测和分割中的前景物体),background queries(分割中的背景物体)和conditioned queries,每种query所对应不同的计算方式
- 引入conditioned mask decoding来从boxes中获得mask
Basic Loss Formulation
对于分割任务,可以从masks $\mathbf{m}$来生成准确的boxes $\hat{\mathbf{b}}$
$\begin{aligned}
\mathcal{L}_{a l l} & =\sum_{I,(\mathbf{c}, \mathbf{m}) \in \mathcal{D}_{m}} \overbrace{\left(\mathcal{L}_{m}\left(\mathbf{P}^{\mathbf{m}}, \mathbf{m}\right)+\mathcal{L}_{b}\left(\mathbf{P}^{\mathbf{b}}, \hat{\mathbf{b}}\right)+\mathcal{L}_{c}\left(\mathbf{P}^{\mathbf{c}}, \mathbf{c}\right)\right)}^{\text {Segmentation loss }} \\
& +\sum_{I,(\mathbf{c}, \mathbf{b}) \in \mathcal{D}_{b}} \underbrace{\left(\mathcal{L}_{b}\left(\mathbf{P}^{\mathbf{b}}, \mathbf{b}\right)+\mathcal{L}_{c}\left(\mathbf{P}^{\mathbf{c}}, \mathbf{c}\right)\right)}_{\text {Detection loss }}
\end{aligned}$
Bridge Task Gap: Decoupled Foreground and Background Decoding
解决的问题是如何在检测和分割之间传递语义知识
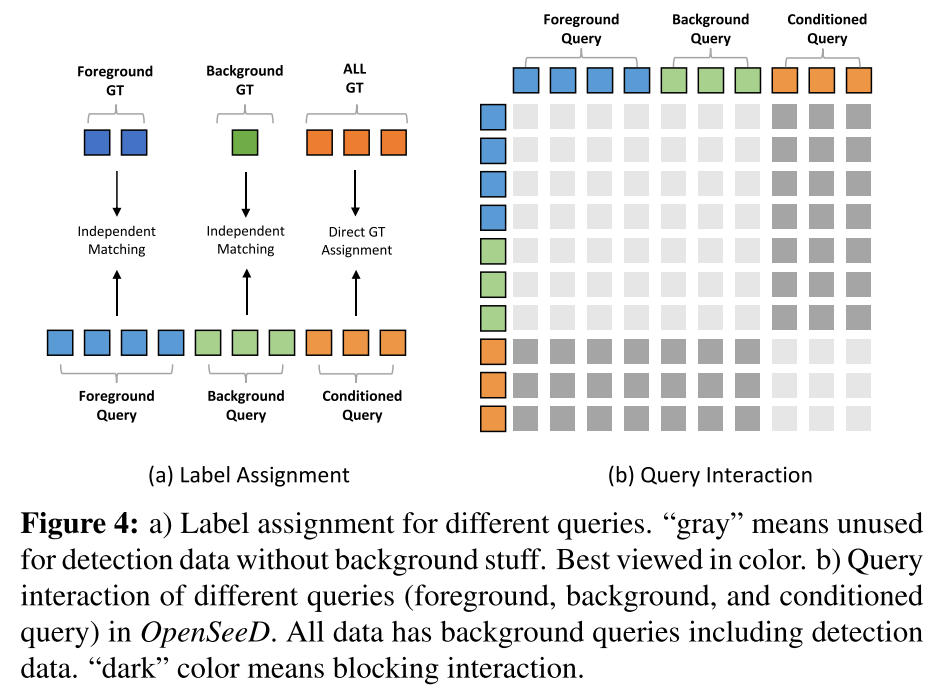
作者定义实例分割和检测中出现的视觉概念为foreground,全景分割中的stuff categories作为background。为了减小任务差异,前景解码和背景解码是分别进行的。具体来说,就是对于foreground query和background query分别用decoder得到对应的outputs sets $\left\langle\mathbf{P}_{f}^{m}, \mathbf{P}_{f}^{b}, \mathbf{P}_{f}^{c}\right\rangle$和$\left\langle\mathbf{P}_{b}^{m}, \mathbf{P}_{b}^{b}, \mathbf{P}_{b}^{c}\right\rangle$。将分割数据集也划分为$(\mathbf{c}_f,\mathbf{m}_f)$和$(\mathbf{c}_b,\mathbf{m}_b)$,分别与两个set进行Hungarian Matching(对应下图4(a)中Foreground Query与Foreground GT,Background Query和Background GT对应的Independent Matching)。
