ICLR2022 ViLD
OPEN-VOCABULARY OBJECT DETECTION VIA VISION AND LANGUAGE KNOWLEDGE DISTILLATION
Motivation
Object Detection方法是学习去检测数据集中的类别,如果想要增加可检测的类别,通常的做法是增加标签类别,但是类别数增多会对训练样本收集带来更多挑战,对象类别存在长尾问题,罕见类的样本扩充成本高昂。另一方面,图文对则易于获取。ViLD则是想借助于预先训练的CLIP来实现Open-Vocabulary Detection(OVD).
OVD旨在仅使用base classes的detection annotations来训练一个detector,可以检测出文本描述的任意类别,也就是可以从base classes泛化到novel classes
Methodology
ViLD将OVD转换成了两个子问题,并使用Mask RCNN作为baseline:
- 生成object proposals
- Open-vocabulary image classification(使用CLIP对cropped object proposals进行分类)
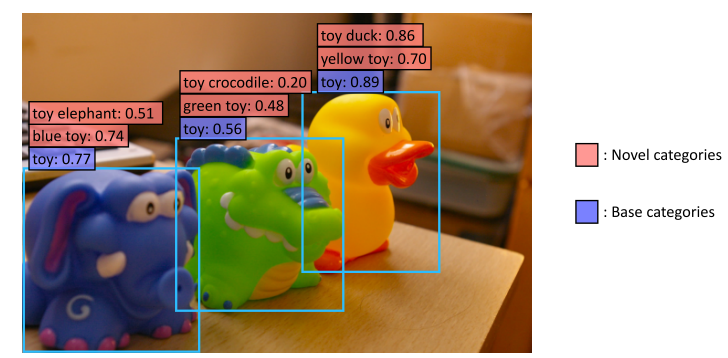
Localization for Novel Categories
将Mask R-CNN的class-specific localization modules(即第二阶段的bbox回归和mask prediction layer)替换为class-agnostic modules,从而泛化到novel objects,实现对base类和novel类的定位
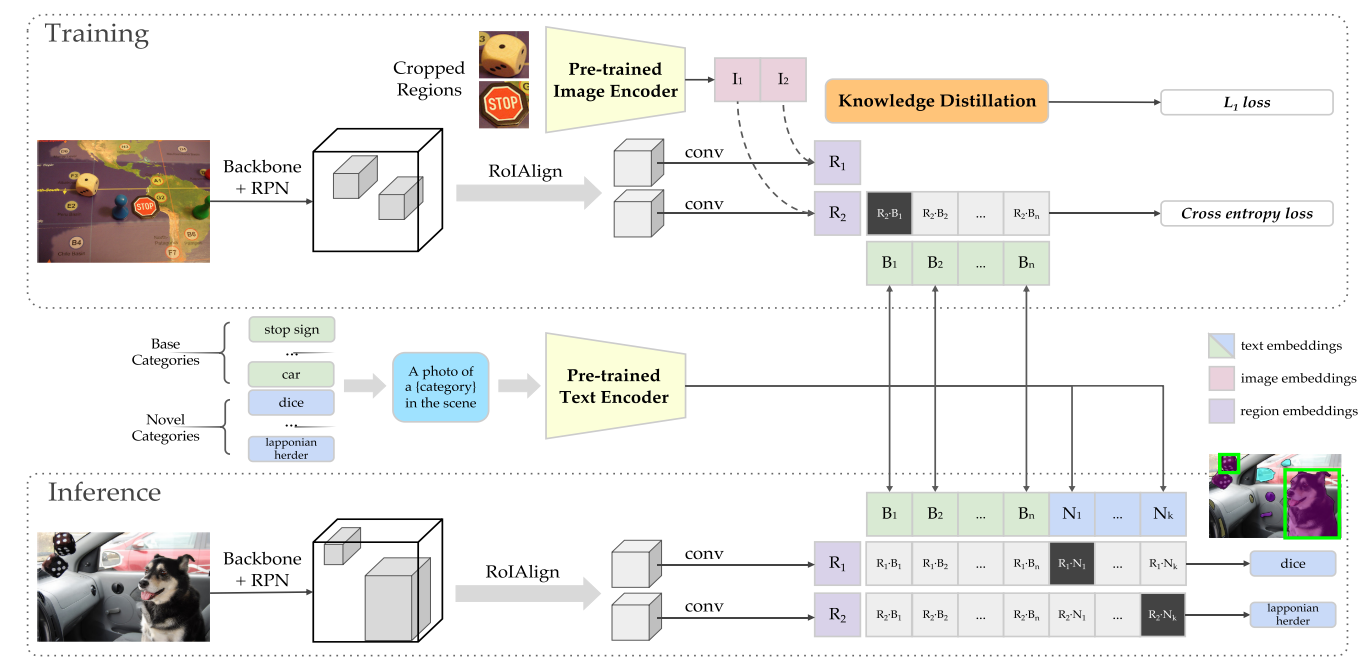
Open-Vocabulary Detection with Cropped Regions
在获得proposal后(即完成了对object的定位),作者提出使用CLIP来对每个proposal进行open-vocabulary image classification
