GAN
保真度高,多样性较差,训练不够稳定(因为需要同时训练两个网络,需要做平衡,否则容易模型坍塌),不是一个概率模型,生成是隐式的(通过一个网络去完成),数学上不如VAE,扩散模型优美
generator生成器:给定一个随机噪声,生成图像
discriminator判别器:将生成器生成的图像与真实图像送入判别器,做0/1二分类
Auto-Encoder(AE)
给定输入x经过编码器获得一个维度较小的特征(bottleneck),然后bottleneck再通过decoder生成一个图像,训练时的目标函数就是重建自己
Denoising Auto-Encoder(DAE)
与AE的区别在于,输入x经过一定的打乱,加入噪声,然后再将扰乱后的输入送入encoder,重建的目标仍然是重建出原图。这一改进非常有效,不容易产生过拟合,与MAE的思想非常相似,利用了图像冗余性
AE、DAE、MAE的目的都是为了获得一个好的bottleneck特征,用于分类检测分割等任务,并不是为了做生成,原因是学到的bottleneck特征并不是一个概率分布,没法对其进行采样。
Variational Auto-Encoder(VAE)
利用AE和VAE这种encoder-decoder结构来做生成
VAE和DAE的主要区别在于,中间不再是学习一个固定的bottleneck特征,而是学习一个分布,作者将分布假设为高斯分布,用均值和方差来描述
整体流程变为输入x,经过encoder后加一些FC层,预测得到均值$u$和标准差$\sigma$,然后根据$z=u+\sigma \cdot \varepsilon $采样得到bottleneck特征$z$, 其中$u$是均值,$\sigma$代表标准差,$\varepsilon$符合均值为0,方差为1的正态分布$N(0,1)$。这样VAE就可以用于生成了,在推理时直接扔掉encoder部分,直接从高斯随机噪声中抽样出$z$送给decoder,就可以得到生成的图像。
从贝叶斯概率看,VAE从输入x预测z的过程,其实对应的是后验概率$q(z|x)$,然后学习预测得到的分布就是一个先验分布,后面的decoder部分则是给定z去预测x,也就是似然$p(x|z)$,这里所做的就是要maximize likelihood极大似然(利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值)。
Vector Quantized(VQ-VAE)
把VAE进行量化,不去做分布的预测,而是使用一个codebook(一般是$K\times D$的向量,可以理解为$K$个聚类中心)代替。具体来说,输入在经过encoder后得到了特征$f$,尺寸为$h\times w\times D$,然后将每个位置的向量与codebook里的聚类中心算相似度,使用最接近的codebook聚类中心代替原本的向量,从而得到新的量化后的特征quantised feature $f_q$, 这一量化后的特征是非常可控的,因为都是从codebook里来的,优化起来相对容易,后续就是使用量化后的特征来进行图像重建。
VQ-VAE学习到的是一个固定的codebook,因此没办法像VAE一样做随机采样,然后生成图像,其实更像一个AE,学习到的codebook是作为high-level特征拿去做分割分类等任务的
视觉自监督学习方法BEIT就是使用了DALL·E生成好的codebook
如果想把VQ-VAE用于生成,需要再单独训练一个prior网络,在VQ-VAE论文中,作者又单独训练了一个pixel CNN(一个自回归模型)当作prior网络
Diffusion
DDPM
Denoising Diffusion Probabilistic Model, 以往原始的diffusion使用$x_t$来预测$x_{t-1}$,也就是做图像到图像的转化,DDPM认为不好优化,因此DDPM提出不去直接预测图像,而是预测图像到图像转换所加的噪声。用于预测噪声的U-Net的输入有两个,一个是$x_t$,另一个是time embedding,用于告诉U-Net到了反向扩散的哪一步(U-Net在每一步都是共享的),我们希望在反向扩散的开始阶段,先去生成一些低频信息,具有一些大致轮廓,到最后快生成最终图像时能学习到更多高频的信息特征,比如一些物体的细节。