分割使用了前景和背景解码,检测只使用了前景解码
因此loss formulation可以写成(也就是将分割部分拆开成了前景和背景两项,而检测部分只计算前景)
$\begin{aligned}
\mathcal{L}_{a l l} & =\sum_{I,(\mathbf{c}, \mathbf{m}) \in \mathcal{D}_{m}} \overbrace{\left(\mathcal{L}_{m}\left(\mathbf{P}_{\mathbf{f}}^{\mathbf{m}}, \mathbf{m}_{f}\right)+\mathcal{L}_{b}\left(\mathbf{P}_{\mathbf{f}}^{\mathbf{b}}, \hat{\mathbf{b}}_{f}\right)+\mathcal{L}_{c}\left(\mathbf{P}_{\mathbf{f}}^{\mathbf{c}}, \mathbf{c}_{f}\right)\right)}^{\text {Segmentation loss for foreground }} \\
& +\overbrace{\left(\mathcal{L}_{m}\left(\mathbf{P}_{\mathbf{b}}^{\mathbf{m}}, \mathbf{m}_{b}\right)+L_{b}\left(\mathbf{P}_{\mathbf{b}}^{\mathbf{b}}, \hat{\mathbf{b}}_{b}\right)+\mathcal{L}_{c}\left(\mathbf{P}_{\mathbf{b}}^{\mathbf{c}}, \mathbf{c}_{b}\right)\right)}^{\text {Segmentation loss for background }} \\
& +\sum_{I,(\mathbf{c}, \mathbf{b}) \in \mathcal{D}_{b}} \underbrace{\left(\mathcal{L}_{b}\left(\mathbf{P}_{\mathbf{f}}^{\mathbf{b}}, \mathbf{b}\right)+\mathcal{L}_{c}\left(\mathbf{P}_{\mathbf{f}}^{\mathbf{c}}, \mathbf{c}\right)\right)}_{\text {Detection loss for foreground }}
\end{aligned}$
基于这种显式解耦,模型最大化了检测和分割数据集的前景监督协作,并显著减少了前景和背景类别之间的干扰。
虽然是解耦的,但是前景query和背景query共享同一个decoder,且通过自注意力相互作用,如下图4(b)
Language-guided foreground query selection
open-vocabulary setting与传统的closed-set设置的不同之处在于,需要模型来定位远远超出training vocabulary的大量前景对象。但是decoder中能够处理的前景queries数量非常有限,难以处理所有的视觉概念,因此提出了Foreground Query Selection来自适应的选择关于给定文本的queries。