获取image embeddings:
作者首先crop并resize离线生成的region proposals,然后将其送入CLIP的图像编码器获得image embeddings。作者在此处做了ensemble操作:
$\mathcal{V}\left(\operatorname{crop}\left(I, \tilde{r}_{\{1 \times, 1.5 \times\}}\right)\right)=\frac{\mathbf{v}}{|\mathbf{v}|}, \text { where } \mathbf{v}=\mathcal{V}\left(\operatorname{crop}\left(I, \tilde{r}_{1 \times}\right)\right)+\mathcal{V}\left(\operatorname{crop}\left(I, \tilde{r}_{1.5 \times}\right)\right)$
其中$\mathcal{V}$代表CLIP的图像编码器,$\tilde{r}$则代表region proposals。
获取text embeddings:
将类别文本经prompt templates转换后送如CLIP的文本编码器$\mathcal{T}$, 获得类别文本特征
最后计算image embeddings和text embeddings的余弦相似度,确定每个proposal的类别后,使用NMS获得最终的预测结果。
直接采用class-agnostic proposal+CLIP分类的方案缺陷:
由于每个cropped region都要经过一次CLIP的图像编码器,因此推理速度会很慢。
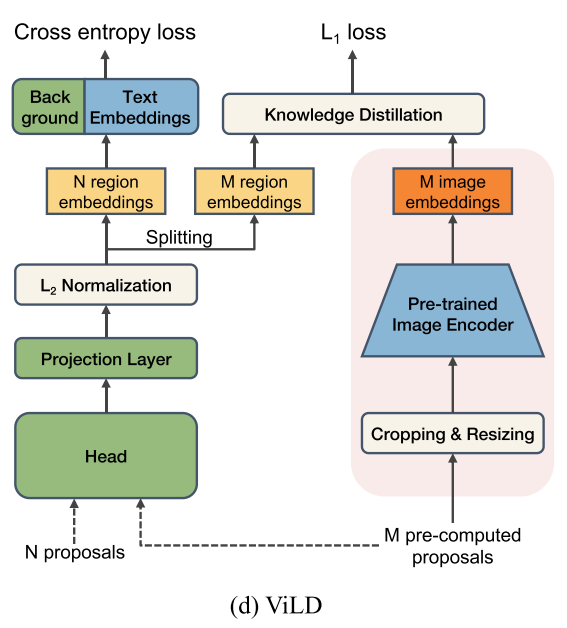
ViLD: Vision and Language Knowledge Distillation
为了解决上述的推理速度慢的问题,作者提出了ViLD。
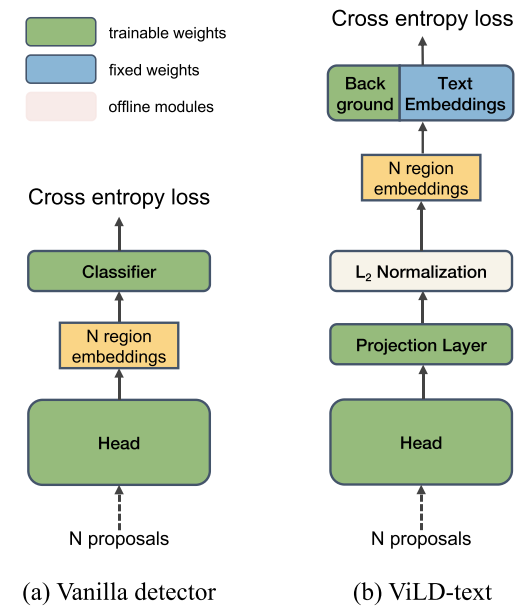
ViLD-text