目标函数:$P(x_{t-1}|x_t)=||\varepsilon-f_{\varepsilon}(x_t,t)||$,也就是给定$x_t$去预测$x_{t-1}$,则loss是我们前向扩散时加的已知噪声$\varepsilon$和现在预测出的噪声$f_{\varepsilon}(x_t,t)$的差值,$f$函数对应U-Net,t对应time embedding。
DDPM中还发现,如果要预测一个正态分布,需要学均值和方差,但其实只需要学习均值,方差直接用一个常数就可以获得很好的效果。
improved DDPM
- DDPM只学习了均值,在improved DDPM中还学习了方差
- improved DDPM还修改了添加噪声的schedule,从线性的schedule改为了余弦schedule
- 大模型
Diffusion beats GAN:
- 进一步加大模型
- adaptive group normalization:根据步数t做自适应归一化
- classifier guidance引导模型进行采样和生成:使用一个额外训练的分类器(比如在加噪的imagenet上训练),输入$x_t$图像,做一个交叉熵损失获得梯度,利用梯度引导U-Net,使生成的图像要看起来更像某一类物体。
- 后续工作也有使用其他guidance指导信号如CLIP,图像(图像重建做像素级引导/图像风格引导(使用gram matrix)),文本,目标函数变为$P(x_{t-1}|x_t)=||\varepsilon-f_{\varepsilon}(x_t,t,y)||$,y代表condition,也就是上述的引导条件。但是这些方式都有一个共同的缺陷,都用了另外一个额外的模型去做引导,额外的计算量比较多;引导函数和扩散模型分别进行训练,不利于进一步扩增模型规模。
GLIDE(classifer-free guidance):
- 不用额外的模型进行引导:NIPS2021 Classifier-Free Diffusion Guidance提出了一个等价的结构替换了外部的classifier,从而可以直接使用一个扩散模型来做条件生成任务。模型训练时会生成两个输出,一个是在有conditional(随机高斯噪声+引导信息的embedding)的输出和unconditional采样输入时的输出,用这两个输出的差值来引导模型。
- classifer-free guidance的缺点:对于不同的引导类型,都需要重新训练扩散模型,且训练成本大(需要生成两个输出)
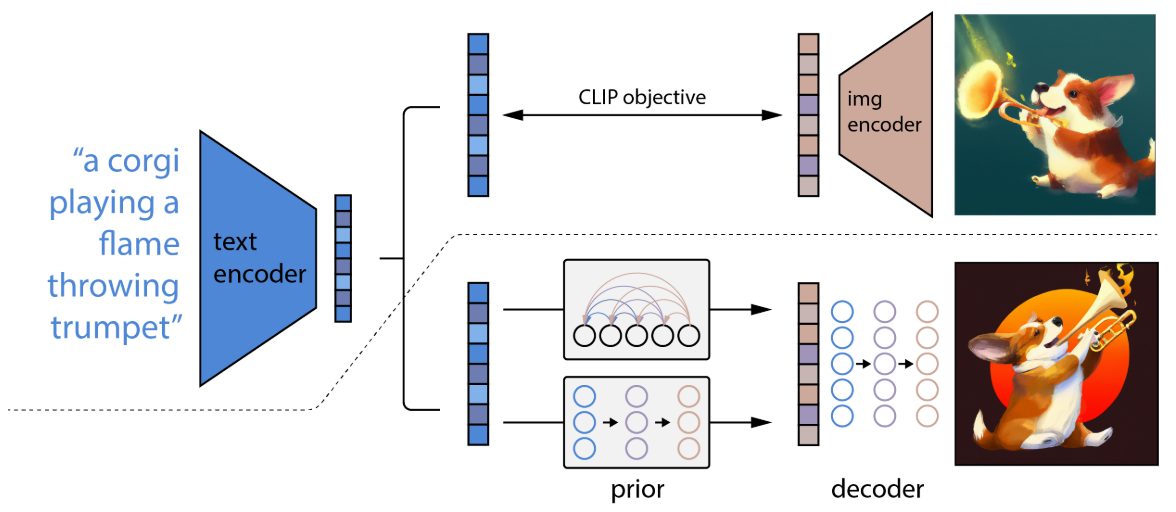
DALL·E 2 (unCLIP)
虚线上方是CLIP模型,模型是冻结的,将文本输入到文本编码器可以得到一对一的文本特征(因为文本编码器是冻结的)。使用两阶段的方式来生成图像:
- prior:利用一个自回归或者扩散模型预测一个图像特征,也就是下图中prior,训练prior所使用的gt就是CLIP的图像编码器产生的图像特征,这样就可以在没有文本对应图像的推理时,可以通过文本来预测一个图像特征(这个图像特征能很好的和文本对应,同时可以用于生成图像)
- decoder:利用prior生成的图像特征来生成图像,decoder仍然使用扩散模型。
这样一个显示的生成图像特征的过程可以获得更好的效果
Stable Diffusion (Latent Diffusion Models)
High-Resolution Image Synthesis with Latent Diffusion Models
Stable diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。
