ODISE: Open-vocabulary DIffusion-based panoptic SEgmentation
结合了text-to-image diffusion model和discriminative model(如CLIP)实现全景分割
Motivation
text-to-image diffusion model能够根据任意文本产生高质量的图像,这说明其内部的表征空间与真实世界中的open concepts是高度相关的,其学习到了较好的开放概念的表征。text-image discriminative model如CLIP,擅长将图像进行开放词汇分类。
本文提出利用上述两种模型的冻结特征来进行开放词汇全景分割。

text-image discriminative model如CLIP容易混淆对象之间的空间关系,缺乏对空间和关系的理解,作者认为这是将其用于开放词汇全景分割的主要瓶颈。
Related Work
- MaskCLIP也使用了CLIP作为visual representation,但是全局的特征对于分割任务是次优的,因此作者选择使用和diffusion model的内部representation。
- Generative Models for Segmentation:以往工作主要集中解决的是closed vocabularies,但思想其实都是生成模型的内部表示可以充分区分并关联到中/高级视觉语义概念,并且可以用于语义分割。
Methodology
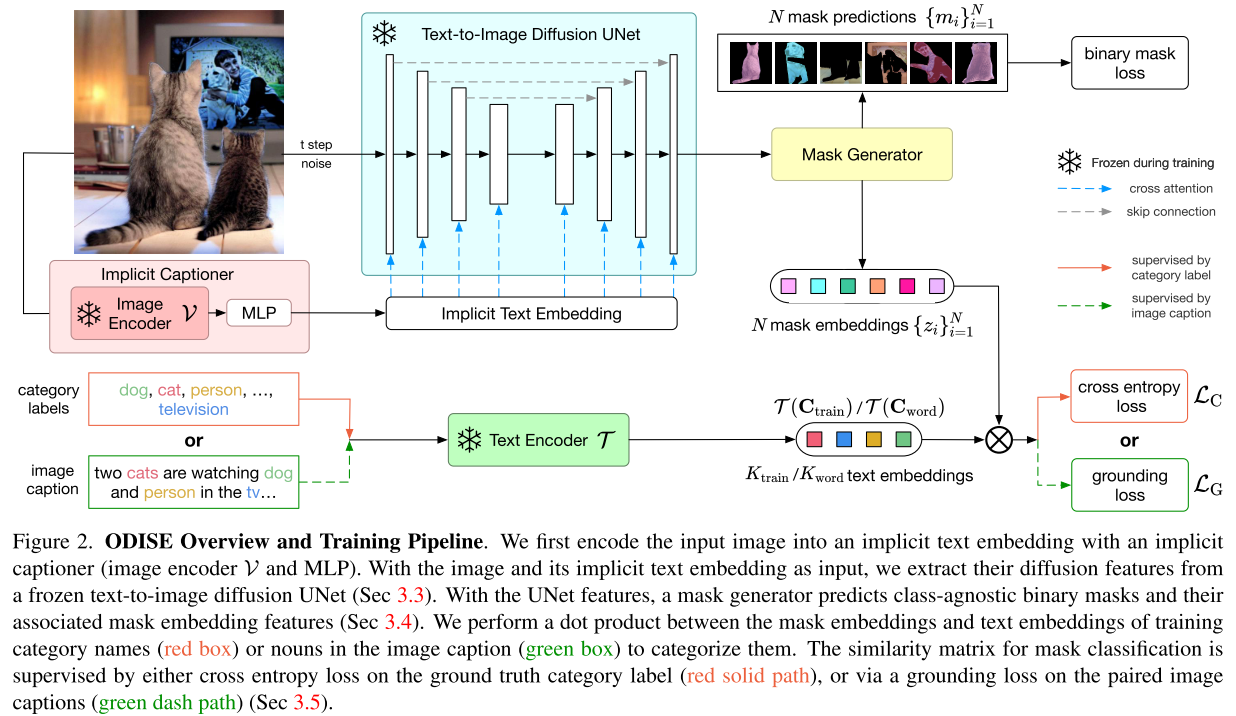
将图像和对应的caption送入预训练的冻结的diffusion model提取特征,然后利用这些特征和已有的标注mask来训练一个mask generator。
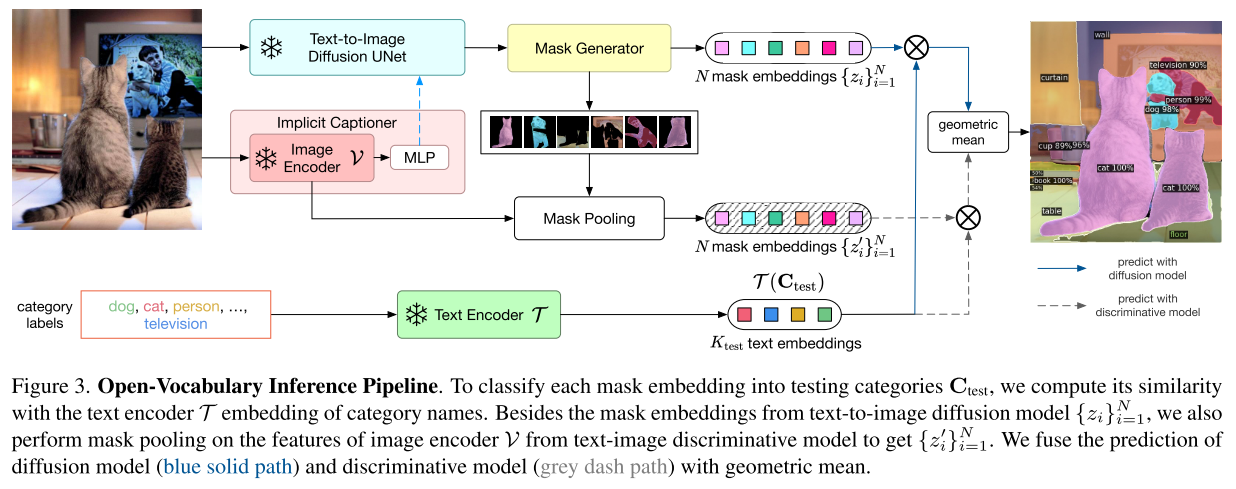
然后利用mask classification module对掩码进行开放词汇分类(计算mask对应的diffusion feature与text embedding的相似度)