Replacing classifier with text embeddings
模型总览图如上图(b)所示,与传统的检测器的不同在于,ViLD通过region embedding与text embedding算相似度来获得logits
$\mathbf{e}_{r}=\mathcal{R}(\phi(I), r)$
$\phi(\cdot)$代表backbone,$I$代表图像,$r$代表提前抽好的region proposals,$\mathcal{R}(\cdot)$代表用于产生region embedding的lightweight head(作者将分类层前的输出作为region embeddings, 也就是公式中的$\mathbf{e}_r$)。
$\mathbf{z}(r)=\left[\operatorname{sim}\left(\mathbf{e}_{r}, \mathbf{e}_{b g}\right), \operatorname{sim}\left(\mathbf{e}_{r}, \mathbf{t}_{1}\right), \cdots, \operatorname{sim}\left(\mathbf{e}_{r}, \mathbf{t}_{\left|C_{B}\right|}\right)\right] $
$\mathbf{e}_{bg}$代表背景embedding, $\mathbf{t}_n$代表第n类的文本编码,$C_B$代表基础类,上式就是region embedding和所有的文本embedding算相似度,得到类似于logits的输出$\mathbf{z}(r)$。
然后利用这个logits经过softmax与gt计算CE loss。
$\mathcal{L}_{\mathrm{ViLD} \text {-text }}=\frac{1}{N} \sum_{r \in P} \mathcal{L}_{\mathrm{CE}}\left(\operatorname{softmax}(\mathbf{z}(r) / \tau), y_{r}\right),$
ViLD-image
