A Simple Baseline for Open-Vocabulary Semantic Segmentation with Pre-trained Vision-language Model
Motivation
语义分割和CLIP模型是在不同的视觉粒度上执行的,语义分割在像素上进行,而CLIP在图像上进行。为了弥补处理粒度上的差异,本文没有采用基于但阶段FCN的框架,而是采用了两阶段语义分割框架,第一阶段提取mask proposals,第二阶段利用CLIP图像编码器对第一阶段生成的masked image crop进行open-vocabulary分类。
zero-shot & open-vocabulary
狭义的zero-shot learning关注于从已知类的标注数据中学习可迁移的特征表示来表示未知类。Zero-shot语义分割是打破有限类别瓶颈的一种尝试。然而,狭义的zero-shot语义分割通常只使用少量的标记分割数据,而拒绝使用任何其他数据/信息,从而导致性能较差。
open-vocabulary语义分割作为一种广义的zero-shot语义分割,更多地集中于建立一种可行的方法来分割任意类别,并且允许使用除分割数据之外的附加数据/信息。本文提出利用CLIP来完成。
Methodology
Pipeline
本文采用了two-stage的方式,首先通过Selective Search/Maskformer等方法得到class-agnostic的mask proposal,然后再利用CLIP对这个mask对应部分的图像进行分类。图中的pipeline是生成mask proposal之后,用mask和图像逐像素相乘并crop到$224\times 224$,然后输入进CLIP的image encoder得到image embedding,与prompt sentence经过text encoder编码得到的text embedding计算cosine similarity,从而得到整个mask图的分类,实现open-vocabulary semantic segmentation。
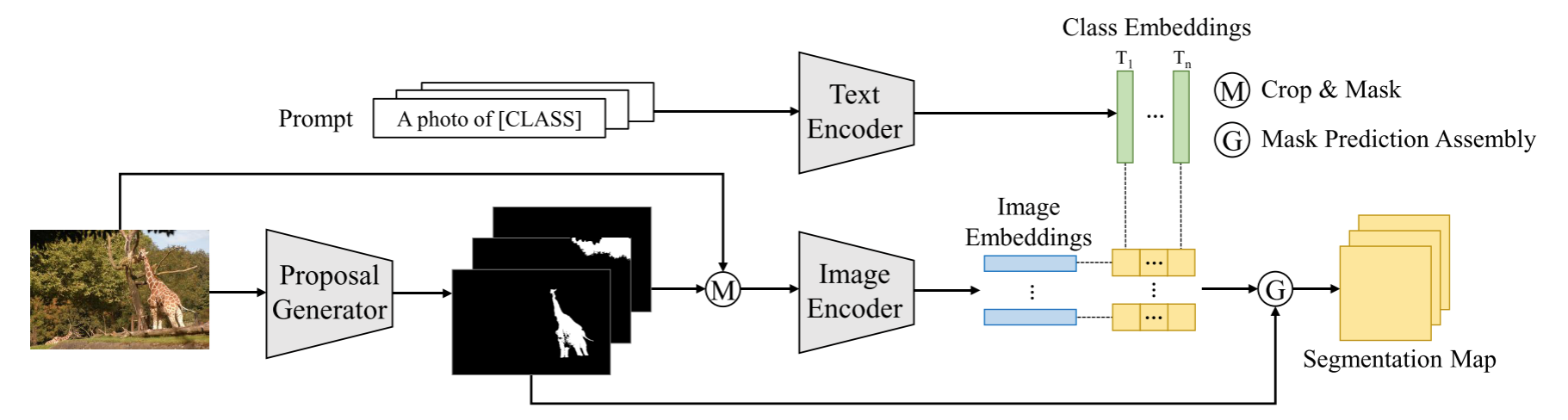
需要注意的是,本方法仍然是使用了ground-truth semantic segmentation annotations。在Zero-Shot Setting中,使用了可见类的mask标注,在Cross-Dataset Setting中则是在一个数据集上训练,在其他数据集上直接评估而不进行微调,比zero-shot更难,因为还需要解决不同数据集之间的域差距。
Mask Proposal Generation
- GPB-UCM:利用low-level特征如亮度、颜色、纹理和局部梯度来生成segments,segments可以很好的和物体轮廓进行对齐
- Selective Search:也可以生成segments,定位目标
- MaskFormer:MaskFormer(有监督)将语义分割任务分解为两个子任务:类无关mask生成和mask分类,这样的两阶段非常适合解决粒度跨度问题,第一阶段得到的mask proposal可以生成适合CLIP的图像粒度输入。实验证明在可见类上训练的MaskFormer可以在不可见类上产生高质量mask proposal,因此本文将MaskFormer作为默认的mask proposal generator。
Region Classification via CLIP
利用预训练的CLIP进行区域分两类的两种策略:
- 策略一:直接应用CLIP图像编码器对每个mask proposal进行分类。具体来说就是利用mask来擦除图像中的无用背景,并crop出前景区域,将crop缩放至$224\times 224$然后送进CLIP进行分类。但这一方式没有使用额外的训练过程来调整CLIP模型,可见类的训练数据没有被有效利用,导致可见类的推理性能较差。
- 策略二:为了利用可见类的训练数据,另一种方法是重新训练图像编码器(Image encoder + linear layer + softmax/sigmoid),但如果简单的在可见类上重新学习一个分类器,这一分类器仅能对可见类分类,对不可见类没有泛化能力。因此本文提出使用从预训练CLIP模型的text encoder生成的text embedding作为用于再训练图像编码器的固定分类器权重。
两个策略互相补充,策略一在可见类上效果较差,策略二则是在不可见类上的效果较差,因此作者进行了集成。对于给定的mask proposal $M^p$,crop出前景区域$A_{fg}=crop(M^p,I)$,通过CLIP的图像编码器$E_{vision}$和文本编码器$E_{text}$计算出前景区域的分类概率,就是计算图像特征和文本特征的相似度,并通过softmax转换为概率分布(文章中的括号位置是否存在问题):
$C_{i}\left(A_{f g}\right)=\frac{\exp \left(\operatorname{cosine}\left(E_{\text {vision }}\left(A_{f g}\right)\right), E_{\text {text }}\left(\mathcal{C}_{i}\right) / \tau\right)}{\sum_{i}^{\text { class }} \exp \left(\operatorname{cosine}\left(E_{\text {vision }}\left(A_{f g}\right), E_{\text {text }}\left(\mathcal{C}_{i}\right)\right) / \tau\right)}$
Mask Prediction Assembly
对于Semantic Mask中Overlap的处理