具体来说,作者在获得了image features $\mathbf{O}$和text features $\mathbf{T}$后,使用一个box head来预测边界框,并计算区域特征和文本特征的相似度,排序后取出top $L_f$(前景query的个数)个,将这top $L_f$个boxes和对应的图像特征作为foreground query送入decoder,如下图中红框所示,content就是box对应的图像特征。
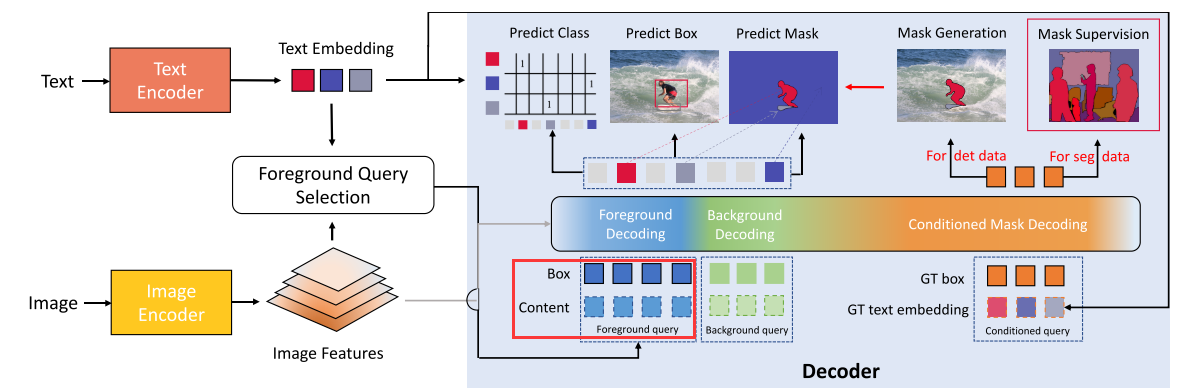
通过只选择text-related tokens作为decoder的queries,一定程度上避免了解码与文本不相关的语义,并提供了更好的查询初始化。这种提出前景查询的自适应方式使模型能够在测试场景中有效地迁移到新词汇上。
Learnable background queries
与foreground query不同,background queries使用了可学习的queries。可学习的queries可以充分的处理背景类别(相比前景,类别数量较少)
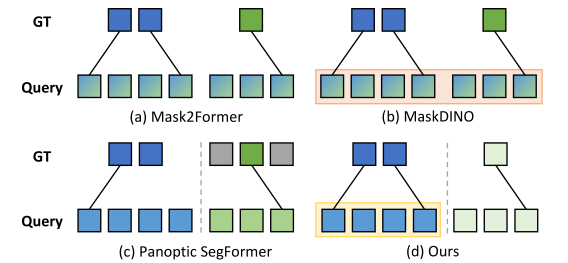
处理前景背景与以往方法的比较
- Mask2Former和MaskDINO在进行全景分割时,平等的对待前景和背景,这导致了次优解(相同模型在进行实例分割时表现更好)
- Panoptic SegFormer区别对待前景和背景queries,但背景queries是固定的语义类别(预先定义好的背景类别),这限制了处理open-vocabulary类别的能力
- 本方法通过语言引导的选择机制获得前景queries,并且使用了完全可学习的背景queries,消除了预定义词汇表的限制。
下图混合色代表平等对待,蓝色是前景,绿色是背景,加了框代表是选择获得的queries
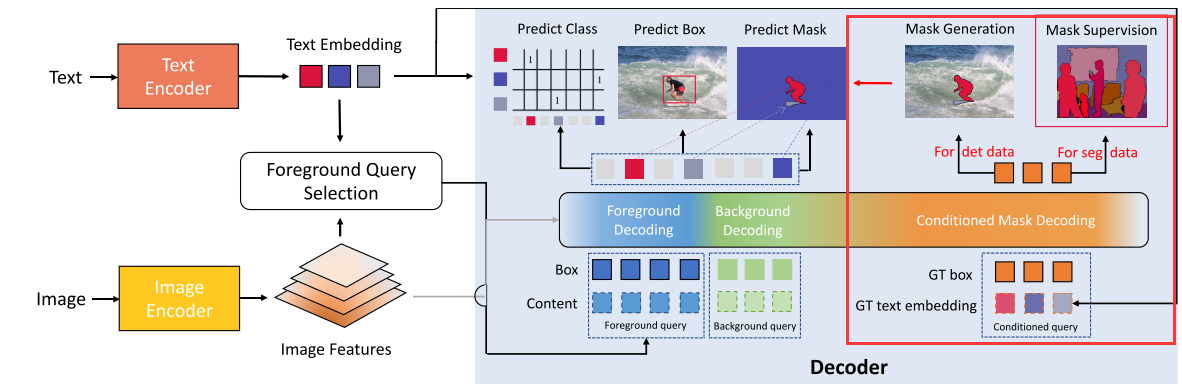
Bridge Data Gap: Conditioned Mask Decoding
从mask生成box很容易,作者在这一部分解决了如何从box生成mask的问题。
Conditioned Mask Decoding将GT box和class label经编码得到的文本特征作为query,然后解码出mask,利用分割数据集作为监督,训练一个从类别+box到mask的映射。
Mapping Hypothesis Verification
需要考虑的一个问题是,这样的映射是否能够很好的迁移到具有不同类别的检测数据集上?
作者就此问题进行了实验验证,在COCO上训练的映射能够很好的迁移到ADE20K上

Conditioned Mask Generation to Guide Detection Data
两种在训练阶段使用伪mask的方法:
- Online Mask Assistance:仅训练一个模型,生成实时的mask。不直接将生成的masks作为mask监督,而是使用伪mask来帮助匹配预测和GT实例,因为掩码质量对于监督来说不够强。特别是在早期阶段。
- offline Mask Assistance:使用conditioned mask decoding训练模型直到收敛,并为检测数据生成掩码注释。注释的数据集可以用于训练分割模型。
Experiment
baseline为Mask DINO