Distilling image embeddings
CLIP的图像编码器得到的图像特征能和文本特征很好的对齐,因此作者想要通过蒸馏的方式,让ViLD中使用的图像编码器得到的region embedding尽量和CLIP图像编码器得到的region embedding一致。在这种情况下,训练不再受基础类的限制,proposal可以是属于基础类的,也可以是属于新类的,因为监督信号是来自CLIP的,而不是数据集的人工标注。
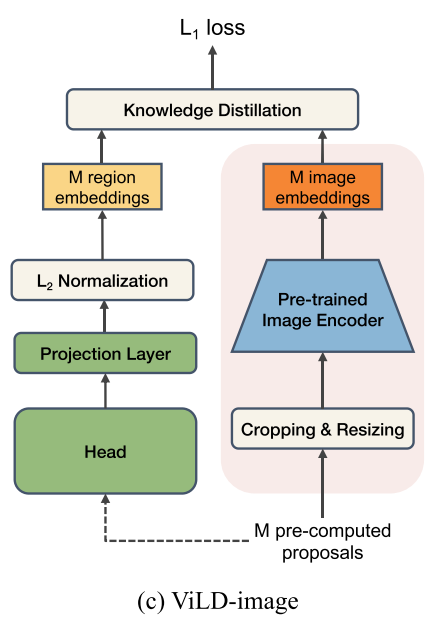
需要注意的是,为了加快训练的速度,不在CLIP前向推理耗费太多时间,作者首先采用预训练好的RPN对所有的图像进行推理,把预测的M个proposal(注意ViLD-text是N个,N个是随时可以改变的)保存下来,然后用CLIP对这些proposal抽特征并保存,训练时只需要从硬盘加载即可。
ViLD整体框架如下,N个proposal是随时可以改变的,M个proposal是pre-computed
Experiments
LVIS数据集,将common和frequent类作为base类,将rare类作为novel类,测试zero-shot的能力(open-vocabulary)

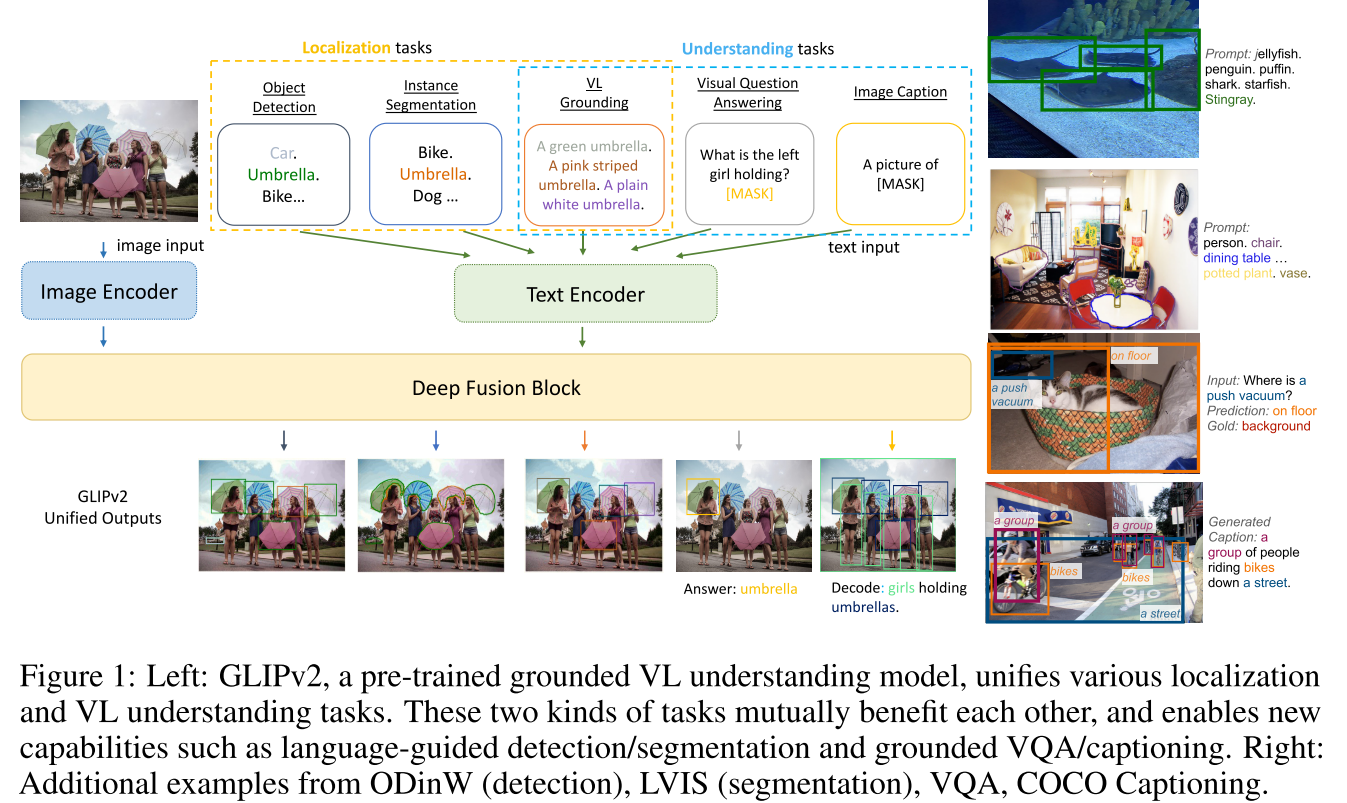
CVPR 2022 GLIP
Grounded Language-Image Pre-training
Motivation
更加有效的利用图像文本对数据和已有的标注数据,将visual grounding(phrase grounding)任务和object detection任务结合起来进行预训练。检测数据量大,而grounding数据含有丰富的词汇,将两个任务统一起来有两个好处:
- 同时从两种数据学习如何去grounding
- GLIP可以通过以self-training的方式来为大量的图像-文本对生成伪边界框,从而扩大训练的数据集
Methodology
核心问题:如何将visual grounding和object detection任务统一起来?
