VPD (Visual Perception with a pre-trained Diffusion model)
如何利用大规模数据预训练的Diffusion model来支持下游的Visual perception 任务
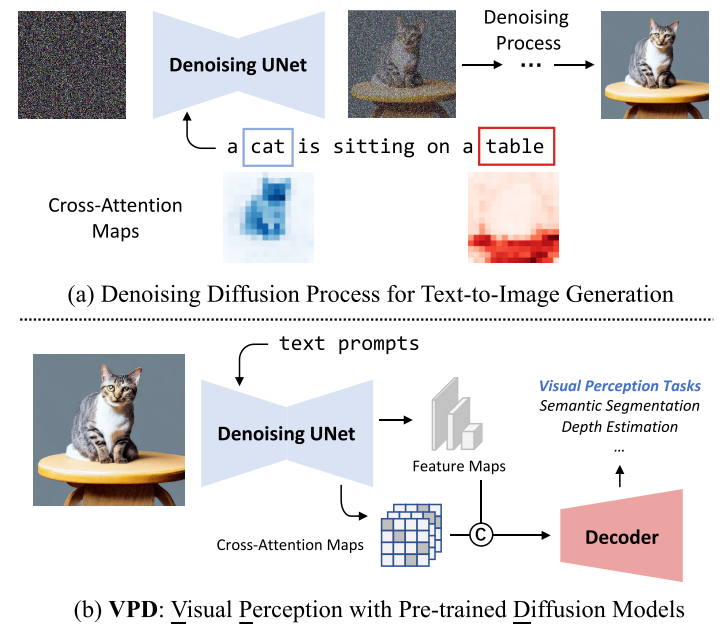
Motivation
text-to-image diffusion model通过视觉语言预训练获得了更多的high-level knowledge,大规模text-to-image diffusion model能够生成纹理丰富、内容多样、结构合理的高质量图像,同时具有可组合、可编辑的语义。这一现象暗示了大规模的文本-图像扩散模型可以从大量的图像-文本对中隐式地学习高层次和低层次的视觉概念。
本文旨在研究提取大规模扩散模型所学习到的视觉知识来支持下游的Visual perception 任务。作者提出的VPD框架探索了如何利用pre-trained denoising UNet去为下游视觉感知任务提供语义引导。
与将知识从常规的预训练模型转移到下游视觉感知任务相比,对diffusion model进行transfer learning存在两个挑战:
- diffusion model和视觉感知任务之间的不兼容性
- UNet类扩散模型和流行视觉backbone之间的架构差异
Methodology
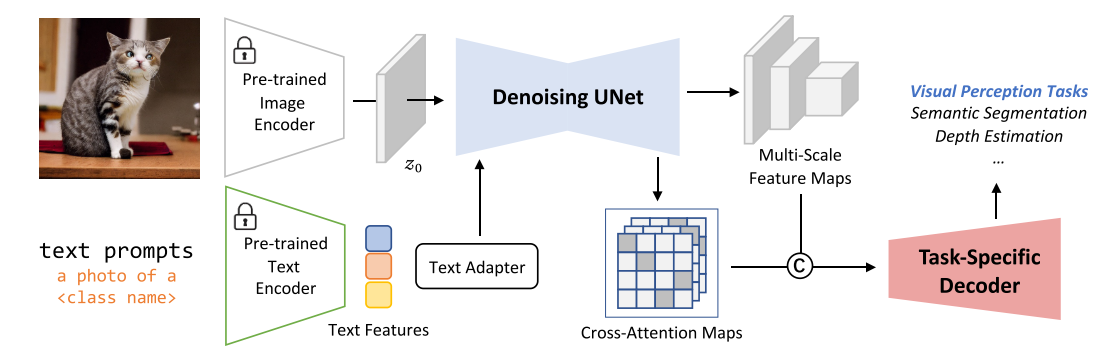
Prompting Text-to-Image Diffusion Model
基本思想是在任务特定标签和自然语言之间建立连接,从而可以有效地提取学习的语义信息。
将prediction model记作$p_{\phi}(\boldsymbol{y} \mid \boldsymbol{x}, \mathcal{S})$,$\mathcal{S}$是任务中所有用到的类别名字的集合
$p_{\phi}(\boldsymbol{y} \mid \boldsymbol{x}, \mathcal{S})=p_{\phi_{3}}(\boldsymbol{y} \mid \mathcal{F}) p_{\phi_{2}}(\mathcal{F} \mid \boldsymbol{x}, \mathcal{C}) p_{\phi_{1}}(\mathcal{C} \mid \mathcal{S})$
其中$\mathcal{F}$代表feature maps,$\mathcal{C}$代表文本特征
- $p_{\phi_{1}}(\mathcal{C} \mid \mathcal{S})$代表从class name提取的文本特征。作者使用CLIP的文本编码器(图中锁住的Pre-trained Text Encoder),template为”a photo of a [CLS]”,为了使文本特征能更好的迁移到下游任务,作者加入了一个Text Adapter(由两层MLP构成),用于调整CLIP文本编码器得到的特征