Motivation
Diffusion model相比GAN可以取得更好的图片生成效果,然而该模型是一种自回归模型,需要反复迭代计算,因此训练和推理代价都很高。论文提出一种在潜在表示空间(latent space)上进行diffusion过程的方法,从而能够大大减少计算复杂度,同时也能达到十分不错的图片生成效果。
Methodology
为了减小普通扩散模型在训练过程中的计算量,LDM将训练分成了两个阶段。第一个阶段训练一个AutoEncoder(包括一个encoder和decoder ,即图中的$\mathbf{\varepsilon}$和$D$)。第二阶段则是基于潜在表示训练扩散模型。有了自编码器,我们就可以利用encoder对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后我们再用解码器恢复到原始像素空间即可,论文将这个方法称之为感知压缩(Perceptual Compression)。本质上是将高维特征压缩,然后在低维空间中进行操作,大大减小了计算量。
在潜在表示空间上做diffusion操作其主要过程和标准的扩散模型没有太大的区别,所用到的扩散模型的具体实现为 time-conditional UNet。不同的是,LDM为diffusion操作引入了条件机制(Conditioning Mechanisms),通过cross-attention的方式来实现多模态训练,使得条件图片生成任务也可以实现。
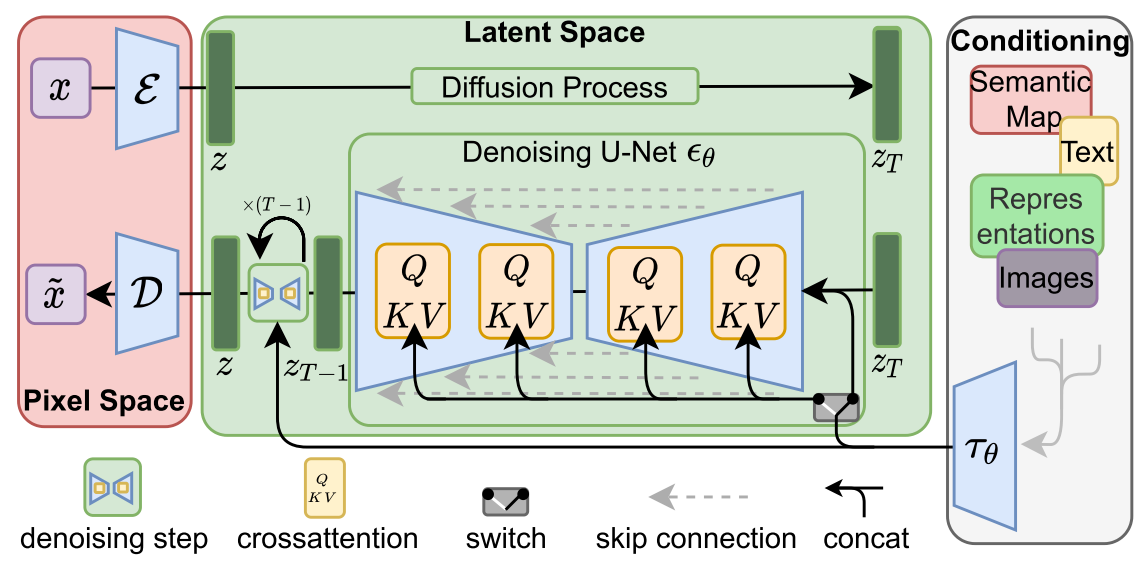
条件机制(Conditioning Mechanisms)
用于进行条件图像生成。LDM通过在UNet主干网络上增加cross-attention机制来控制图像的合成。对于不同模态的condition $y$,LDM引入一个领域专用编码器(domain specific encoder)$\tau_{\theta}$来对$y$进行编码,将$y$映射为一个中间表示$\tau_{\theta}(y)$,最终模型就可以通过一个cross-attention层映射将控制信息融入到UNet的中间层,cross-attention层的实现如下:
$\begin{array}{l}
\operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d}}\right) \cdot V, \text { with } \\
Q=W_{Q}^{(i)} \cdot \varphi_{i}\left(z_{t}\right), K=W_{K}^{(i)} \cdot \tau_{\theta}(y), V=W_{V}^{(i)} \cdot \tau_{\theta}(y)
\end{array}$
其中$\varphi_{i}\left(z_{t}\right)$是UNet的一个展平的中间表征。
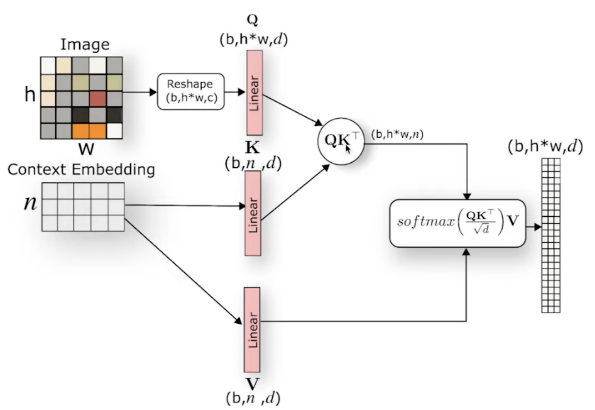
这里假设输入为图像和文本,通常将图像信息作为Q,文本信息作为K和V,因为我们希望根据文本序列中的信息来选择图像的局部区域,换句话说是以文本为条件控制图像的生成,所以通过注意力的形式来计算每个文本序列与图像不同区域之间的关联程度,即对于每个文本单词计算它与图像所有位置的相似度得分,然后归一化,并用它们加权求和得到最终加入条件控制的图像表示。过程如下:
对于两个不同模态的序列:图像生成Q,文本生成K、V;
两个不同模态的序列在最后一个维度上要相同
对于Q的每个位置,计算它与K中所有位置的关联程度,得到相似度矩阵;
将相似度矩阵归一化后得到权重矩阵,表示图像Q与文本K各个位置之间的关联程度;
然后再与V相乘进行加权求和,得到加入条件注意力后的新的图像表示,并且它与输入图像维度一致。
这样 cross-attention 就可以帮助模型学习不同序列之间的关联了,能更好地处理不同模态类型的数据。参考
将V设置为UNet特征和condition特征的区别?