两个任务的主要区别在于分类的loss计算:detection的分类标签是one-hot的,而visual grounding的标签是一个句子
Detection
$O=\operatorname{Enc}_{I}(\operatorname{Img}), S_{\mathrm{cls}}=O W^{T}, \mathcal{L}_{\mathrm{cls}}=\operatorname{loss}\left(S_{\mathrm{cls}} ; T\right) .$
输入图像Img通过图像编码器,获得region embedding $O$, 然后经过分类头(也就是乘上矩阵$W$)得到分类的logits,然后经过NMS筛选定位框,用筛选后的$S_{cls}$和标签计算CE loss
Visual Grounding
计算图像区域与prompt中单词的匹配分数(alignment scores $S_{ground}$). 输入图像Img通过图像编码器获得region embedding $O$,然后将输入的句子通过一个文本编码器得到文本特征$P$
$O=\operatorname{Enc}_{I}(\operatorname{Img}), P=\operatorname{Enc}_{L}(\text { Prompt }), S_{\text {ground }}=O P^{\top}$
将detection转化为grounding:
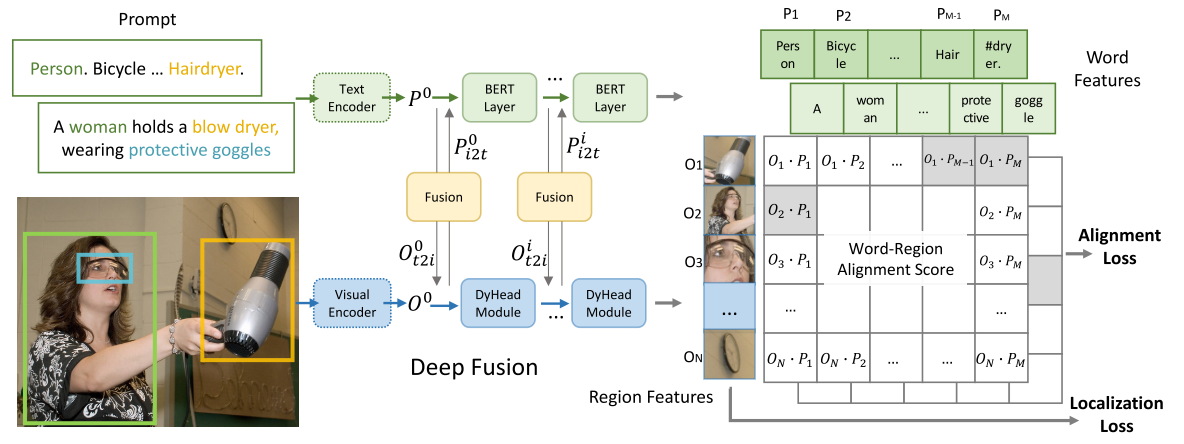
将COCO中的80个类名组成一个文本字符串,作为prompt输入,如图(左)所示,转换为匹配任务
如图1(右)所示,任何目标检测模型都可以通过用word-region alignment scores(区域/边框的视觉特征与token/短语的语言特征的点积)替换边框分类器中的目标分类logits而转换为关联模型。
CLIP、GroupViT仅在最后的点积层融合视觉和语言,与此不同的是,GLIP采用深度跨模态融合(使用cross attention来实现两个模态的early fusion,deep fusion),这与Lseg中的交互方式类似,如图(中)所示,这对于学习高质量的语言感知视觉表示和实现优秀的迁移学习性能至关重要。
这里使用的Alignment Loss其实就是ViLD中的ViLD-text分支
GLIPv2
GLIPv2: Unifying Localization and VL Understanding
融合更多任务,更多数据集