- $p_{\phi_{2}}(\mathcal{F} \mid \boldsymbol{x}, \mathcal{C})$代表在给定图像$\boldsymbol{x}$和条件输入conditioning inputs $\mathcal{C}$时,提取多层特征$\mathcal{F}$(contains 4 feature maps对应不同分辨率)。$\mathcal{C}$包含了自然语言的知识,因此$p_{\phi_{2}}$需要捕获vision-language的跨模态交互。作者发现预训练的text-to-image diffusion model可以是$p_{\phi_{2}}$的一个非常好的初始化。作者在实现时,首先使用VQGAN的encoder $\mathcal{E}$(图中锁住的Pre-trained Image Encoder)将输入图像转换到latend space,即$z_0 = \mathcal{E}(x)$, 然后将latend feature map $z_0$和conditioning inputs $\mathcal{C}$送入预训练的Denoising UNet网络(记作$\epsilon_{\theta}$),作者简单地设置时间步t = 0,使得没有噪声被添加到latend feature map中。然后从$\epsilon_{\theta}$的不同分辨率的output block获取多层特征$\mathcal{F}$,即图中的Multi-Scale Feature Maps。
- $p_{\phi_{3}}(\boldsymbol{y} \mid \mathcal{F})$是prediction head,根据多层特征$\mathcal{F}$来生成最终的结果。作者认为对于下游的视觉任务来说,预训练的Denoising UNet网络($\epsilon_{\theta}$)已经具有足够的容量,因此prediction head可以是非常轻量的结构,作者采用了Semantic FPN(由多层卷积和上采样层组成)来作为prediction head。
作者通过把任务特定的类别标签$\mathcal{S}$作为输入,隐式地提示预训练的Denoising UNet探索学习的语义知识。这一方法不再是基于扩散的框架,因为只使用了单个UNet作为主干。
在VPD中diffusion model并非用于逐步扩散,而是被用作backbone,输入是没有噪声(t=0)的图像以及条件输入,只执行一次去噪步骤(将输出作为下游任务使用的特征)。
Semantic Guidance via Cross-attention
在上一节中描述了作者如何设计合适的prompts来隐式的从$\epsilon_{\theta}$网络中提取high-level knowledge,除此之外,作者还设计了cross-attention map来显式的进行语义引导。
Limitation
高计算成本
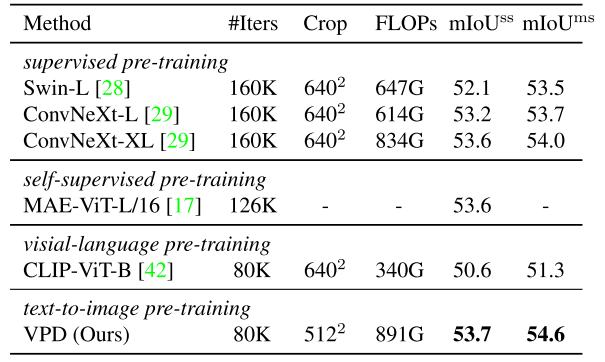
Review
在不同的time step提取的特征对下游任务的影响